 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Visual Grounding for Natural Human-Robot Interaction
Paper and Code
Mar 31, 2021
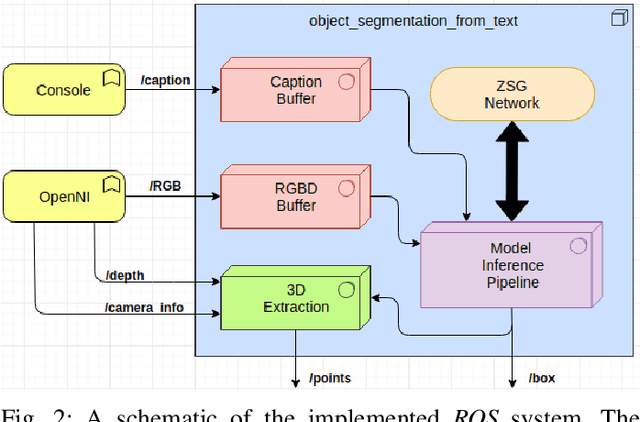


Natural Human-Robot Interaction (HRI) is one of the key components for service robots to be able to work in human-centric environments. In such dynamic environments, the robot needs to understand the intention of the user to accomplish a task successfully. Towards addressing this point, we propose a software architecture that segments a target object from a crowded scene, indicated verbally by a human user. At the core of our system, we employ a multi-modal deep neural network for visual grounding. Unlike most grounding methods that tackle the challenge using pre-trained object detectors via a two-stepped process, we develop a single stage zero-shot model that is able to provide predictions in unseen data. We evaluate the performance of the proposed model on real RGB-D data collected from public scene datasets. Experimental results showed that the proposed model performs well in terms of accuracy and speed, while showcasing robustness to variation in the natural language input.