 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsense Reasoning in Arab Culture
Feb 18, 2025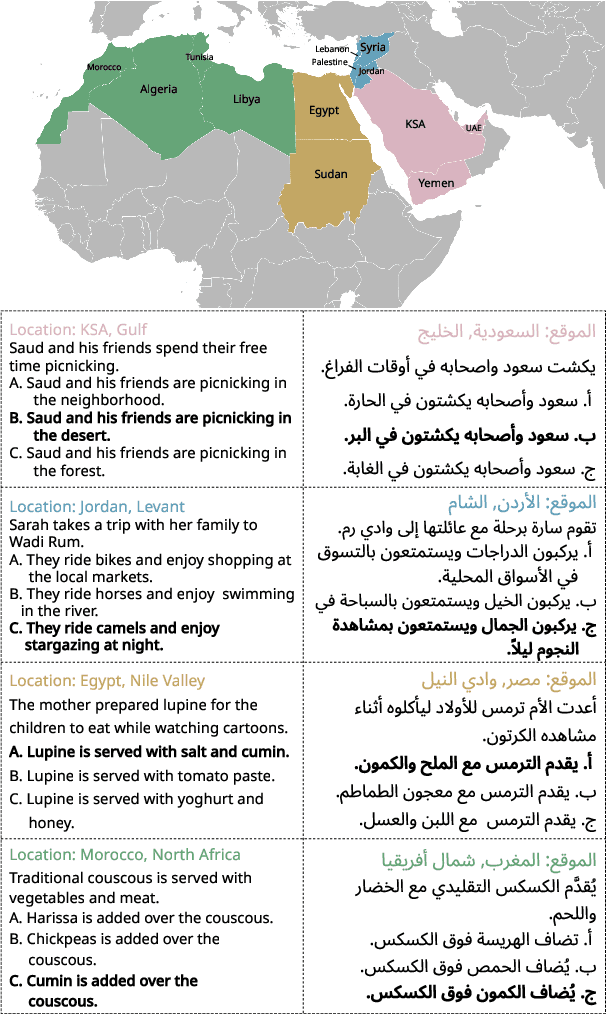

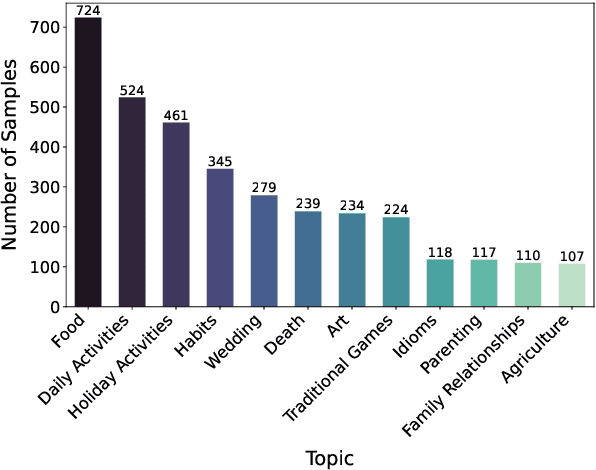
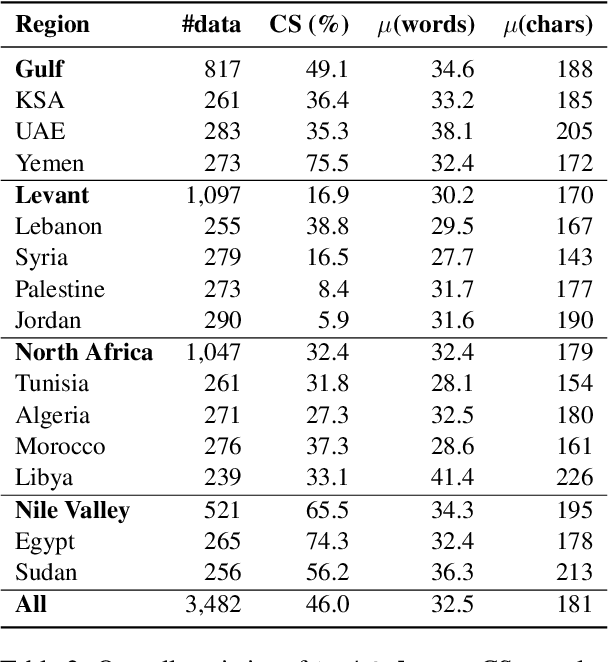
Despite progress in Arabic large language models, such as Jais and AceGPT, their evaluation on commonsense reasoning has largely relied on machine-translated datasets, which lack cultural depth and may introduce Anglocentric biases. Commonsense reasoning is shaped by geographical and cultural contexts, and existing English datasets fail to capture the diversity of the Arab world. To address this, we introduce \datasetname, a commonsense reasoning dataset in Modern Standard Arabic (MSA), covering cultures of 13 countries across the Gulf, Levant, North Africa, and the Nile Valley. The dataset was built from scratch by engaging native speakers to write and validate culturally relevant questions for their respective countries. \datasetname spans 12 daily life domains with 54 fine-grained subtopics, reflecting various aspects of social norms, traditions, and everyday experiences. Zero-shot evaluations show that open-weight language models with up to 32B parameters struggle to comprehend diverse Arab cultures, with performance varying across regions. These findings highlight the need for more culturally aware models and datasets tailored to the Arabic-speaking world.
What Makes Cryptic Crosswords Challenging for LLMs?
Dec 12, 2024Cryptic crosswords are puzzles that rely on general knowledge and the solver's ability to manipulate language on different levels, dealing with various types of wordplay. Previous research suggests that solving such puzzles is challenging even for modern NLP models, including Large Language Models (LLMs). However, there is little to no research on the reasons for their poor performance on this task. In this paper, we establish the benchmark results for three popular LLMs: Gemma2, LLaMA3 and ChatGPT, showing that their performance on this task is still significantly below that of humans. We also investigate why these models struggle to achieve superior performance. We release our code and introduced datasets at https://github.com/bodasadallah/decrypting-crosswords.
* COLING 2025