 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving BERT Pretraining with Syntactic Supervision
Apr 21, 2021Bidirectional masked Transformers have become the core theme in the current NLP landscape. Despite their impressive benchmarks, a recurring theme in recent research has been to question such models' capacity for syntactic generalization. In this work, we seek to address this question by adding a supervised, token-level supertagging objective to standard unsupervised pretraining, enabling the explicit incorporation of syntactic biases into the network's training dynamics. Our approach is straightforward to implement, induces a marginal computational overhead and is general enough to adapt to a variety of settings. We apply our methodology on Lassy Large, an automatically annotated corpus of written Dutch. Our experiments suggest that our syntax-aware model performs on par with established baselines, despite Lassy Large being one order of magnitude smaller than commonly used corpora.
Fighting the COVID-19 Infodemic with a Holistic BERT Ensemble
Apr 12, 2021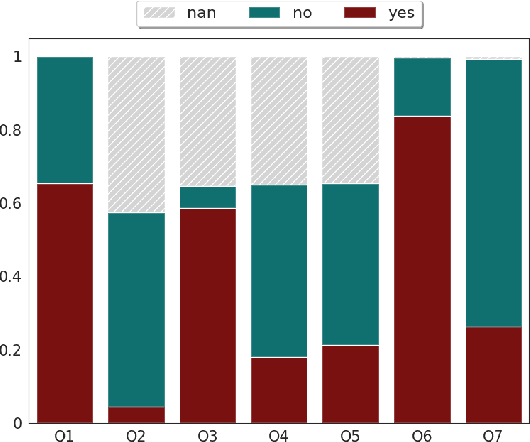
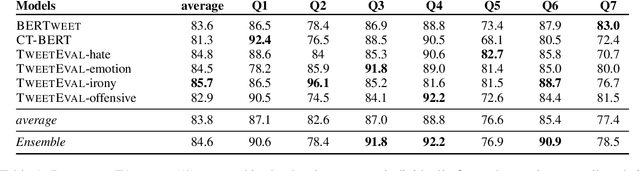
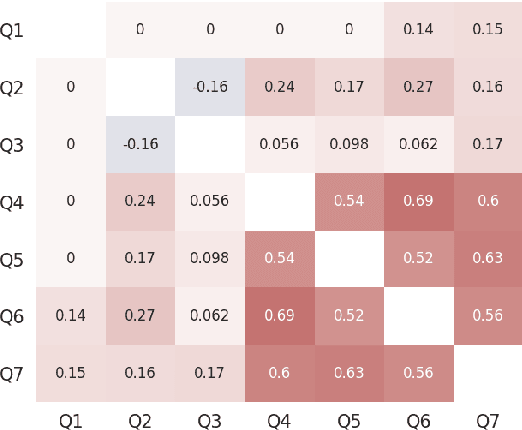
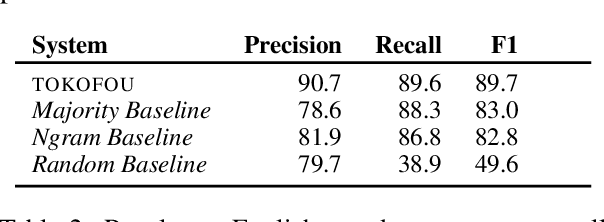
This paper describes the TOKOFOU system, an ensemble model for misinformation detection tasks based on six different transformer-based pre-trained encoders, implemented in the context of the COVID-19 Infodemic Shared Task for English. We fine tune each model on each of the task's questions and aggregate their prediction scores using a majority voting approach. TOKOFOU obtains an overall F1 score of 89.7%, ranking first.
Few-Shot Visual Grounding for Natural Human-Robot Interaction
Mar 31, 2021
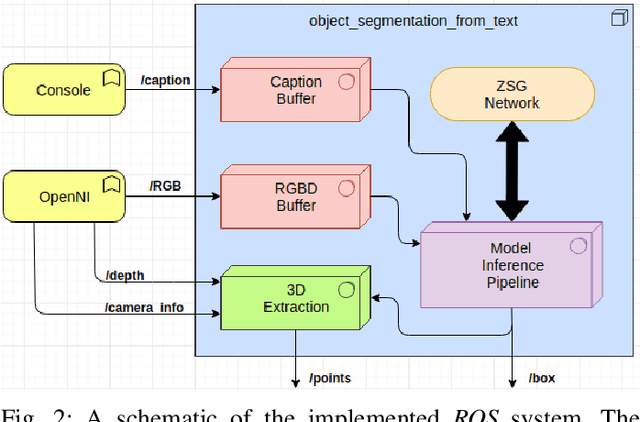


Natural Human-Robot Interaction (HRI) is one of the key components for service robots to be able to work in human-centric environments. In such dynamic environments, the robot needs to understand the intention of the user to accomplish a task successfully. Towards addressing this point, we propose a software architecture that segments a target object from a crowded scene, indicated verbally by a human user. At the core of our system, we employ a multi-modal deep neural network for visual grounding. Unlike most grounding methods that tackle the challenge using pre-trained object detectors via a two-stepped process, we develop a single stage zero-shot model that is able to provide predictions in unseen data. We evaluate the performance of the proposed model on real RGB-D data collected from public scene datasets. Experimental results showed that the proposed model performs well in terms of accuracy and speed, while showcasing robustness to variation in the natural language input.