 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxDistill: Improving Metagenomic Taxonomic Annotation via Distilled Genomic Foundation Models
May 22, 2026Metagenomic taxonomic annotation aims to identify the microbial origins of DNA fragments in environmental samples. Traditional methods that rely on sequence similarity are often constrained by the high microbial diversity and the incompleteness of reference databases, which has motivated the development of learning approaches such as Taxometer that perform post hoc correction to learn more informative metagenomic sequence representations. However, these methods typically rely on labels derived from similarity search tools during training, which inevitably introduces noise that can impair representation learning and degrade classification performance. To address this issue, we propose TaxDistill, a knowledge distillation framework for metagenomic classification. We introduce GenomeOcean, a 500M parameter genomic foundation model, as the teacher network to extract deep semantic features and generate soft labels based on confidence. By distilling this soft label information into a lightweight student network, TaxDistill effectively reduces the label noise introduced by initial retrieval tools. Comprehensive experiments on seven diverse CAMI2 datasets demonstrate that TaxDistill outperforms existing baselines in most scenarios. For instance, on the Gastrointestinal dataset, it improves the F1 score of MMseqs2 from 0.763 to 0.941, outperforming the Taxometer baseline. Overall, TaxDistill provides a reliable method for label correction in complex metagenomic analysis.
Enhanced View Planning for Robotic Harvesting: Tackling Occlusions with Imitation Learning
Mar 13, 2025



In agricultural automation, inherent occlusion presents a major challenge for robotic harvesting. We propose a novel imitation learning-based viewpoint planning approach to actively adjust camera viewpoint and capture unobstructed images of the target crop. Traditional viewpoint planners and existing learning-based methods, depend on manually designed evaluation metrics or reward functions, often struggle to generalize to complex, unseen scenarios. Our method employs the Action Chunking with Transformer (ACT) algorithm to learn effective camera motion policies from expert demonstrations. This enables continuous six-degree-of-freedom (6-DoF) viewpoint adjustments that are smoother, more precise and reveal occluded targets. Extensive experiments in both simulated and real-world environments, featuring agricultural scenarios and a 6-DoF robot arm equipped with an RGB-D camera, demonstrate our method's superior success rate and efficiency, especially in complex occlusion conditions, as well as its ability to generalize across different crops without reprogramming. This study advances robotic harvesting by providing a practical "learn from demonstration" (LfD) solution to occlusion challenges, ultimately enhancing autonomous harvesting performance and productivity.
Deep Joint CSI Estimation-Feedback-Precoding for MU-MIMO OFDM Systems
Mar 06, 2025As the number of antennas in frequency-division duplex (FDD) multiple-input multiple-output (MIMO) systems increases, acquiring channel state information (CSI) becomes increasingly challenging due to limited spectral resources and feedback overhead. In this paper, we propose an end-to-end network that conducts joint design with pilot design, CSI estimation, CSI feedback, and precoding design in the multi-user MIMO orthogonal frequency-division multiplexing (OFDM) scenario. Multiple communication modules are jointly designed and trained with a common optimization objective to prevent mismatches between modules and discrepancies between individual module objectives and the final system goal. Experimental results demonstrate that, under the same feedback and CE overheads, the proposed joint multi-module end-to-end network achieves a higher multi-user downlink spectral efficiency than traditional algorithms based on separate architecture and partially separated artificial intelligence-based network architectures under comparable channel quality. Furthermore, compared to conventional separate architecture, the proposed network architecture with joint architecture reduces the computational burden and model storage overhead at the UE side, facilitating the deployment of low-overhead multi-module joint architectures in practice. While slightly increasing storage requirements at the base station, it reduces computational complexity and precoding design delay, effectively reducing the effects of channel aging challenges.
Single-Shot 6DoF Pose and 3D Size Estimation for Robotic Strawberry Harvesting
Oct 03, 2024In this study, we introduce a deep-learning approach for determining both the 6DoF pose and 3D size of strawberries, aiming to significantly augment robotic harvesting efficiency. Our model was trained on a synthetic strawberry dataset, which is automatically generated within the Ignition Gazebo simulator, with a specific focus on the inherent symmetry exhibited by strawberries. By leveraging domain randomization techniques, the model demonstrated exceptional performance, achieving an 84.77\% average precision (AP) of 3D Intersection over Union (IoU) scores on the simulated dataset. Empirical evaluations, conducted by testing our model on real-world datasets, underscored the model's viability for real-world strawberry harvesting scenarios, even though its training was based on synthetic data. The model also exhibited robust occlusion handling abilities, maintaining accurate detection capabilities even when strawberries were obscured by other strawberries or foliage. Additionally, the model showcased remarkably swift inference speeds, reaching up to 60 frames per second (FPS).
When LLMs Meet Cybersecurity: A Systematic Literature Review
May 06, 2024The rapid advancements in large language models (LLMs) have opened new avenues across various fields, including cybersecurity, which faces an ever-evolving threat landscape and need for innovative technologies. Despite initial explorations into the application of LLMs in cybersecurity, there is a lack of a comprehensive overview of this research area. This paper bridge this gap by providing a systematic literature review, encompassing an analysis of over 180 works, spanning across 25 LLMs and more than 10 downstream scenarios. Our comprehensive overview addresses three critical research questions: the construction of cybersecurity-oriented LLMs, LLMs' applications in various cybersecurity tasks, and the existing challenges and further research in this area. This study aims to shed light on the extensive potential of LLMs in enhancing cybersecurity practices, and serve as a valuable resource for applying LLMs in this doamin. We also maintain and regularly updated list of practical guides on LLMs for cybersecurity at https://github.com/tmylla/Awesome-LLM4Cybersecurity.
Deep Joint CSI Feedback and Multiuser Precoding for MIMO OFDM Systems
Apr 25, 2024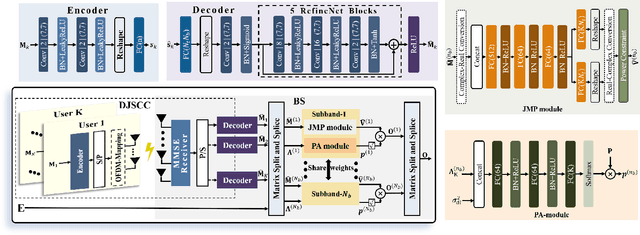
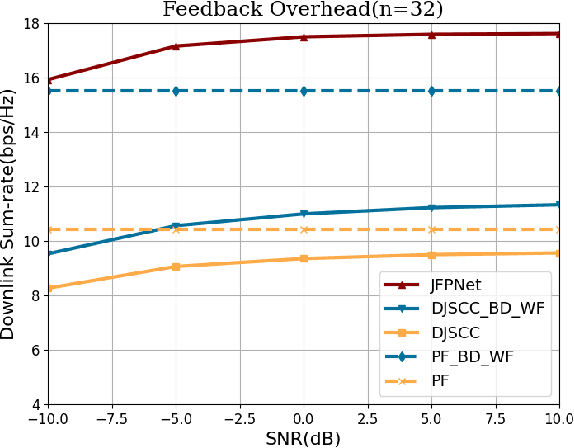
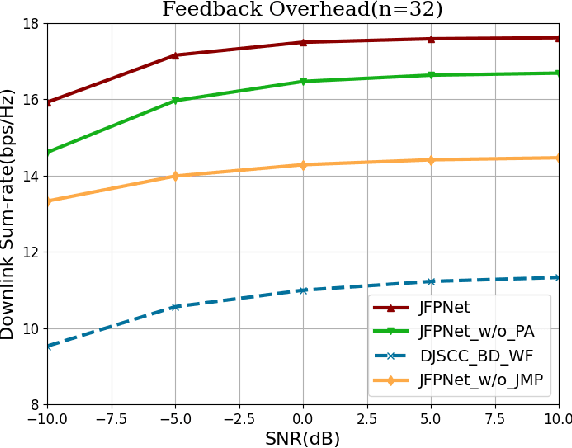
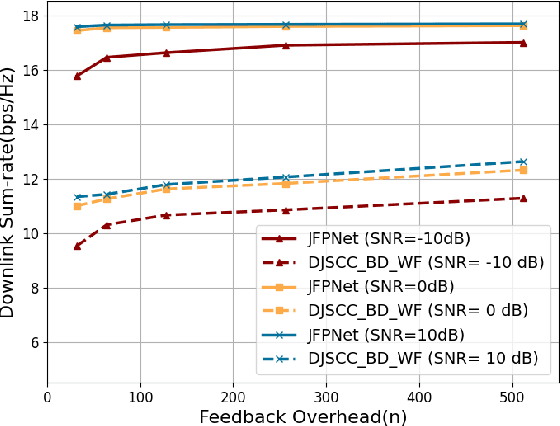
The design of precoding plays a crucial role in achieving a high downlink sum-rate in multiuser multiple-input multiple-output (MIMO) orthogonal frequency-division multiplexing (OFDM) systems. In this correspondence, we propose a deep learning based joint CSI feedback and multiuser precoding method in frequency division duplex systems, aiming at maximizing the downlink sum-rate performance in an end-to-end manner. Specifically, the eigenvectors of the CSI matrix are compressed using deep joint source-channel coding techniques. This compression method enhances the resilience of the feedback CSI information against degradation in the feedback channel. A joint multiuser precoding module and a power allocation module are designed to adjust the precoding direction and the precoding power for users based on the feedback CSI information. Experimental results demonstrate that the downlink sum-rate can be significantly improved by using the proposed method, especially in scenarios with low signal-to-noise ratio and low feedback overhead.
Swin Transformer-Based CSI Feedback for Massive MIMO
Jan 12, 2024For massive multiple-input multiple-output systems in the frequency division duplex (FDD) mode, accurate downlink channel state information (CSI) is required at the base station (BS). However, the increasing number of transmit antennas aggravates the feedback overhead of CSI. Recently, deep learning (DL) has shown considerable potential to reduce CSI feedback overhead. In this paper, we propose a Swin Transformer-based autoencoder network called SwinCFNet for the CSI feedback task. In particular, the proposed method can effectively capture the long-range dependence information of CSI. Moreover, we explore the impact of the number of Swin Transformer blocks and the dimension of feature channels on the performance of SwinCFNet. Experimental results show that SwinCFNet significantly outperforms other DL-based methods with comparable model sizes, especially for the outdoor scenario.
Rate Compatible LDPC Neural Decoding Network: A Multi-Task Learning Approach
Oct 10, 2023



Deep learning based decoding networks have shown significant improvement in decoding LDPC codes, but the neural decoders are limited by rate-matching operations such as puncturing or extending, thus needing to train multiple decoders with different code rates for a variety of channel conditions. In this correspondence, we propose a Multi-Task Learning based rate-compatible LDPC ecoding network, which utilizes the structure of raptor-like LDPC codes and can deal with multiple code rates. In the proposed network, different portions of parameters are activated to deal with distinct code rates, which leads to parameter sharing among tasks. Numerical experiments demonstrate the effectiveness of the proposed method. Training the specially designed network under multiple code rates makes the decoder compatible with multiple code rates without sacrificing frame error rate performance.
Approximation of Images via Generalized Higher Order Singular Value Decomposition over Finite-dimensional Commutative Semisimple Algebra
Feb 03, 2022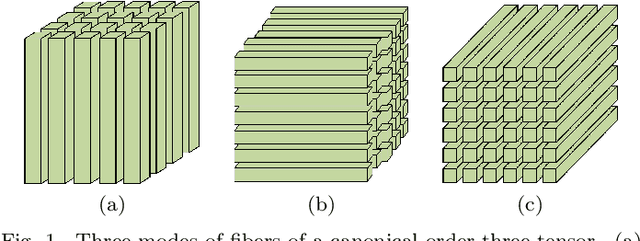


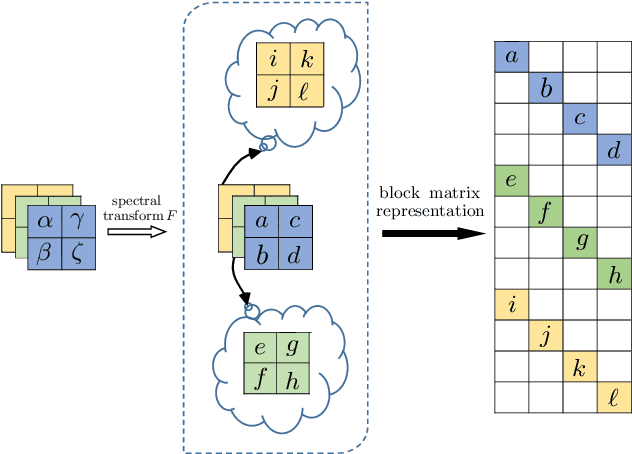
Low-rank approximation of images via singular value decomposition is well-received in the era of big data. However, singular value decomposition (SVD) is only for order-two data, i.e., matrices. It is necessary to flatten a higher order input into a matrix or break it into a series of order-two slices to tackle higher order data such as multispectral images and videos with the SVD. Higher order singular value decomposition (HOSVD) extends the SVD and can approximate higher order data using sums of a few rank-one components. We consider the problem of generalizing HOSVD over a finite dimensional commutative algebra. This algebra, referred to as a t-algebra, generalizes the field of complex numbers. The elements of the algebra, called t-scalars, are fix-sized arrays of complex numbers. One can generalize matrices and tensors over t-scalars and then extend many canonical matrix and tensor algorithms, including HOSVD, to obtain higher-performance versions. The generalization of HOSVD is called THOSVD. Its performance of approximating multi-way data can be further improved by an alternating algorithm. THOSVD also unifies a wide range of principal component analysis algorithms. To exploit the potential of generalized algorithms using t-scalars for approximating images, we use a pixel neighborhood strategy to convert each pixel to "deeper-order" t-scalar. Experiments on publicly available images show that the generalized algorithm over t-scalars, namely THOSVD, compares favorably with its canonical counterparts.