 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings Modalities in substructural logics: Applications at the interfaces of logic, language and computation
Aug 01, 2023By calling into question the implicit structural rules that are taken for granted in classical logic, substructural logics have brought to the fore new forms of reasoning with applications in many interdisciplinary areas of interest. Modalities, in the substructural setting, provide the tools to control and finetune the logical resource management. The focus of the workshop is on applications in the areas of interest to the ESSLLI community, in particular logical approaches to natural language syntax and semantics and the dynamics of reasoning. The workshop is held with the support of the Horizon 2020 MSCA-Rise project MOSAIC .
Structural Ambiguity and its Disambiguation in Language Model Based Parsers: the Case of Dutch Clause Relativization
May 24, 2023This paper addresses structural ambiguity in Dutch relative clauses. By investigating the task of disambiguation by grounding, we study how the presence of a prior sentence can resolve relative clause ambiguities. We apply this method to two parsing architectures in an attempt to demystify the parsing and language model components of two present-day neural parsers. Results show that a neurosymbolic parser, based on proof nets, is more open to data bias correction than an approach based on universal dependencies, although both setups suffer from a comparable initial data bias.
SPINDLE: Spinning Raw Text into Lambda Terms with Graph Attention
Feb 23, 2023



This paper describes SPINDLE - an open source Python module implementing an efficient and accurate parser for written Dutch that transforms raw text input to programs for meaning composition, expressed as {\lambda} terms. The parser integrates a number of breakthrough advances made in recent years. Its output consists of hi-res derivations of a multimodal type-logical grammar, capturing two orthogonal axes of syntax, namely deep function-argument structures and dependency relations. These are produced by three interdependent systems: a static type-checker asserting the well-formedness of grammatical analyses, a state-of-the-art, structurally-aware supertagger based on heterogeneous graph convolutions, and a massively parallel proof search component based on Sinkhorn iterations. Packed in the software are also handy utilities and extras for proof visualization and inference, intended to facilitate end-user utilization.
Proceedings End-to-End Compositional Models of Vector-Based Semantics
Aug 10, 2022The workshop End-to-End Compositional Models of Vector-Based Semantics was held at NUI Galway on 15 and 16 August 2022 as part of the 33rd European Summer School in Logic, Language and Information (ESSLLI 2022). The workshop was sponsored by the research project 'A composition calculus for vector-based semantic modelling with a localization for Dutch' (Dutch Research Council 360-89-070, 2017-2022). The workshop program was made up of two parts, the first part reporting on the results of the aforementioned project, the second part consisting of contributed papers on related approaches. The present volume collects the contributed papers and the abstracts of the invited talks.
Geometry-Aware Supertagging with Heterogeneous Dynamic Convolutions
Mar 23, 2022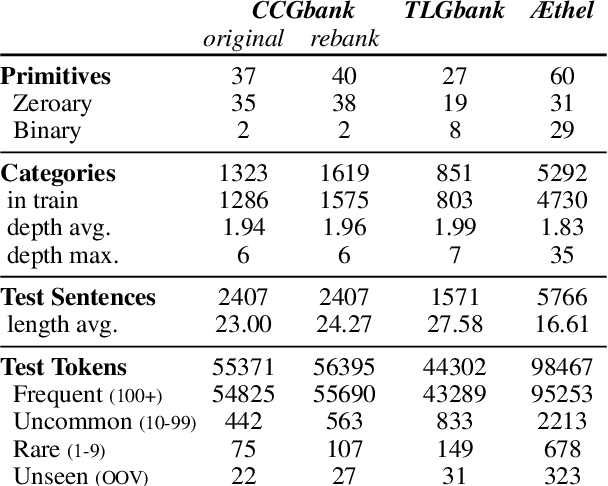
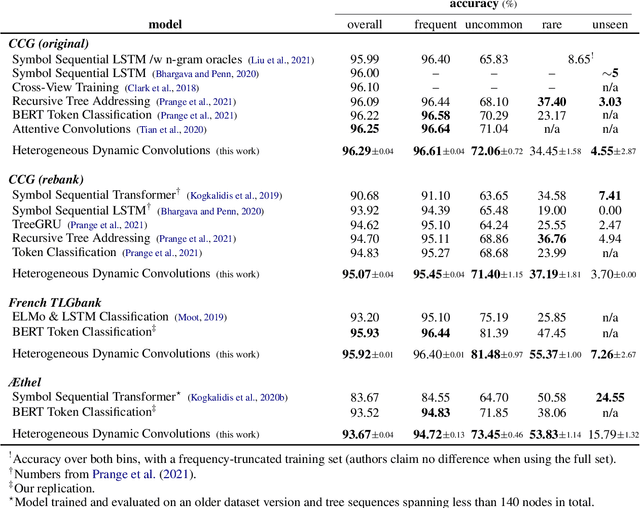
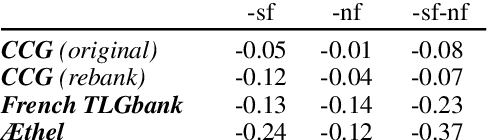
The syntactic categories of categorial grammar formalisms are structured units made of smaller, indivisible primitives, bound together by the underlying grammar's category formation rules. In the trending approach of constructive supertagging, neural models are increasingly made aware of the internal category structure, which in turn enables them to more reliably predict rare and out-of-vocabulary categories, with significant implications for grammars previously deemed too complex to find practical use. In this work, we revisit constructive supertagging from a graph-theoretic perspective, and propose a framework based on heterogeneous dynamic graph convolutions aimed at exploiting the distinctive structure of a supertagger's output space. We test our approach on a number of categorial grammar datasets spanning different languages and grammar formalisms, achieving substantial improvements over previous state of the art scores. Code will be made available at https://github.com/konstantinosKokos/dynamic-graph-supertagging
Improving BERT Pretraining with Syntactic Supervision
Apr 21, 2021Bidirectional masked Transformers have become the core theme in the current NLP landscape. Despite their impressive benchmarks, a recurring theme in recent research has been to question such models' capacity for syntactic generalization. In this work, we seek to address this question by adding a supervised, token-level supertagging objective to standard unsupervised pretraining, enabling the explicit incorporation of syntactic biases into the network's training dynamics. Our approach is straightforward to implement, induces a marginal computational overhead and is general enough to adapt to a variety of settings. We apply our methodology on Lassy Large, an automatically annotated corpus of written Dutch. Our experiments suggest that our syntax-aware model performs on par with established baselines, despite Lassy Large being one order of magnitude smaller than commonly used corpora.
SICKNL: A Dataset for Dutch Natural Language Inference
Jan 14, 2021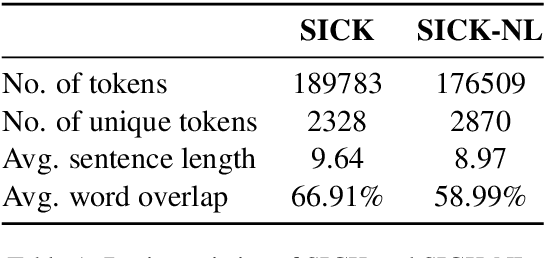

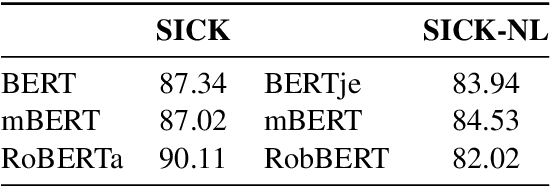
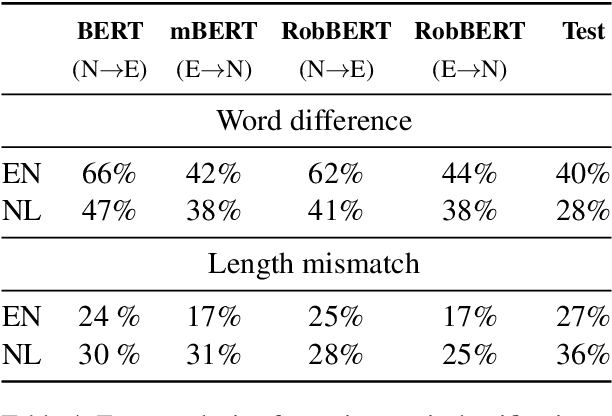
We present SICK-NL (read: signal), a dataset targeting Natural Language Inference in Dutch. SICK-NL is obtained by translating the SICK dataset of Marelli et al. (2014)from English into Dutch. Having a parallel inference dataset allows us to compare both monolingual and multilingual NLP models for English and Dutch on the two tasks. In the paper, we motivate and detail the translation process, perform a baseline evaluation on both the original SICK dataset and its Dutch incarnation SICK-NL, taking inspiration from Dutch skipgram embeddings and contextualised embedding models. In addition, we encapsulate two phenomena encountered in the translation to formulate stress tests and verify how well the Dutch models capture syntactic restructurings that do not affect semantics. Our main finding is all models perform worse on SICK-NL than on SICK, indicating that the Dutch dataset is more challenging than the English original. Results on the stress tests show that models don't fully capture word order freedom in Dutch, warranting future systematic studies.
Neural Proof Nets
Sep 26, 2020
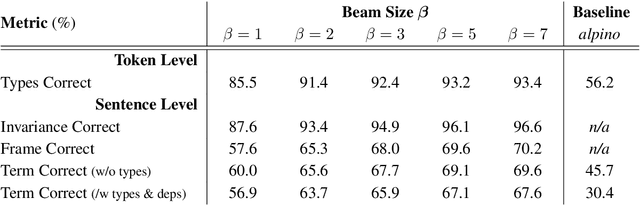


Linear logic and the linear {\lambda}-calculus have a long standing tradition in the study of natural language form and meaning. Among the proof calculi of linear logic, proof nets are of particular interest, offering an attractive geometric representation of derivations that is unburdened by the bureaucratic complications of conventional prooftheoretic formats. Building on recent advances in set-theoretic learning, we propose a neural variant of proof nets based on Sinkhorn networks, which allows us to translate parsing as the problem of extracting syntactic primitives and permuting them into alignment. Our methodology induces a batch-efficient, end-to-end differentiable architecture that actualizes a formally grounded yet highly efficient neuro-symbolic parser. We test our approach on {\AE}Thel, a dataset of type-logical derivations for written Dutch, where it manages to correctly transcribe raw text sentences into proofs and terms of the linear {\lambda}-calculus with an accuracy of as high as 70%.
A Frobenius Algebraic Analysis for Parasitic Gaps
May 12, 2020
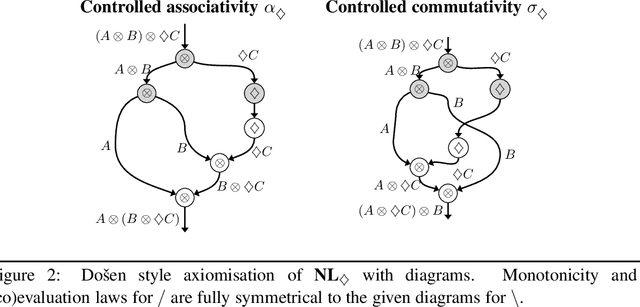
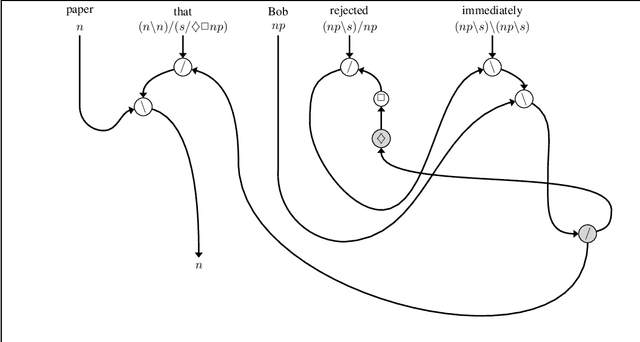
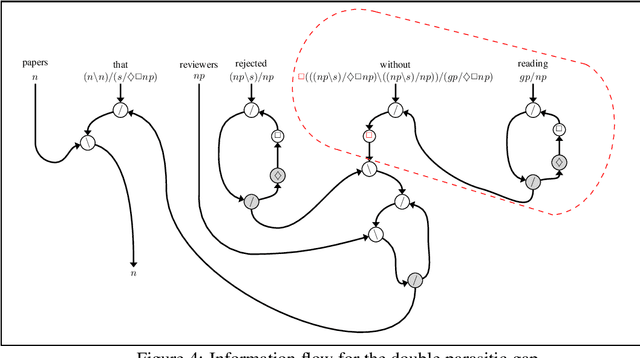
The interpretation of parasitic gaps is an ostensible case of non-linearity in natural language composition. Existing categorial analyses, both in the typelogical and in the combinatory traditions, rely on explicit forms of syntactic copying. We identify two types of parasitic gapping where the duplication of semantic content can be confined to the lexicon. Parasitic gaps in adjuncts are analysed as forms of generalized coordination with a polymorphic type schema for the head of the adjunct phrase. For parasitic gaps affecting arguments of the same predicate, the polymorphism is associated with the lexical item that introduces the primary gap. Our analysis is formulated in terms of Lambek calculus extended with structural control modalities. A compositional translation relates syntactic types and derivations to the interpreting compact closed category of finite dimensional vector spaces and linear maps with Frobenius algebras over it. When interpreted over the necessary semantic spaces, the Frobenius algebras provide the tools to model the proposed instances of lexical polymorphism.
ÆTHEL: Automatically Extracted Type-Logical Derivations for Dutch
Dec 29, 2019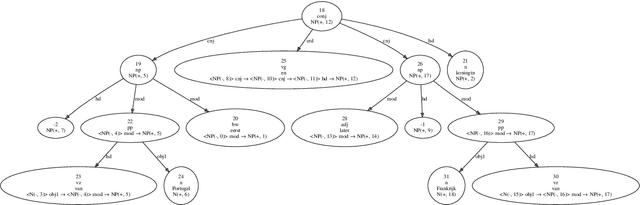
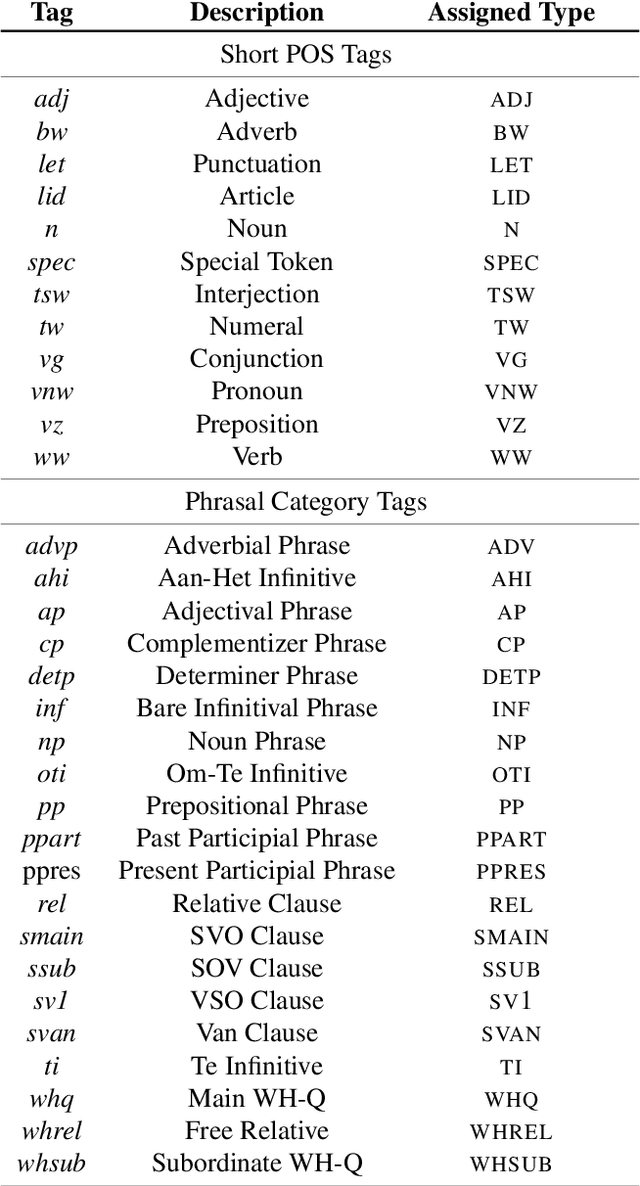

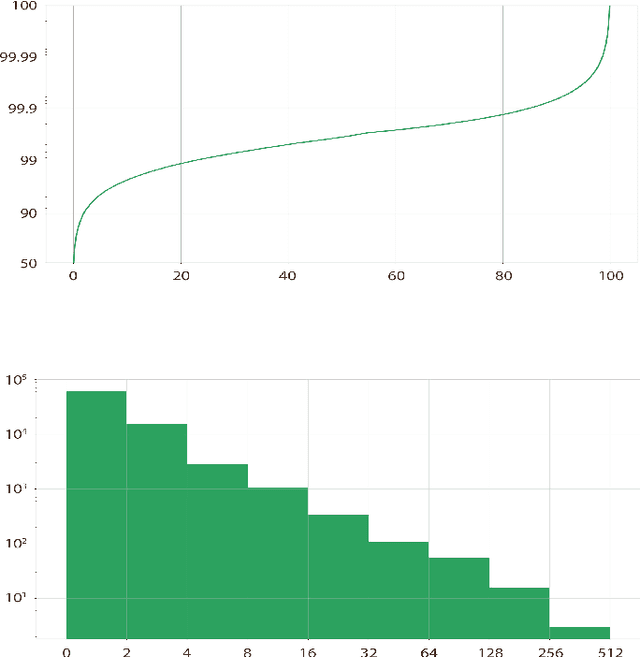
We present {\AE}THEL, a semantic compositionality dataset for written Dutch. {\AE}THEL consists of two parts. First, it contains a lexicon of supertags for about 900,000 words in context. The supertags correspond to types of the simply typed linear lambda-calculus, enhanced with dependency decorations that capture grammatical roles supplementary to function-argument structures. On the basis of these types, {\AE}THEL further provides 72,623 validated derivations, presented in four equivalent formats: natural-deduction and sequent-style proofs, linear logic proofnets and the associated programs (lambda terms) for meaning composition. {\AE}THEL's types and derivations are obtained by means of an extraction algorithm applied to the syntactic analyses of LASSY-Small, the gold standard corpus of written Dutch. We discuss the extraction algorithm and show how `virtual elements' in the original LASSY annotation of unbounded dependencies and coordination phenomena give rise to higher-order types. We suggest some example usecases highlighting the benefits of a type-driven approach at the syntax semantics interface. The following resources are open-sourced with {\AE}THEL: the lexical mappings between words and types, a subset of the dataset consisting of 8,569 semantic parses, and the Python code that implements the extraction algorithm.