 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness risk and its privacy-enabled solution in AI-driven robotic applications
Jan 13, 2026Complex decision-making by autonomous machines and algorithms could underpin the foundations of future society. Generative AI is emerging as a powerful engine for such transitions. However, we show that Generative AI-driven developments pose a critical pitfall: fairness concerns. In robotic applications, although intuitions about fairness are common, a precise and implementable definition that captures user utility and inherent data randomness is missing. Here we provide a utility-aware fairness metric for robotic decision making and analyze fairness jointly with user-data privacy, deriving conditions under which privacy budgets govern fairness metrics. This yields a unified framework that formalizes and quantifies fairness and its interplay with privacy, which is tested in a robot navigation task. In view of the fact that under legal requirements, most robotic systems will enforce user privacy, the approach shows surprisingly that such privacy budgets can be jointly used to meet fairness targets. Addressing fairness concerns in the creative combined consideration of privacy is a step towards ethical use of AI and strengthens trust in autonomous robots deployed in everyday environments.
VLN-Game: Vision-Language Equilibrium Search for Zero-Shot Semantic Navigation
Nov 18, 2024Following human instructions to explore and search for a specified target in an unfamiliar environment is a crucial skill for mobile service robots. Most of the previous works on object goal navigation have typically focused on a single input modality as the target, which may lead to limited consideration of language descriptions containing detailed attributes and spatial relationships. To address this limitation, we propose VLN-Game, a novel zero-shot framework for visual target navigation that can process object names and descriptive language targets effectively. To be more precise, our approach constructs a 3D object-centric spatial map by integrating pre-trained visual-language features with a 3D reconstruction of the physical environment. Then, the framework identifies the most promising areas to explore in search of potential target candidates. A game-theoretic vision language model is employed to determine which target best matches the given language description. Experiments conducted on the Habitat-Matterport 3D (HM3D) dataset demonstrate that the proposed framework achieves state-of-the-art performance in both object goal navigation and language-based navigation tasks. Moreover, we show that VLN-Game can be easily deployed on real-world robots. The success of VLN-Game highlights the promising potential of using game-theoretic methods with compact vision-language models to advance decision-making capabilities in robotic systems. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/vln-game.
PANav: Toward Privacy-Aware Robot Navigation via Vision-Language Models
Oct 05, 2024



Navigating robots discreetly in human work environments while considering the possible privacy implications of robotic tasks presents significant challenges. Such scenarios are increasingly common, for instance, when robots transport sensitive objects that demand high levels of privacy in spaces crowded with human activities. While extensive research has been conducted on robotic path planning and social awareness, current robotic systems still lack the functionality of privacy-aware navigation in public environments. To address this, we propose a new framework for mobile robot navigation that leverages vision-language models to incorporate privacy awareness into adaptive path planning. Specifically, all potential paths from the starting point to the destination are generated using the A* algorithm. Concurrently, the vision-language model is used to infer the optimal path for privacy-awareness, given the environmental layout and the navigational instruction. This approach aims to minimize the robot's exposure to human activities and preserve the privacy of the robot and its surroundings. Experimental results on the S3DIS dataset demonstrate that our framework significantly enhances mobile robots' privacy awareness of navigation in human-shared public environments. Furthermore, we demonstrate the practical applicability of our framework by successfully navigating a robotic platform through real-world office environments. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/privacy-aware-nav.
Co-NavGPT: Multi-Robot Cooperative Visual Semantic Navigation using Large Language Models
Oct 11, 2023



In advanced human-robot interaction tasks, visual target navigation is crucial for autonomous robots navigating unknown environments. While numerous approaches have been developed in the past, most are designed for single-robot operations, which often suffer from reduced efficiency and robustness due to environmental complexities. Furthermore, learning policies for multi-robot collaboration are resource-intensive. To address these challenges, we propose Co-NavGPT, an innovative framework that integrates Large Language Models (LLMs) as a global planner for multi-robot cooperative visual target navigation. Co-NavGPT encodes the explored environment data into prompts, enhancing LLMs' scene comprehension. It then assigns exploration frontiers to each robot for efficient target search. Experimental results on Habitat-Matterport 3D (HM3D) demonstrate that Co-NavGPT surpasses existing models in success rates and efficiency without any learning process, demonstrating the vast potential of LLMs in multi-robot collaboration domains. The supplementary video, prompts, and code can be accessed via the following link: \href{https://sites.google.com/view/co-navgpt}{https://sites.google.com/view/co-navgpt}.
L3MVN: Leveraging Large Language Models for Visual Target Navigation
Apr 11, 2023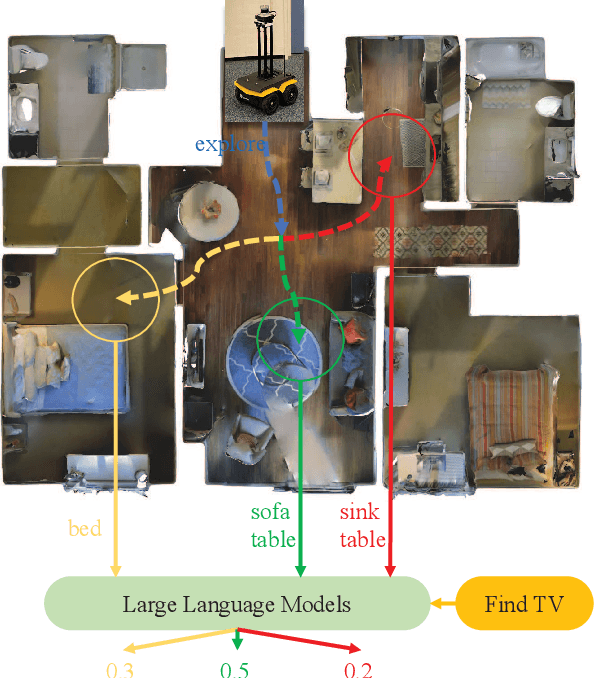
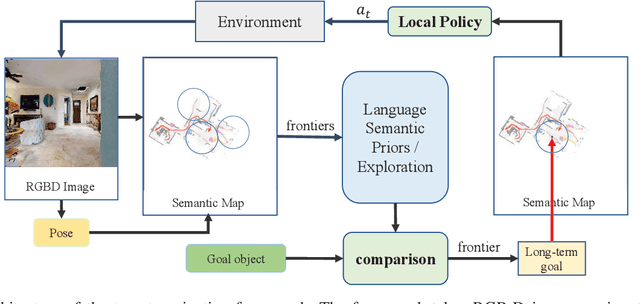
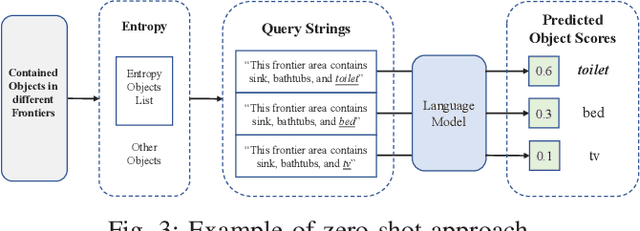
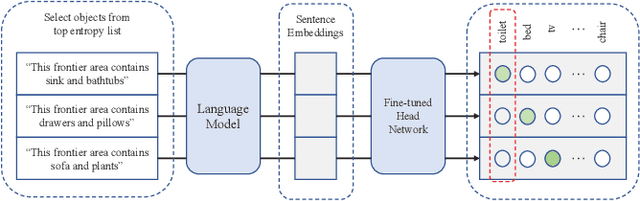
Visual target navigation in unknown environments is a crucial problem in robotics. Despite extensive investigation of classical and learning-based approaches in the past, robots lack common-sense knowledge about household objects and layouts. Prior state-of-the-art approaches to this task rely on learning the priors during the training and typically require significant expensive resources and time for learning. To address this, we propose a new framework for visual target navigation that leverages Large Language Models (LLM) to impart common sense for object searching. Specifically, we introduce two paradigms: (i) zero-shot and (ii) feed-forward approaches that use language to find the relevant frontier from the semantic map as a long-term goal and explore the environment efficiently. Our analysis demonstrates the notable zero-shot generalization and transfer capabilities from the use of language. Experiments on Gibson and Habitat-Matterport 3D (HM3D) demonstrate that the proposed framework significantly outperforms existing map-based methods in terms of success rate and generalization. Ablation analysis also indicates that the common-sense knowledge from the language model leads to more efficient semantic exploration. Finally, we provide a real robot experiment to verify the applicability of our framework in real-world scenarios. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/l3mvn.
Frontier Semantic Exploration for Visual Target Navigation
Apr 11, 2023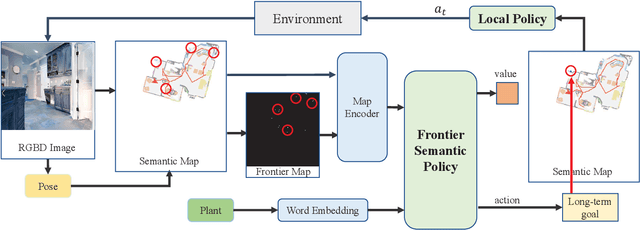
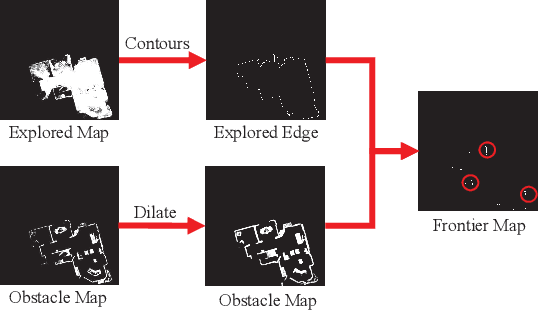
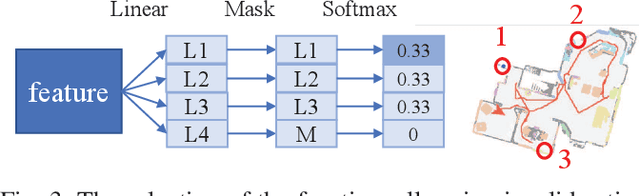

This work focuses on the problem of visual target navigation, which is very important for autonomous robots as it is closely related to high-level tasks. To find a special object in unknown environments, classical and learning-based approaches are fundamental components of navigation that have been investigated thoroughly in the past. However, due to the difficulty in the representation of complicated scenes and the learning of the navigation policy, previous methods are still not adequate, especially for large unknown scenes. Hence, we propose a novel framework for visual target navigation using the frontier semantic policy. In this proposed framework, the semantic map and the frontier map are built from the current observation of the environment. Using the features of the maps and object category, deep reinforcement learning enables to learn a frontier semantic policy which can be used to select a frontier cell as a long-term goal to explore the environment efficiently. Experiments on Gibson and Habitat-Matterport 3D (HM3D) demonstrate that the proposed framework significantly outperforms existing map-based methods in terms of success rate and efficiency. Ablation analysis also indicates that the proposed approach learns a more efficient exploration policy based on the frontiers. A demonstration is provided to verify the applicability of applying our model to real-world transfer. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/fsevn.