 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness risk and its privacy-enabled solution in AI-driven robotic applications
Jan 13, 2026Complex decision-making by autonomous machines and algorithms could underpin the foundations of future society. Generative AI is emerging as a powerful engine for such transitions. However, we show that Generative AI-driven developments pose a critical pitfall: fairness concerns. In robotic applications, although intuitions about fairness are common, a precise and implementable definition that captures user utility and inherent data randomness is missing. Here we provide a utility-aware fairness metric for robotic decision making and analyze fairness jointly with user-data privacy, deriving conditions under which privacy budgets govern fairness metrics. This yields a unified framework that formalizes and quantifies fairness and its interplay with privacy, which is tested in a robot navigation task. In view of the fact that under legal requirements, most robotic systems will enforce user privacy, the approach shows surprisingly that such privacy budgets can be jointly used to meet fairness targets. Addressing fairness concerns in the creative combined consideration of privacy is a step towards ethical use of AI and strengthens trust in autonomous robots deployed in everyday environments.
World In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
REASAN: Learning Reactive Safe Navigation for Legged Robots
Dec 10, 2025

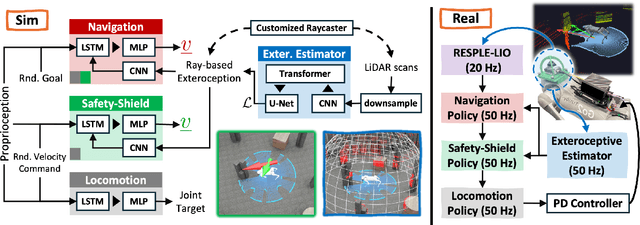
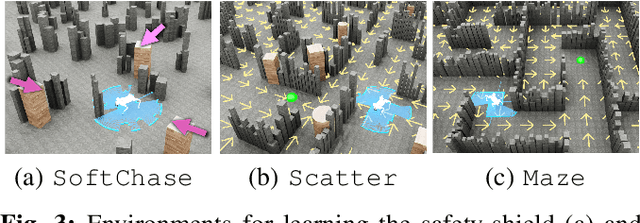
We present a novel modularized end-to-end framework for legged reactive navigation in complex dynamic environments using a single light detection and ranging (LiDAR) sensor. The system comprises four simulation-trained modules: three reinforcement-learning (RL) policies for locomotion, safety shielding, and navigation, and a transformer-based exteroceptive estimator that processes raw point-cloud inputs. This modular decomposition of complex legged motor-control tasks enables lightweight neural networks with simple architectures, trained using standard RL practices with targeted reward shaping and curriculum design, without reliance on heuristics or sophisticated policy-switching mechanisms. We conduct comprehensive ablations to validate our design choices and demonstrate improved robustness compared to existing approaches in challenging navigation tasks. The resulting reactive safe navigation (REASAN) system achieves fully onboard and real-time reactive navigation across both single- and multi-robot settings in complex environments. We release our training and deployment code at https://github.com/ASIG-X/REASAN.
Privacy protection under the exposure of systems' prior information
Nov 13, 2025

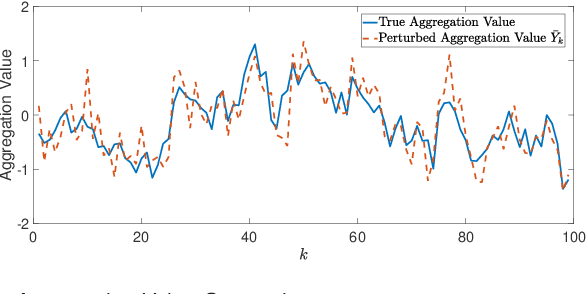
For systems whose states implicate sensitive information, their privacy is of great concern. While notions like differential privacy have been successfully introduced to dynamical systems, it is still unclear how a system's privacy can be properly protected when facing the challenging yet frequently-encountered scenario where an adversary possesses prior knowledge, e.g., the steady state, of the system. This paper presents a new systematic approach to protect the privacy of a discrete-time linear time-invariant system against adversaries knowledgeable of the system's prior information. We employ a tailored \emph{pointwise maximal leakage (PML) privacy} criterion. PML characterizes the worst-case privacy performance, which is sharply different from that of the better-known mutual-information privacy. We derive necessary and sufficient conditions for PML privacy and construct tractable design procedures. Furthermore, our analysis leads to insight into how PML privacy, differential privacy, and mutual-information privacy are related. We then revisit Kalman filters from the perspective of PML privacy and derive a lower bound on the steady-state estimation-error covariance in terms of the PML parameters. Finally, the derived results are illustrated in a case study of privacy protection for distributed sensing in smart buildings.
Equilibrium-Driven Smooth Separation and Navigation of Marsupial Robotic Systems
Jun 16, 2025In this paper, we propose an equilibrium-driven controller that enables a marsupial carrier-passenger robotic system to achieve smooth carrier-passenger separation and then to navigate the passenger robot toward a predetermined target point. Particularly, we design a potential gradient in the form of a cubic polynomial for the passenger's controller as a function of the carrier-passenger and carrier-target distances in the moving carrier's frame. This introduces multiple equilibrium points corresponding to the zero state of the error dynamic system during carrier-passenger separation. The change of equilibrium points is associated with the change in their attraction regions, enabling smooth carrier-passenger separation and afterwards seamless navigation toward the target. Finally, simulations demonstrate the effectiveness and adaptability of the proposed controller in environments containing obstacles.
High-order Regularization for Machine Learning and Learning-based Control
May 13, 2025The paper proposes a novel regularization procedure for machine learning. The proposed high-order regularization (HR) provides new insight into regularization, which is widely used to train a neural network that can be utilized to approximate the action-value function in general reinforcement learning problems. The proposed HR method ensures the provable convergence of the approximation algorithm, which makes the much-needed connection between regularization and explainable learning using neural networks. The proposed HR method theoretically demonstrates that regularization can be regarded as an approximation in terms of inverse mapping with explicitly calculable approximation error, and the $L_2$ regularization is a lower-order case of the proposed method. We provide lower and upper bounds for the error of the proposed HR solution, which helps build a reliable model. We also find that regularization with the proposed HR can be regarded as a contraction. We prove that the generalizability of neural networks can be maximized with a proper regularization matrix, and the proposed HR is applicable for neural networks with any mapping matrix. With the theoretical explanation of the extreme learning machine for neural network training and the proposed high-order regularization, one can better interpret the output of the neural network, thus leading to explainable learning. We present a case study based on regularized extreme learning neural networks to demonstrate the application of the proposed HR and give the corresponding incremental HR solution. We verify the performance of the proposed HR method by solving a classic control problem in reinforcement learning. The result demonstrates the superior performance of the method with significant enhancement in the generalizability of the neural network.
GenSwarm: Scalable Multi-Robot Code-Policy Generation and Deployment via Language Models
Mar 31, 2025The development of control policies for multi-robot systems traditionally follows a complex and labor-intensive process, often lacking the flexibility to adapt to dynamic tasks. This has motivated research on methods to automatically create control policies. However, these methods require iterative processes of manually crafting and refining objective functions, thereby prolonging the development cycle. This work introduces \textit{GenSwarm}, an end-to-end system that leverages large language models to automatically generate and deploy control policies for multi-robot tasks based on simple user instructions in natural language. As a multi-language-agent system, GenSwarm achieves zero-shot learning, enabling rapid adaptation to altered or unseen tasks. The white-box nature of the code policies ensures strong reproducibility and interpretability. With its scalable software and hardware architectures, GenSwarm supports efficient policy deployment on both simulated and real-world multi-robot systems, realizing an instruction-to-execution end-to-end functionality that could prove valuable for robotics specialists and non-specialists alike.The code of the proposed GenSwarm system is available online: https://github.com/WindyLab/GenSwarm.
Robust simultaneous UWB-anchor calibration and robot localization for emergency situations
Mar 28, 2025In this work, we propose a factor graph optimization (FGO) framework to simultaneously solve the calibration problem for Ultra-WideBand (UWB) anchors and the robot localization problem. Calibrating UWB anchors manually can be time-consuming and even impossible in emergencies or those situations without special calibration tools. Therefore, automatic estimation of the anchor positions becomes a necessity. The proposed method enables the creation of a soft sensor providing the position information of the anchors in a UWB network. This soft sensor requires only UWB and LiDAR measurements measured from a moving robot. The proposed FGO framework is suitable for the calibration of an extendable large UWB network. Moreover, the anchor calibration problem and robot localization problem can be solved simultaneously, which saves time for UWB network deployment. The proposed framework also helps to avoid artificial errors in the UWB-anchor position estimation and improves the accuracy and robustness of the robot-pose. The experimental results of the robot localization using LiDAR and a UWB network in a 3D environment are discussed, demonstrating the performance of the proposed method. More specifically, the anchor calibration problem with four anchors and the robot localization problem can be solved simultaneously and automatically within 30 seconds by the proposed framework. The supplementary video and codes can be accessed via https://github.com/LiuxhRobotAI/Simultaneous_calibration_localization.
VLN-Game: Vision-Language Equilibrium Search for Zero-Shot Semantic Navigation
Nov 18, 2024Following human instructions to explore and search for a specified target in an unfamiliar environment is a crucial skill for mobile service robots. Most of the previous works on object goal navigation have typically focused on a single input modality as the target, which may lead to limited consideration of language descriptions containing detailed attributes and spatial relationships. To address this limitation, we propose VLN-Game, a novel zero-shot framework for visual target navigation that can process object names and descriptive language targets effectively. To be more precise, our approach constructs a 3D object-centric spatial map by integrating pre-trained visual-language features with a 3D reconstruction of the physical environment. Then, the framework identifies the most promising areas to explore in search of potential target candidates. A game-theoretic vision language model is employed to determine which target best matches the given language description. Experiments conducted on the Habitat-Matterport 3D (HM3D) dataset demonstrate that the proposed framework achieves state-of-the-art performance in both object goal navigation and language-based navigation tasks. Moreover, we show that VLN-Game can be easily deployed on real-world robots. The success of VLN-Game highlights the promising potential of using game-theoretic methods with compact vision-language models to advance decision-making capabilities in robotic systems. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/vln-game.
PANav: Toward Privacy-Aware Robot Navigation via Vision-Language Models
Oct 05, 2024



Navigating robots discreetly in human work environments while considering the possible privacy implications of robotic tasks presents significant challenges. Such scenarios are increasingly common, for instance, when robots transport sensitive objects that demand high levels of privacy in spaces crowded with human activities. While extensive research has been conducted on robotic path planning and social awareness, current robotic systems still lack the functionality of privacy-aware navigation in public environments. To address this, we propose a new framework for mobile robot navigation that leverages vision-language models to incorporate privacy awareness into adaptive path planning. Specifically, all potential paths from the starting point to the destination are generated using the A* algorithm. Concurrently, the vision-language model is used to infer the optimal path for privacy-awareness, given the environmental layout and the navigational instruction. This approach aims to minimize the robot's exposure to human activities and preserve the privacy of the robot and its surroundings. Experimental results on the S3DIS dataset demonstrate that our framework significantly enhances mobile robots' privacy awareness of navigation in human-shared public environments. Furthermore, we demonstrate the practical applicability of our framework by successfully navigating a robotic platform through real-world office environments. The supplementary video and code can be accessed via the following link: https://sites.google.com/view/privacy-aware-nav.