 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Ambiguity and its Disambiguation in Language Model Based Parsers: the Case of Dutch Clause Relativization
May 24, 2023This paper addresses structural ambiguity in Dutch relative clauses. By investigating the task of disambiguation by grounding, we study how the presence of a prior sentence can resolve relative clause ambiguities. We apply this method to two parsing architectures in an attempt to demystify the parsing and language model components of two present-day neural parsers. Results show that a neurosymbolic parser, based on proof nets, is more open to data bias correction than an approach based on universal dependencies, although both setups suffer from a comparable initial data bias.
Proceedings End-to-End Compositional Models of Vector-Based Semantics
Aug 10, 2022The workshop End-to-End Compositional Models of Vector-Based Semantics was held at NUI Galway on 15 and 16 August 2022 as part of the 33rd European Summer School in Logic, Language and Information (ESSLLI 2022). The workshop was sponsored by the research project 'A composition calculus for vector-based semantic modelling with a localization for Dutch' (Dutch Research Council 360-89-070, 2017-2022). The workshop program was made up of two parts, the first part reporting on the results of the aforementioned project, the second part consisting of contributed papers on related approaches. The present volume collects the contributed papers and the abstracts of the invited talks.
Discontinuous Constituency and BERT: A Case Study of Dutch
Mar 08, 2022
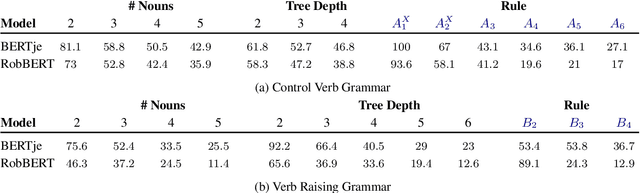
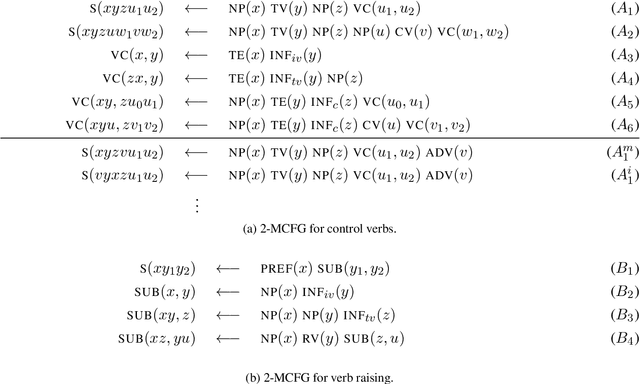
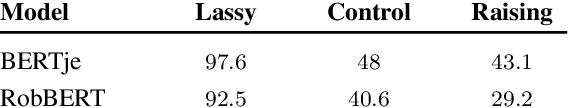
In this paper, we set out to quantify the syntactic capacity of BERT in the evaluation regime of non-context free patterns, as occurring in Dutch. We devise a test suite based on a mildly context-sensitive formalism, from which we derive grammars that capture the linguistic phenomena of control verb nesting and verb raising. The grammars, paired with a small lexicon, provide us with a large collection of naturalistic utterances, annotated with verb-subject pairings, that serve as the evaluation test bed for an attention-based span selection probe. Our results, backed by extensive analysis, suggest that the models investigated fail in the implicit acquisition of the dependencies examined.
Fuzzy Generalised Quantifiers for Natural Language in Categorical Compositional Distributional Semantics
Sep 23, 2021Recent work on compositional distributional models shows that bialgebras over finite dimensional vector spaces can be applied to treat generalised quantifiers for natural language. That technique requires one to construct the vector space over powersets, and therefore is computationally costly. In this paper, we overcome this problem by considering fuzzy versions of quantifiers along the lines of Zadeh, within the category of many valued relations. We show that this category is a concrete instantiation of the compositional distributional model. We show that the semantics obtained in this model is equivalent to the semantics of the fuzzy quantifiers of Zadeh. As a result, we are now able to treat fuzzy quantification without requiring a powerset construction.
* https://link.springer.com/chapter/10.1007/978-3-030-53654-1_6
Improving BERT Pretraining with Syntactic Supervision
Apr 21, 2021Bidirectional masked Transformers have become the core theme in the current NLP landscape. Despite their impressive benchmarks, a recurring theme in recent research has been to question such models' capacity for syntactic generalization. In this work, we seek to address this question by adding a supervised, token-level supertagging objective to standard unsupervised pretraining, enabling the explicit incorporation of syntactic biases into the network's training dynamics. Our approach is straightforward to implement, induces a marginal computational overhead and is general enough to adapt to a variety of settings. We apply our methodology on Lassy Large, an automatically annotated corpus of written Dutch. Our experiments suggest that our syntax-aware model performs on par with established baselines, despite Lassy Large being one order of magnitude smaller than commonly used corpora.
SICKNL: A Dataset for Dutch Natural Language Inference
Jan 14, 2021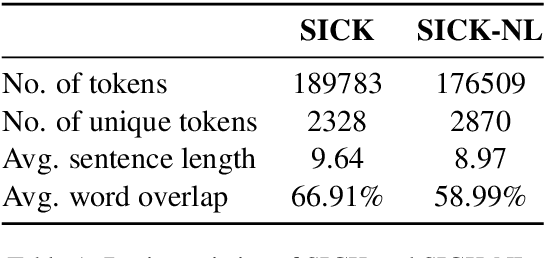

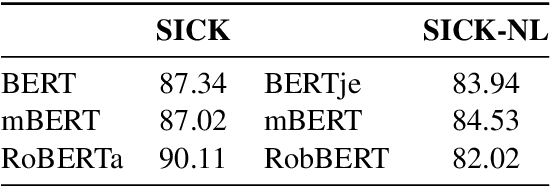
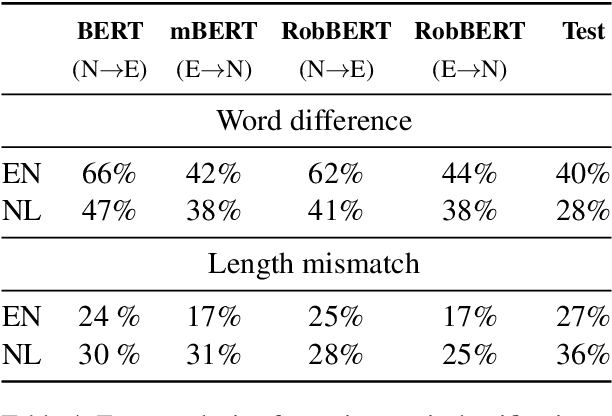
We present SICK-NL (read: signal), a dataset targeting Natural Language Inference in Dutch. SICK-NL is obtained by translating the SICK dataset of Marelli et al. (2014)from English into Dutch. Having a parallel inference dataset allows us to compare both monolingual and multilingual NLP models for English and Dutch on the two tasks. In the paper, we motivate and detail the translation process, perform a baseline evaluation on both the original SICK dataset and its Dutch incarnation SICK-NL, taking inspiration from Dutch skipgram embeddings and contextualised embedding models. In addition, we encapsulate two phenomena encountered in the translation to formulate stress tests and verify how well the Dutch models capture syntactic restructurings that do not affect semantics. Our main finding is all models perform worse on SICK-NL than on SICK, indicating that the Dutch dataset is more challenging than the English original. Results on the stress tests show that models don't fully capture word order freedom in Dutch, warranting future systematic studies.
A Frobenius Algebraic Analysis for Parasitic Gaps
May 12, 2020
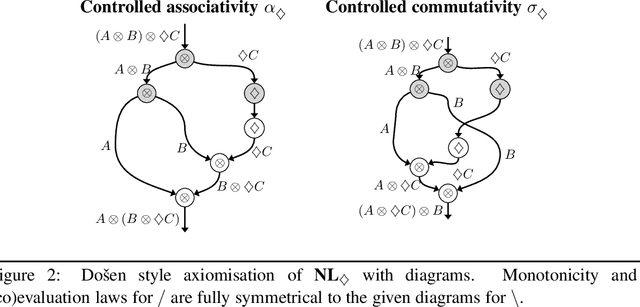
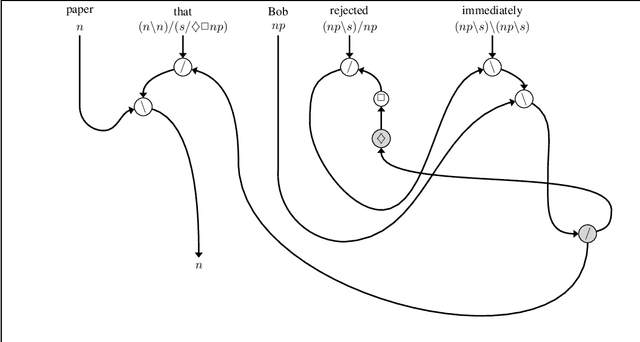
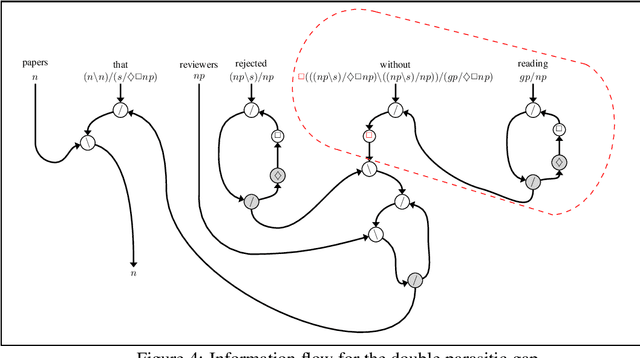
The interpretation of parasitic gaps is an ostensible case of non-linearity in natural language composition. Existing categorial analyses, both in the typelogical and in the combinatory traditions, rely on explicit forms of syntactic copying. We identify two types of parasitic gapping where the duplication of semantic content can be confined to the lexicon. Parasitic gaps in adjuncts are analysed as forms of generalized coordination with a polymorphic type schema for the head of the adjunct phrase. For parasitic gaps affecting arguments of the same predicate, the polymorphism is associated with the lexical item that introduces the primary gap. Our analysis is formulated in terms of Lambek calculus extended with structural control modalities. A compositional translation relates syntactic types and derivations to the interpreting compact closed category of finite dimensional vector spaces and linear maps with Frobenius algebras over it. When interpreted over the necessary semantic spaces, the Frobenius algebras provide the tools to model the proposed instances of lexical polymorphism.
Categorical Vector Space Semantics for Lambek Calculus with a Relevant Modality
May 10, 2020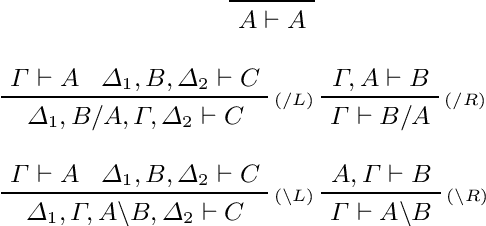

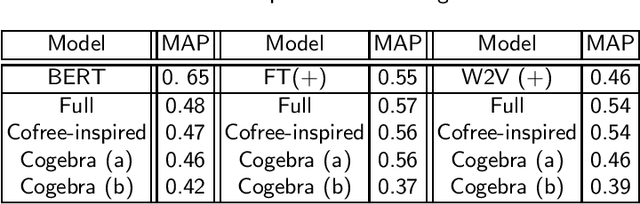
We develop a categorical compositional distributional semantics for Lambek Calculus with a Relevant Modality !L*, which has a limited edition of the contraction and permutation rules. The categorical part of the semantics is a monoidal biclosed category with a coalgebra modality, very similar to the structure of a Differential Category. We instantiate this category to finite dimensional vector spaces and linear maps via "quantisation" functors and work with three concrete interpretations of the coalgebra modality. We apply the model to construct categorical and concrete semantic interpretations for the motivating example of !L*: the derivation of a phrase with a parasitic gap. The effectiveness of the concrete interpretations are evaluated via a disambiguation task, on an extension of a sentence disambiguation dataset to parasitic gap phrases, using BERT, Word2Vec, and FastText vectors and Relational tensors.
A Typedriven Vector Semantics for Ellipsis with Anaphora using Lambek Calculus with Limited Contraction
May 05, 2019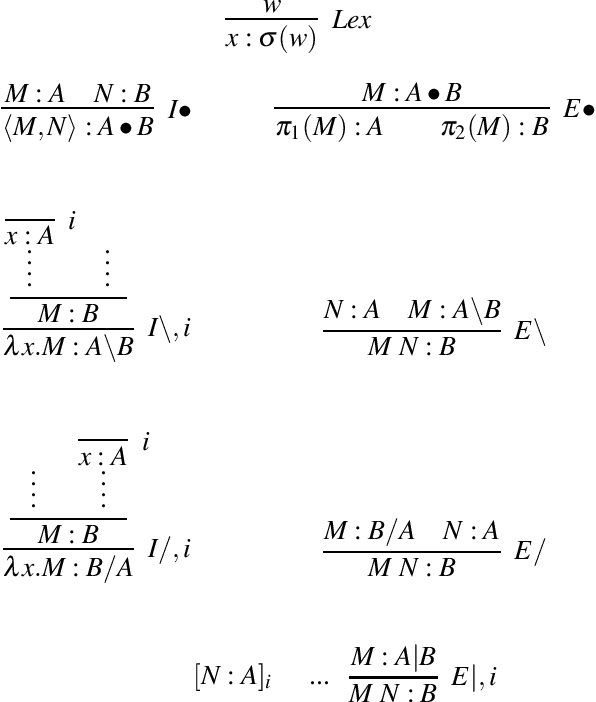


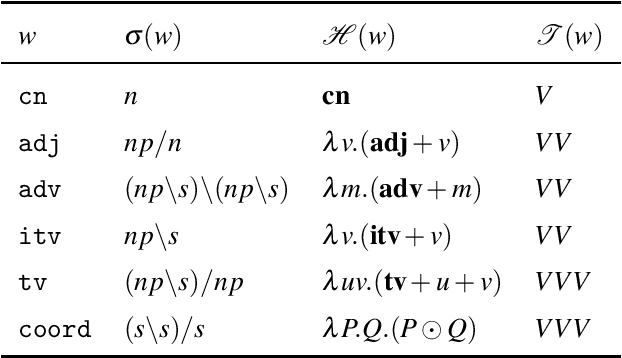
We develop a vector space semantics for verb phrase ellipsis with anaphora using type-driven compositional distributional semantics based on the Lambek calculus with limited contraction (LCC) of J\"ager (2006). Distributional semantics has a lot to say about the statistical collocation-based meanings of content words, but provides little guidance on how to treat function words. Formal semantics on the other hand, has powerful mechanisms for dealing with relative pronouns, coordinators, and the like. Type-driven compositional distributional semantics brings these two models together. We review previous compositional distributional models of relative pronouns, coordination and a restricted account of ellipsis in the DisCoCat framework of Coecke et al. (2010, 2013). We show how DisCoCat cannot deal with general forms of ellipsis, which rely on copying of information, and develop a novel way of connecting typelogical grammar to distributional semantics by assigning vector interpretable lambda terms to derivations of LCC in the style of Muskens & Sadrzadeh (2016). What follows is an account of (verb phrase) ellipsis in which word meanings can be copied: the meaning of a sentence is now a program with non-linear access to individual word embeddings. We present the theoretical setting, work out examples, and demonstrate our results on a toy distributional model motivated by data.
Classical Copying versus Quantum Entanglement in Natural Language: The Case of VP-ellipsis
Nov 08, 2018

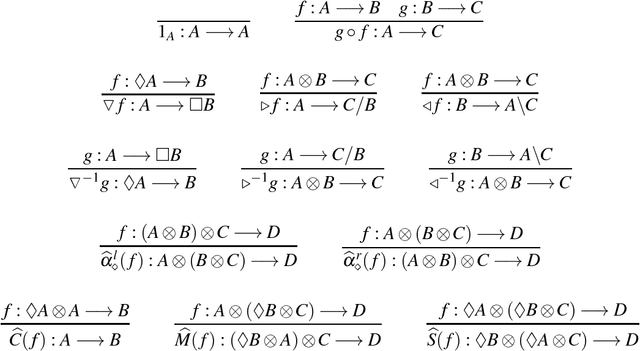
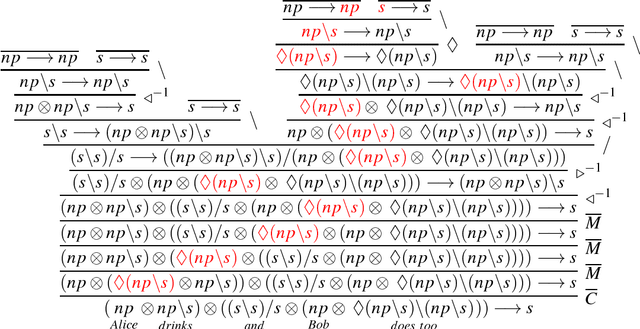
This paper compares classical copying and quantum entanglement in natural language by considering the case of verb phrase (VP) ellipsis. VP ellipsis is a non-linear linguistic phenomenon that requires the reuse of resources, making it the ideal test case for a comparative study of different copying behaviours in compositional models of natural language. Following the line of research in compositional distributional semantics set out by (Coecke et al., 2010) we develop an extension of the Lambek calculus which admits a controlled form of contraction to deal with the copying of linguistic resources. We then develop two different compositional models of distributional meaning for this calculus. In the first model, we follow the categorical approach of (Coecke et al., 2013) in which a functorial passage sends the proofs of the grammar to linear maps on vector spaces and we use Frobenius algebras to allow for copying. In the second case, we follow the more traditional approach that one finds in categorial grammars, whereby an intermediate step interprets proofs as non-linear lambda terms, using multiple variable occurrences that model classical copying. As a case study, we apply the models to derive different readings of ambiguous elliptical phrases and compare the analyses that each model provides.
* In Proceedings CAPNS 2018, arXiv:1811.02701