 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM-MCVT: A Lightweight Multi-modal Multi-view Convolutional-Vision Transformer Approach for 3D Object Recognition
Apr 27, 2025



In human-centered environments such as restaurants, homes, and warehouses, robots often face challenges in accurately recognizing 3D objects. These challenges stem from the complexity and variability of these environments, including diverse object shapes. In this paper, we propose a novel Lightweight Multi-modal Multi-view Convolutional-Vision Transformer network (LM-MCVT) to enhance 3D object recognition in robotic applications. Our approach leverages the Globally Entropy-based Embeddings Fusion (GEEF) method to integrate multi-views efficiently. The LM-MCVT architecture incorporates pre- and mid-level convolutional encoders and local and global transformers to enhance feature extraction and recognition accuracy. We evaluate our method on the synthetic ModelNet40 dataset and achieve a recognition accuracy of 95.6% using a four-view setup, surpassing existing state-of-the-art methods. To further validate its effectiveness, we conduct 5-fold cross-validation on the real-world OmniObject3D dataset using the same configuration. Results consistently show superior performance, demonstrating the method's robustness in 3D object recognition across synthetic and real-world 3D data.
HMT-Grasp: A Hybrid Mamba-Transformer Approach for Robot Grasping in Cluttered Environments
Oct 04, 2024



Robot grasping, whether handling isolated objects, cluttered items, or stacked objects, plays a critical role in industrial and service applications. However, current visual grasp detection methods based on Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) struggle to adapt across various grasping scenarios due to the imbalance between local and global feature extraction. In this paper, we propose a novel hybrid Mamba-Transformer approach to address these challenges. Our method improves robotic visual grasping by effectively capturing both global and local information through the integration of Vision Mamba and parallel convolutional-transformer blocks. This hybrid architecture significantly improves adaptability, precision, and flexibility across various robotic tasks. To ensure a fair evaluation, we conducted extensive experiments on the Cornell, Jacquard, and OCID-Grasp datasets, ranging from simple to complex scenarios. Additionally, we performed both simulated and real-world robotic experiments. The results demonstrate that our method not only surpasses state-of-the-art techniques on standard grasping datasets but also delivers strong performance in both simulation and real-world robot applications.
Fine-grained Object Categorization for Service Robots
Oct 03, 2022
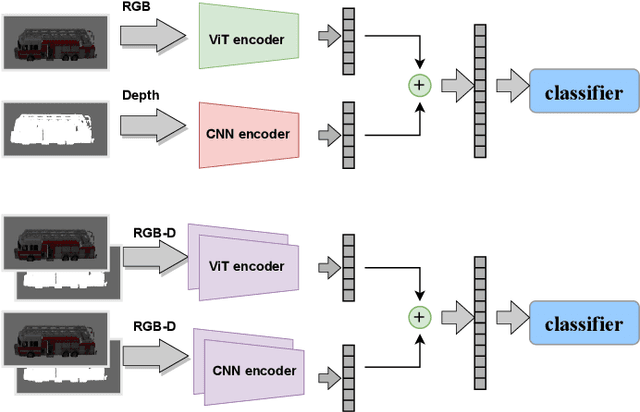

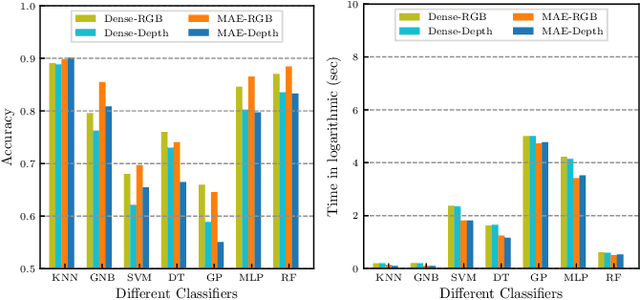
A robot working in a human-centered environment is frequently confronted with fine-grained objects that must be distinguished from one another. Fine-grained visual classification (FGVC) still remains a challenging problem due to large intra-category dissimilarity and small inter-category dissimilarity. Furthermore, flaws such as the influence of illumination and information inadequacy persist in fine-grained RGB datasets. We propose a novel deep mixed multi-modality approach based on Vision Transformer (ViT) and Convolutional Neural Network (CNN) to improve the performance of FGVC. Furthermore, we generate two synthetic fine-grained RGB-D datasets consisting of 13 car objects with 720 views and 120 shoes with 7200 sample views. Finally, to assess the performance of the proposed approach, we conducted several experiments using fine-grained RGB-D datasets. Experimental results show that our method outperformed other baselines in terms of recognition accuracy, and achieved 93.40 $\%$ and 91.67 $\%$ recognition accuracy on shoe and car dataset respectively. We made the fine-grained RGB-D datasets publicly available for the benefit of research communities.
Lifelong Ensemble Learning based on Multiple Representations for Few-Shot Object Recognition
May 12, 2022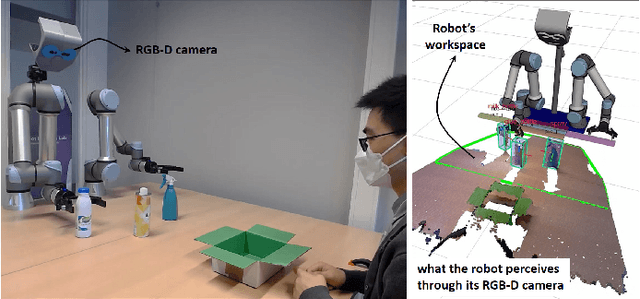
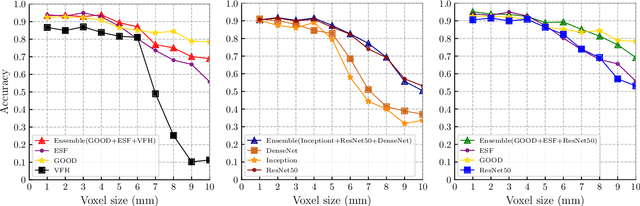
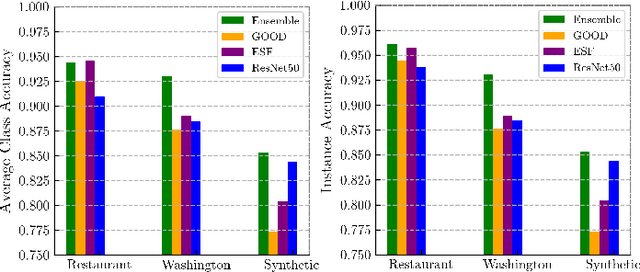
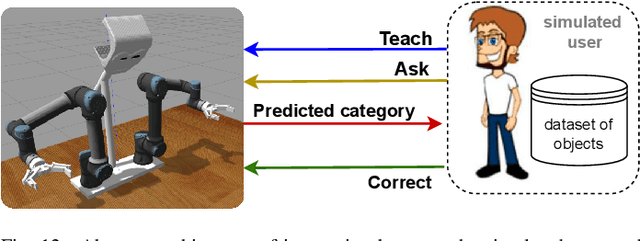
Service robots are integrating more and more into our daily lives to help us with various tasks. In such environments, robots frequently face new objects while working in the environment and need to learn them in an open-ended fashion. Furthermore, such robots must be able to recognize a wide range of object categories. In this paper, we present a lifelong ensemble learning approach based on multiple representations to address the few-shot object recognition problem. In particular, we form ensemble methods based on deep representations and handcrafted 3D shape descriptors. To facilitate lifelong learning, each approach is equipped with a memory unit for storing and retrieving object information instantly. The proposed model is suitable for open-ended learning scenarios where the number of 3D object categories is not fixed and can grow over time. We have performed extensive sets of experiments to assess the performance of the proposed approach in offline, and open-ended scenarios. For the evaluation purpose, in addition to real object datasets, we generate a large synthetic household objects dataset consisting of 27000 views of 90 objects. Experimental results demonstrate the effectiveness of the proposed method on 3D object recognition tasks, as well as its superior performance over the state-of-the-art approaches. Additionally, we demonstrated the effectiveness of our approach in both simulated and real-robot settings, where the robot rapidly learned new categories from limited examples.