 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Communications in Intelligent Rail Transit: From LCX to PASS
Apr 14, 2026Wireless communications in intelligent rail transit face harsh propagation conditions, including severe penetration loss, frequent blockages, and amplified large-scale fading. Existing leaky coaxial cables (LCX) provide wired-to-wireless conversion and stable coverage, but can be energy- and spectrum-inefficient, particularly at high carrier frequencies. Motivated by the growing demand for high-capacity and high-reliability rail services, this article introduces pinching-antenna systems (PASS), which are flexible waveguide-based architectures that enable reconfigurable radiation points with low deployment overhead and a natural fit to predominantly straight track geometries. We discuss the key benefits and deployment flexibility of PASS, evaluate their performance relative to LCX via representative simulations, and present a deep learning (DL)-enabled channel-estimation framework to cope with mobility-induced channel dynamics. Finally, we summarize the major open challenges for practical deployment and outline promising research directions.
SGR-OCC: Evolving Monocular Priors for Embodied 3D Occupancy Prediction via Soft-Gating Lifting and Semantic-Adaptive Geometric Refinement
Mar 14, 20263D semantic occupancy prediction is a cornerstone for embodied AI, enabling agents to perceive dense scene geometry and semantics incrementally from monocular video streams. However, current online frameworks face two critical bottlenecks: the inherent depth ambiguity of monocular estimation that causes "feature bleeding" at object boundaries , and the "cold start" instability where uninitialized temporal fusion layers distort high-quality spatial priors during early training stages. In this paper, we propose SGR-OCC (Soft-Gating and Ray-refinement Occupancy), a unified framework driven by the philosophy of "Inheritance and Evolution". To perfectly inherit monocular spatial expertise, we introduce a Soft-Gating Feature Lifter that explicitly models depth uncertainty via a Gaussian gate to probabilistically suppress background noise. Furthermore, a Dynamic Ray-Constrained Anchor Refinement module simplifies complex 3D displacement searches into efficient 1D depth corrections along camera rays, ensuring sub-voxel adherence to physical surfaces. To ensure stable evolution toward temporal consistency, we employ a Two-Phase Progressive Training Strategy equipped with identity-initialized fusion, effectively resolving the cold start problem and shielding spatial priors from noisy early gradients. Extensive experiments on the EmbodiedOcc-ScanNet and Occ-ScanNet benchmarks demonstrate that SGR-OCC achieves state-of-the-art performance. In local prediction tasks, SGR-OCC achieves a completion IoU of 58.55$\%$ and a semantic mIoU of 49.89$\%$, surpassing the previous best method, EmbodiedOcc++, by 3.65$\%$ and 3.69$\%$ respectively. In challenging embodied prediction tasks, our model reaches 55.72$\%$ SC-IoU and 46.22$\%$ mIoU. Qualitative results further confirm our model's superior capability in preserving structural integrity and boundary sharpness in complex indoor environments.
Deep Dense Exploration for LLM Reinforcement Learning via Pivot-Driven Resampling
Feb 15, 2026Effective exploration is a key challenge in reinforcement learning for large language models: discovering high-quality trajectories within a limited sampling budget from the vast natural language sequence space. Existing methods face notable limitations: GRPO samples exclusively from the root, saturating high-probability trajectories while leaving deep, error-prone states under-explored. Tree-based methods blindly disperse budgets across trivial or unrecoverable states, causing sampling dilution that fails to uncover rare correct suffixes and destabilizes local baselines. To address this, we propose Deep Dense Exploration (DDE), a strategy that focuses exploration on $\textit{pivots}$-deep, recoverable states within unsuccessful trajectories. We instantiate DDE with DEEP-GRPO, which introduces three key innovations: (1) a lightweight data-driven utility function that automatically balances recoverability and depth bias to identify pivot states; (2) local dense resampling at each pivot to increase the probability of discovering correct subsequent trajectories; and (3) a dual-stream optimization objective that decouples global policy learning from local corrective updates. Experiments on mathematical reasoning benchmarks demonstrate that our method consistently outperforms GRPO, tree-based methods, and other strong baselines.
Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
May 29, 2025Enhancing the reasoning capabilities of large language models effectively using reinforcement learning (RL) remains a crucial challenge. Existing approaches primarily adopt two contrasting advantage estimation granularities: Token-level methods (e.g., PPO) aim to provide the fine-grained advantage signals but suffer from inaccurate estimation due to difficulties in training an accurate critic model. On the other extreme, trajectory-level methods (e.g., GRPO) solely rely on a coarse-grained advantage signal from the final reward, leading to imprecise credit assignment. To address these limitations, we propose Segment Policy Optimization (SPO), a novel RL framework that leverages segment-level advantage estimation at an intermediate granularity, achieving a better balance by offering more precise credit assignment than trajectory-level methods and requiring fewer estimation points than token-level methods, enabling accurate advantage estimation based on Monte Carlo (MC) without a critic model. SPO features three components with novel strategies: (1) flexible segment partition; (2) accurate segment advantage estimation; and (3) policy optimization using segment advantages, including a novel probability-mask strategy. We further instantiate SPO for two specific scenarios: (1) SPO-chain for short chain-of-thought (CoT), featuring novel cutpoint-based partition and chain-based advantage estimation, achieving $6$-$12$ percentage point improvements in accuracy over PPO and GRPO on GSM8K. (2) SPO-tree for long CoT, featuring novel tree-based advantage estimation, which significantly reduces the cost of MC estimation, achieving $7$-$11$ percentage point improvements over GRPO on MATH500 under 2K and 4K context evaluation. We make our code publicly available at https://github.com/AIFrameResearch/SPO.
Uplink Assisted Joint Channel Estimation and CSI Feedback: An Approach Based on Deep Joint Source-Channel Coding
Apr 15, 2025In frequency division duplex (FDD) multiple-input multiple-output (MIMO) wireless communication systems, the acquisition of downlink channel state information (CSI) is essential for maximizing spatial resource utilization and improving system spectral efficiency. The separate design of modules in AI-based CSI feedback architectures under traditional modular communication frameworks, including channel estimation (CE), CSI compression and feedback, leads to sub-optimal performance. In this paper, we propose an uplink assisted joint CE and and CSI feedback approach via deep learning for downlink CSI acquisition, which mitigates performance degradation caused by distribution bias across separately trained modules in traditional modular communication frameworks. The proposed network adopts a deep joint source-channel coding (DJSCC) architecture to mitigate the cliff effect encountered in the conventional separate source-channel coding. Furthermore, we exploit the uplink CSI as auxiliary information to enhance CSI reconstruction accuracy by leveraging the partial reciprocity between the uplink and downlink channels in FDD systems, without introducing additional overhead. The effectiveness of uplink CSI as assisted information and the necessity of an end-toend multi-module joint training architecture is validated through comprehensive ablation and scalability experiments.
FamilyTool: A Multi-hop Personalized Tool Use Benchmark
Apr 09, 2025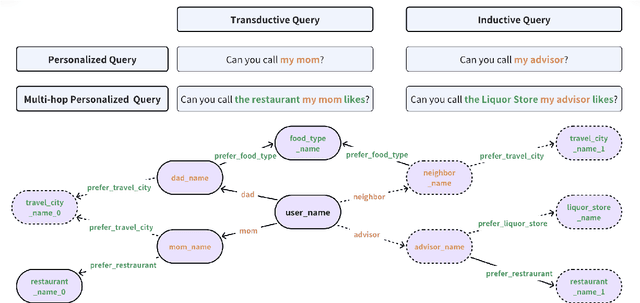

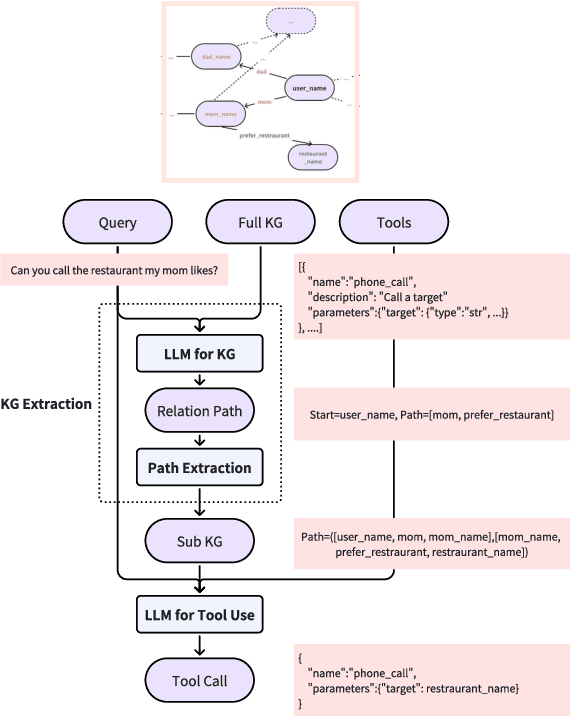

The integration of tool learning with Large Language Models (LLMs) has expanded their capabilities in handling complex tasks by leveraging external tools. However, existing benchmarks for tool learning inadequately address critical real-world personalized scenarios, particularly those requiring multi-hop reasoning and inductive knowledge adaptation in dynamic environments. To bridge this gap, we introduce FamilyTool, a novel benchmark grounded in a family-based knowledge graph (KG) that simulates personalized, multi-hop tool use scenarios. FamilyTool challenges LLMs with queries spanning 1 to 3 relational hops (e.g., inferring familial connections and preferences) and incorporates an inductive KG setting where models must adapt to unseen user preferences and relationships without re-training, a common limitation in prior approaches that compromises generalization. We further propose KGETool: a simple KG-augmented evaluation pipeline to systematically assess LLMs' tool use ability in these settings. Experiments reveal significant performance gaps in state-of-the-art LLMs, with accuracy dropping sharply as hop complexity increases and inductive scenarios exposing severe generalization deficits. These findings underscore the limitations of current LLMs in handling personalized, evolving real-world contexts and highlight the urgent need for advancements in tool-learning frameworks. FamilyTool serves as a critical resource for evaluating and advancing LLM agents' reasoning, adaptability, and scalability in complex, dynamic environments. Code and dataset are available at Github.
Deep Joint CSI Estimation-Feedback-Precoding for MU-MIMO OFDM Systems
Mar 06, 2025As the number of antennas in frequency-division duplex (FDD) multiple-input multiple-output (MIMO) systems increases, acquiring channel state information (CSI) becomes increasingly challenging due to limited spectral resources and feedback overhead. In this paper, we propose an end-to-end network that conducts joint design with pilot design, CSI estimation, CSI feedback, and precoding design in the multi-user MIMO orthogonal frequency-division multiplexing (OFDM) scenario. Multiple communication modules are jointly designed and trained with a common optimization objective to prevent mismatches between modules and discrepancies between individual module objectives and the final system goal. Experimental results demonstrate that, under the same feedback and CE overheads, the proposed joint multi-module end-to-end network achieves a higher multi-user downlink spectral efficiency than traditional algorithms based on separate architecture and partially separated artificial intelligence-based network architectures under comparable channel quality. Furthermore, compared to conventional separate architecture, the proposed network architecture with joint architecture reduces the computational burden and model storage overhead at the UE side, facilitating the deployment of low-overhead multi-module joint architectures in practice. While slightly increasing storage requirements at the base station, it reduces computational complexity and precoding design delay, effectively reducing the effects of channel aging challenges.
Prior-Fitted Networks Scale to Larger Datasets When Treated as Weak Learners
Mar 03, 2025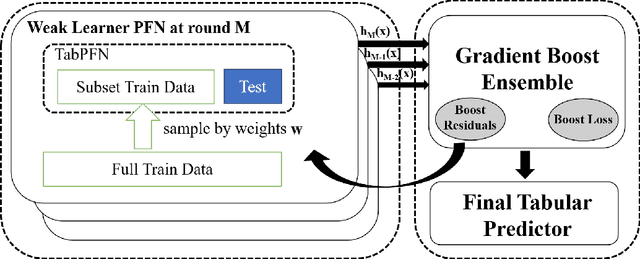

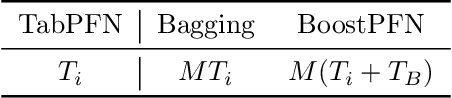
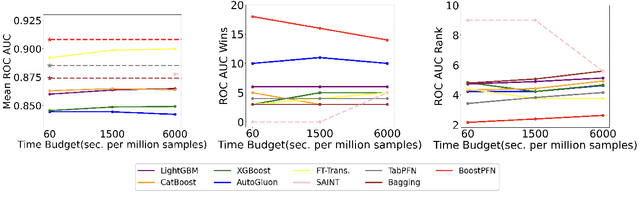
Prior-Fitted Networks (PFNs) have recently been proposed to efficiently perform tabular classification tasks. Although they achieve good performance on small datasets, they encounter limitations with larger datasets. These limitations include significant memory consumption and increased computational complexity, primarily due to the impracticality of incorporating all training samples as inputs within these networks. To address these challenges, we investigate the fitting assumption for PFNs and input samples. Building on this understanding, we propose \textit{BoostPFN} designed to enhance the performance of these networks, especially for large-scale datasets. We also theoretically validate the convergence of BoostPFN and our empirical results demonstrate that the BoostPFN method can outperform standard PFNs with the same size of training samples in large datasets and achieve a significant acceleration in training times compared to other established baselines in the field, including widely-used Gradient Boosting Decision Trees (GBDTs), deep learning methods and AutoML systems. High performance is maintained for up to 50x of the pre-training size of PFNs, substantially extending the limit of training samples. Through this work, we address the challenges of efficiently handling large datasets via PFN-based models, paving the way for faster and more effective tabular data classification training and prediction process. Code is available at Github.
Deep Learning for CSI Feedback: One-Sided Model and Joint Multi-Module Learning Perspectives
May 09, 2024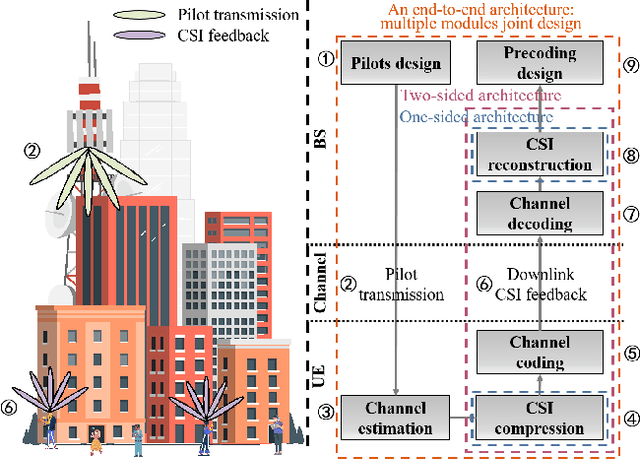

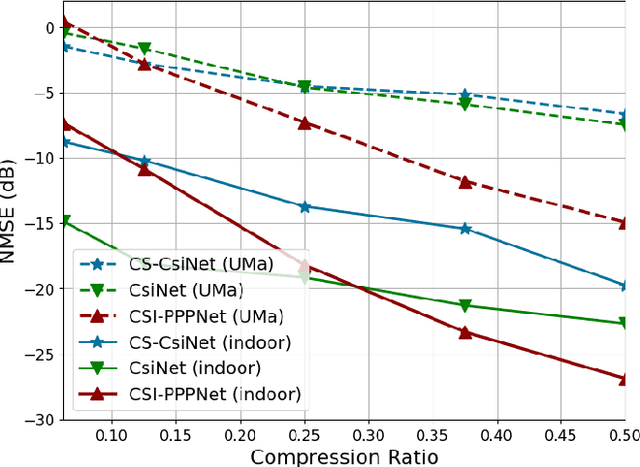
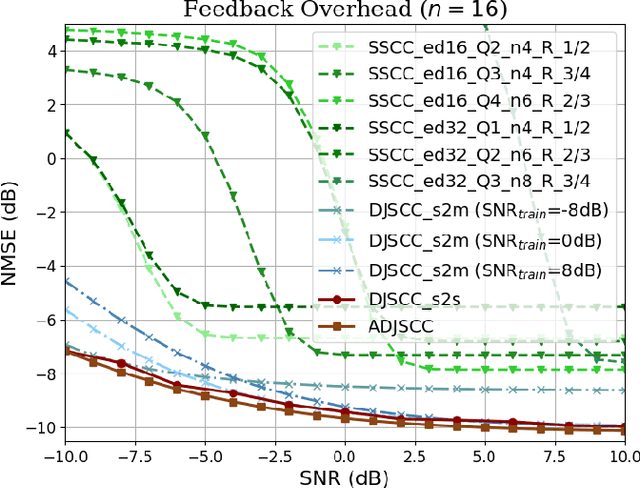
The use of deep learning (DL) for channel state information (CSI) feedback has garnered widespread attention across academia and industry. The mainstream DL architectures, e.g., CsiNet, deploy DL models on the base station (BS) side and the user equipment (UE) side, which are highly coupled and need to be trained jointly. However, two-sided DL models require collaborations between different network vendors and UE vendors, which entails considerable challenges in order to achieve consensus, e.g., model maintenance and responsibility. Furthermore, DL-based CSI feedback design invokes DL to reduce only the CSI feedback error, whereas jointly optimizing several modules at the transceivers would provide more significant gains. This article presents DL-based CSI feedback from the perspectives of one-sided model and joint multi-module learning. We herein introduce various novel one-sided CSI feedback architectures. In particular, the recently proposed CSI-PPPNet provides a one-sided one-for-all framework, which allows a DL model to deal with arbitrary CSI compression ratios. We review different joint multi-module learning methods, where the CSI feedback module is learned jointly with other modules including channel coding, channel estimation, pilot design and precoding design. Finally, future directions and challenges for DL-based CSI feedback are discussed, from the perspectives of inherent limitations of artificial intelligence (AI) and practical deployment issues.
Deep Joint CSI Feedback and Multiuser Precoding for MIMO OFDM Systems
Apr 25, 2024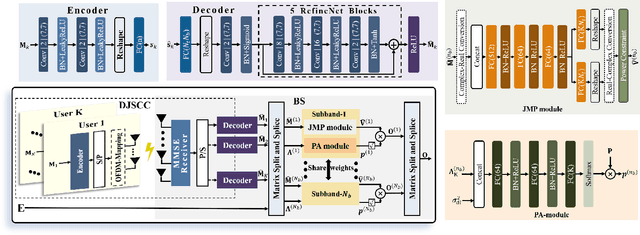
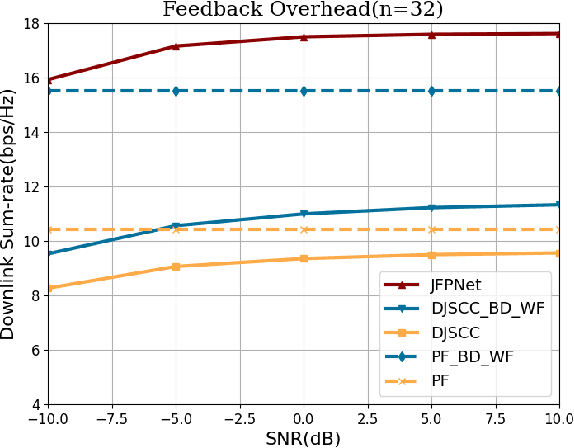
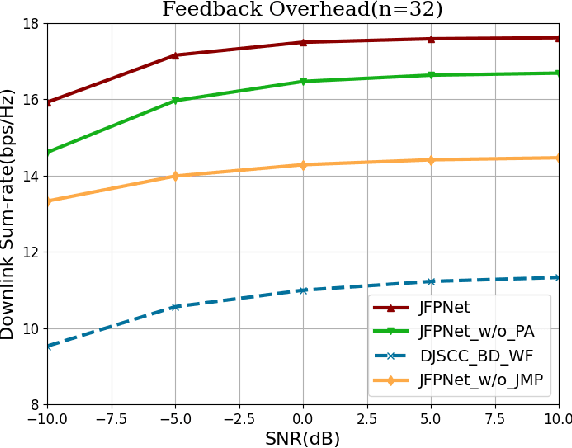
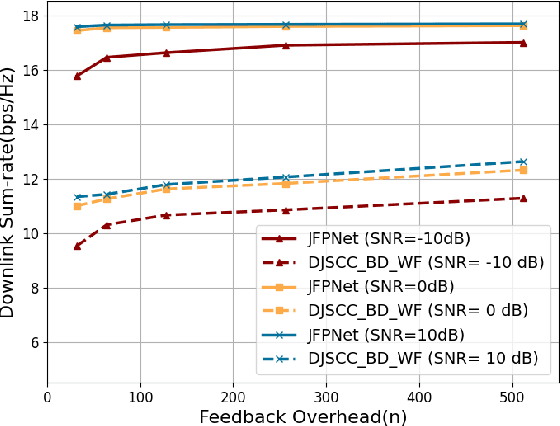
The design of precoding plays a crucial role in achieving a high downlink sum-rate in multiuser multiple-input multiple-output (MIMO) orthogonal frequency-division multiplexing (OFDM) systems. In this correspondence, we propose a deep learning based joint CSI feedback and multiuser precoding method in frequency division duplex systems, aiming at maximizing the downlink sum-rate performance in an end-to-end manner. Specifically, the eigenvectors of the CSI matrix are compressed using deep joint source-channel coding techniques. This compression method enhances the resilience of the feedback CSI information against degradation in the feedback channel. A joint multiuser precoding module and a power allocation module are designed to adjust the precoding direction and the precoding power for users based on the feedback CSI information. Experimental results demonstrate that the downlink sum-rate can be significantly improved by using the proposed method, especially in scenarios with low signal-to-noise ratio and low feedback overhead.