 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM-MCVT: A Lightweight Multi-modal Multi-view Convolutional-Vision Transformer Approach for 3D Object Recognition
Apr 27, 2025



In human-centered environments such as restaurants, homes, and warehouses, robots often face challenges in accurately recognizing 3D objects. These challenges stem from the complexity and variability of these environments, including diverse object shapes. In this paper, we propose a novel Lightweight Multi-modal Multi-view Convolutional-Vision Transformer network (LM-MCVT) to enhance 3D object recognition in robotic applications. Our approach leverages the Globally Entropy-based Embeddings Fusion (GEEF) method to integrate multi-views efficiently. The LM-MCVT architecture incorporates pre- and mid-level convolutional encoders and local and global transformers to enhance feature extraction and recognition accuracy. We evaluate our method on the synthetic ModelNet40 dataset and achieve a recognition accuracy of 95.6% using a four-view setup, surpassing existing state-of-the-art methods. To further validate its effectiveness, we conduct 5-fold cross-validation on the real-world OmniObject3D dataset using the same configuration. Results consistently show superior performance, demonstrating the method's robustness in 3D object recognition across synthetic and real-world 3D data.
Learning Dual-Arm Coordination for Grasping Large Flat Objects
Apr 04, 2025



Grasping large flat objects, such as books or keyboards lying horizontally, presents significant challenges for single-arm robotic systems, often requiring extra actions like pushing objects against walls or moving them to the edge of a surface to facilitate grasping. In contrast, dual-arm manipulation, inspired by human dexterity, offers a more refined solution by directly coordinating both arms to lift and grasp the object without the need for complex repositioning. In this paper, we propose a model-free deep reinforcement learning (DRL) framework to enable dual-arm coordination for grasping large flat objects. We utilize a large-scale grasp pose detection model as a backbone to extract high-dimensional features from input images, which are then used as the state representation in a reinforcement learning (RL) model. A CNN-based Proximal Policy Optimization (PPO) algorithm with shared Actor-Critic layers is employed to learn coordinated dual-arm grasp actions. The system is trained and tested in Isaac Gym and deployed to real robots. Experimental results demonstrate that our policy can effectively grasp large flat objects without requiring additional maneuvers. Furthermore, the policy exhibits strong generalization capabilities, successfully handling unseen objects. Importantly, it can be directly transferred to real robots without fine-tuning, consistently outperforming baseline methods.
Enhanced View Planning for Robotic Harvesting: Tackling Occlusions with Imitation Learning
Mar 13, 2025



In agricultural automation, inherent occlusion presents a major challenge for robotic harvesting. We propose a novel imitation learning-based viewpoint planning approach to actively adjust camera viewpoint and capture unobstructed images of the target crop. Traditional viewpoint planners and existing learning-based methods, depend on manually designed evaluation metrics or reward functions, often struggle to generalize to complex, unseen scenarios. Our method employs the Action Chunking with Transformer (ACT) algorithm to learn effective camera motion policies from expert demonstrations. This enables continuous six-degree-of-freedom (6-DoF) viewpoint adjustments that are smoother, more precise and reveal occluded targets. Extensive experiments in both simulated and real-world environments, featuring agricultural scenarios and a 6-DoF robot arm equipped with an RGB-D camera, demonstrate our method's superior success rate and efficiency, especially in complex occlusion conditions, as well as its ability to generalize across different crops without reprogramming. This study advances robotic harvesting by providing a practical "learn from demonstration" (LfD) solution to occlusion challenges, ultimately enhancing autonomous harvesting performance and productivity.
Learning Dual-Arm Push and Grasp Synergy in Dense Clutter
Dec 05, 2024



Robotic grasping in densely cluttered environments is challenging due to scarce collision-free grasp affordances. Non-prehensile actions can increase feasible grasps in cluttered environments, but most research focuses on single-arm rather than dual-arm manipulation. Policies from single-arm systems fail to fully leverage the advantages of dual-arm coordination. We propose a target-oriented hierarchical deep reinforcement learning (DRL) framework that learns dual-arm push-grasp synergy for grasping objects to enhance dexterous manipulation in dense clutter. Our framework maps visual observations to actions via a pre-trained deep learning backbone and a novel CNN-based DRL model, trained with Proximal Policy Optimization (PPO), to develop a dual-arm push-grasp strategy. The backbone enhances feature mapping in densely cluttered environments. A novel fuzzy-based reward function is introduced to accelerate efficient strategy learning. Our system is developed and trained in Isaac Gym and then tested in simulations and on a real robot. Experimental results show that our framework effectively maps visual data to dual push-grasp motions, enabling the dual-arm system to grasp target objects in complex environments. Compared to other methods, our approach generates 6-DoF grasp candidates and enables dual-arm push actions, mimicking human behavior. Results show that our method efficiently completes tasks in densely cluttered environments. https://sites.google.com/view/pg4da/home
ManiSkill-ViTac 2025: Challenge on Manipulation Skill Learning With Vision and Tactile Sensing
Nov 19, 2024This article introduces the ManiSkill-ViTac Challenge 2025, which focuses on learning contact-rich manipulation skills using both tactile and visual sensing. Expanding upon the 2024 challenge, ManiSkill-ViTac 2025 includes 3 independent tracks: tactile manipulation, tactile-vision fusion manipulation, and tactile sensor structure design. The challenge aims to push the boundaries of robotic manipulation skills, emphasizing the integration of tactile and visual data to enhance performance in complex, real-world tasks. Participants will be evaluated using standardized metrics across both simulated and real-world environments, spurring innovations in sensor design and significantly advancing the field of vision-tactile fusion in robotics.
VLN-Game: Vision-Language Equilibrium Search for Zero-Shot Semantic Navigation
Nov 18, 2024Following human instructions to explore and search for a specified target in an unfamiliar environment is a crucial skill for mobile service robots. Most of the previous works on object goal navigation have typically focused on a single input modality as the target, which may lead to limited consideration of language descriptions containing detailed attributes and spatial relationships. To address this limitation, we propose VLN-Game, a novel zero-shot framework for visual target navigation that can process object names and descriptive language targets effectively. To be more precise, our approach constructs a 3D object-centric spatial map by integrating pre-trained visual-language features with a 3D reconstruction of the physical environment. Then, the framework identifies the most promising areas to explore in search of potential target candidates. A game-theoretic vision language model is employed to determine which target best matches the given language description. Experiments conducted on the Habitat-Matterport 3D (HM3D) dataset demonstrate that the proposed framework achieves state-of-the-art performance in both object goal navigation and language-based navigation tasks. Moreover, we show that VLN-Game can be easily deployed on real-world robots. The success of VLN-Game highlights the promising potential of using game-theoretic methods with compact vision-language models to advance decision-making capabilities in robotic systems. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/vln-game.
PANav: Toward Privacy-Aware Robot Navigation via Vision-Language Models
Oct 05, 2024



Navigating robots discreetly in human work environments while considering the possible privacy implications of robotic tasks presents significant challenges. Such scenarios are increasingly common, for instance, when robots transport sensitive objects that demand high levels of privacy in spaces crowded with human activities. While extensive research has been conducted on robotic path planning and social awareness, current robotic systems still lack the functionality of privacy-aware navigation in public environments. To address this, we propose a new framework for mobile robot navigation that leverages vision-language models to incorporate privacy awareness into adaptive path planning. Specifically, all potential paths from the starting point to the destination are generated using the A* algorithm. Concurrently, the vision-language model is used to infer the optimal path for privacy-awareness, given the environmental layout and the navigational instruction. This approach aims to minimize the robot's exposure to human activities and preserve the privacy of the robot and its surroundings. Experimental results on the S3DIS dataset demonstrate that our framework significantly enhances mobile robots' privacy awareness of navigation in human-shared public environments. Furthermore, we demonstrate the practical applicability of our framework by successfully navigating a robotic platform through real-world office environments. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/privacy-aware-nav.
HMT-Grasp: A Hybrid Mamba-Transformer Approach for Robot Grasping in Cluttered Environments
Oct 04, 2024



Robot grasping, whether handling isolated objects, cluttered items, or stacked objects, plays a critical role in industrial and service applications. However, current visual grasp detection methods based on Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) struggle to adapt across various grasping scenarios due to the imbalance between local and global feature extraction. In this paper, we propose a novel hybrid Mamba-Transformer approach to address these challenges. Our method improves robotic visual grasping by effectively capturing both global and local information through the integration of Vision Mamba and parallel convolutional-transformer blocks. This hybrid architecture significantly improves adaptability, precision, and flexibility across various robotic tasks. To ensure a fair evaluation, we conducted extensive experiments on the Cornell, Jacquard, and OCID-Grasp datasets, ranging from simple to complex scenarios. Additionally, we performed both simulated and real-world robotic experiments. The results demonstrate that our method not only surpasses state-of-the-art techniques on standard grasping datasets but also delivers strong performance in both simulation and real-world robot applications.
Single-Shot 6DoF Pose and 3D Size Estimation for Robotic Strawberry Harvesting
Oct 03, 2024In this study, we introduce a deep-learning approach for determining both the 6DoF pose and 3D size of strawberries, aiming to significantly augment robotic harvesting efficiency. Our model was trained on a synthetic strawberry dataset, which is automatically generated within the Ignition Gazebo simulator, with a specific focus on the inherent symmetry exhibited by strawberries. By leveraging domain randomization techniques, the model demonstrated exceptional performance, achieving an 84.77\% average precision (AP) of 3D Intersection over Union (IoU) scores on the simulated dataset. Empirical evaluations, conducted by testing our model on real-world datasets, underscored the model's viability for real-world strawberry harvesting scenarios, even though its training was based on synthetic data. The model also exhibited robust occlusion handling abilities, maintaining accurate detection capabilities even when strawberries were obscured by other strawberries or foliage. Additionally, the model showcased remarkably swift inference speeds, reaching up to 60 frames per second (FPS).
VITAL: Visual Teleoperation to Enhance Robot Learning through Human-in-the-Loop Corrections
Jul 30, 2024
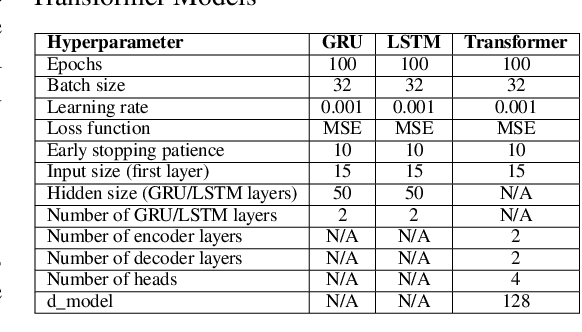
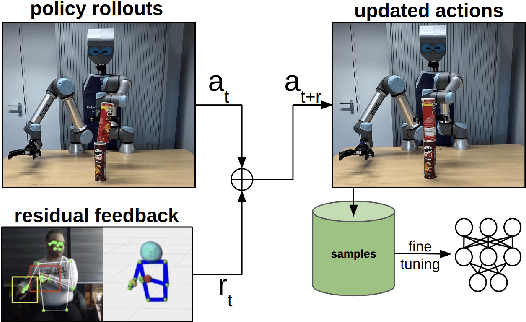
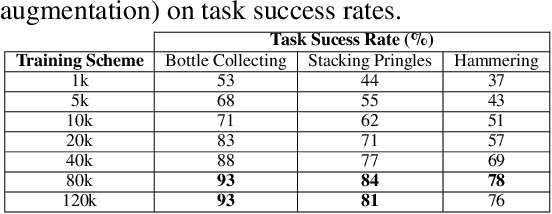
Imitation Learning (IL) has emerged as a powerful approach in robotics, allowing robots to acquire new skills by mimicking human actions. Despite its potential, the data collection process for IL remains a significant challenge due to the logistical difficulties and high costs associated with obtaining high-quality demonstrations. To address these issues, we propose a low-cost visual teleoperation system for bimanual manipulation tasks, called VITAL. Our approach leverages affordable hardware and visual processing techniques to collect demonstrations, which are then augmented to create extensive training datasets for imitation learning. We enhance the generalizability and robustness of the learned policies by utilizing both real and simulated environments and human-in-the-loop corrections. We evaluated our method through several rounds of experiments in simulated and real-robot settings, focusing on tasks of varying complexity, including bottle collecting, stacking objects, and hammering. Our experimental results validate the effectiveness of our approach in learning robust robot policies from simulated data, significantly improved by human-in-the-loop corrections and real-world data integration. Additionally, we demonstrate the framework's capability to generalize to new tasks, such as setting a drink tray, showcasing its adaptability and potential for handling a wide range of real-world bimanual manipulation tasks. A video of the experiments can be found at: https://youtu.be/YeVAMRqRe64?si=R179xDlEGc7nPu8i