 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemedy-R: Generative Reasoning for Machine Translation Evaluation without Error Annotations
Dec 21, 2025Over the years, automatic MT metrics have hillclimbed benchmarks and presented strong and sometimes human-level agreement with human ratings. Yet they remain black-box, offering little insight into their decision-making and often failing under real-world out-of-distribution (OOD) inputs. We introduce Remedy-R, a reasoning-driven generative MT metric trained with reinforcement learning from pairwise translation preferences, without requiring error-span annotations or distillation from closed LLMs. Remedy-R produces step-by-step analyses of accuracy, fluency, and completeness, followed by a final score, enabling more interpretable assessments. With only 60K training pairs across two language pairs, Remedy-R remains competitive with top scalar metrics and GPT-4-based judges on WMT22-24 meta-evaluation, generalizes to other languages, and exhibits strong robustness on OOD stress tests. Moreover, Remedy-R models generate self-reflective feedback that can be reused for translation improvement. Building on this finding, we introduce Remedy-R Agent, a simple evaluate-revise pipeline that leverages Remedy-R's evaluation analysis to refine translations. This agent consistently improves translation quality across diverse models, including Qwen2.5, ALMA-R, GPT-4o-mini, and Gemini-2.0-Flash, suggesting that Remedy-R's reasoning captures translation-relevant information and is practically useful.
Remedy: Learning Machine Translation Evaluation from Human Preferences with Reward Modeling
Apr 18, 2025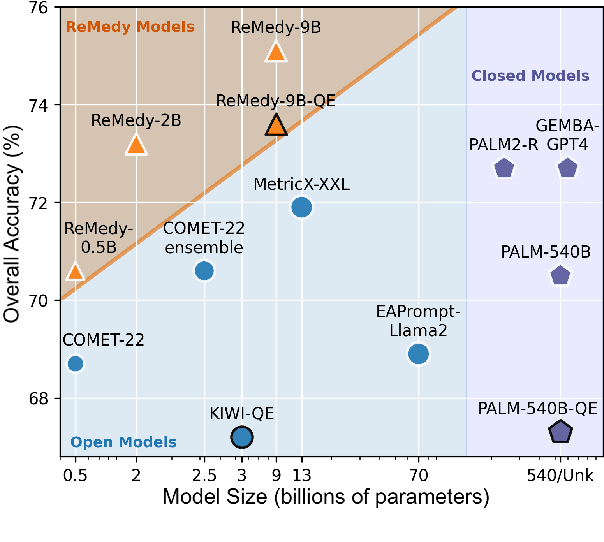
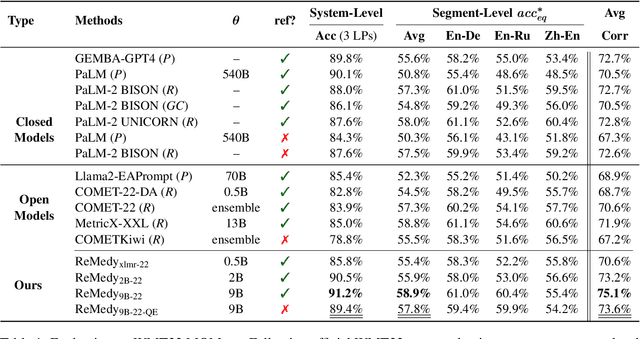
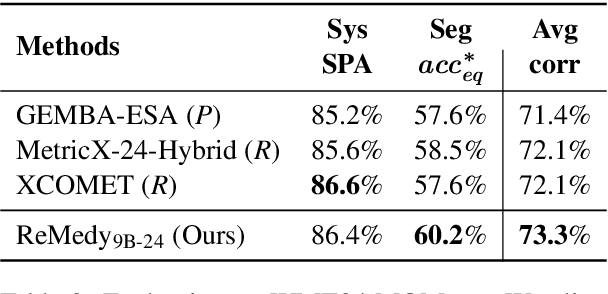
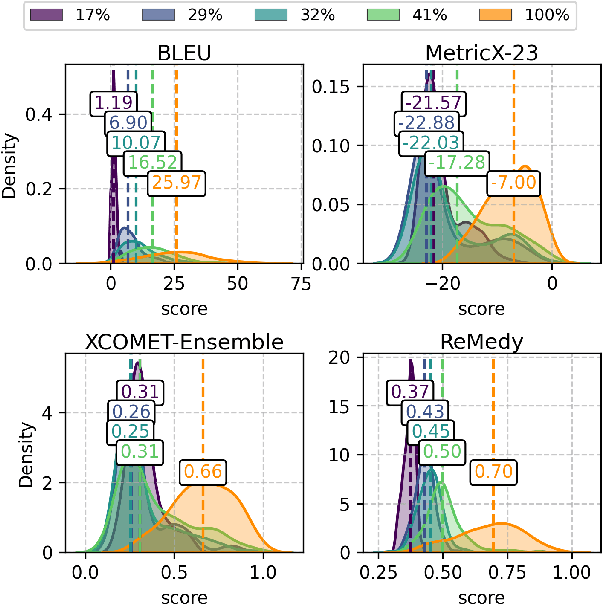
A key challenge in MT evaluation is the inherent noise and inconsistency of human ratings. Regression-based neural metrics struggle with this noise, while prompting LLMs shows promise at system-level evaluation but performs poorly at segment level. In this work, we propose ReMedy, a novel MT metric framework that reformulates translation evaluation as a reward modeling task. Instead of regressing on imperfect human ratings directly, ReMedy learns relative translation quality using pairwise preference data, resulting in a more reliable evaluation. In extensive experiments across WMT22-24 shared tasks (39 language pairs, 111 MT systems), ReMedy achieves state-of-the-art performance at both segment- and system-level evaluation. Specifically, ReMedy-9B surpasses larger WMT winners and massive closed LLMs such as MetricX-13B, XCOMET-Ensemble, GEMBA-GPT-4, PaLM-540B, and finetuned PaLM2. Further analyses demonstrate that ReMedy delivers superior capability in detecting translation errors and evaluating low-quality translations.
Neuron Specialization: Leveraging intrinsic task modularity for multilingual machine translation
Apr 17, 2024



Training a unified multilingual model promotes knowledge transfer but inevitably introduces negative interference. Language-specific modeling methods show promise in reducing interference. However, they often rely on heuristics to distribute capacity and struggle to foster cross-lingual transfer via isolated modules. In this paper, we explore intrinsic task modularity within multilingual networks and leverage these observations to circumvent interference under multilingual translation. We show that neurons in the feed-forward layers tend to be activated in a language-specific manner. Meanwhile, these specialized neurons exhibit structural overlaps that reflect language proximity, which progress across layers. Based on these findings, we propose Neuron Specialization, an approach that identifies specialized neurons to modularize feed-forward layers and then continuously updates them through sparse networks. Extensive experiments show that our approach achieves consistent performance gains over strong baselines with additional analyses demonstrating reduced interference and increased knowledge transfer.
How Far Can 100 Samples Go? Unlocking Overall Zero-Shot Multilingual Translation via Tiny Multi-Parallel Data
Jan 22, 2024Zero-shot translation is an open problem, aiming to translate between language pairs unseen during training in Multilingual Machine Translation (MMT). A common, albeit resource-consuming, solution is to mine as many translation directions as possible to add to the parallel corpus. In this paper, we show that the zero-shot capability of an English-centric model can be easily enhanced by fine-tuning with a very small amount of multi-parallel data. For example, on the EC30 dataset, we show that up to +21.7 ChrF non-English overall improvements (870 directions) can be achieved by using only 100 multi-parallel samples, meanwhile preserving capability in English-centric directions. We further study the size effect of fine-tuning data and its transfer capabilities. Surprisingly, our empirical analysis shows that comparable overall improvements can be achieved even through fine-tuning in a small, randomly sampled direction set (10\%). Also, the resulting non-English performance is quite close to the upper bound (complete translation). Due to its high efficiency and practicality, we encourage the community 1) to consider the use of the fine-tuning method as a strong baseline for zero-shot translation and 2) to construct more comprehensive and high-quality multi-parallel data to cover real-world demand.
Towards a Better Understanding of Variations in Zero-Shot Neural Machine Translation Performance
Oct 31, 2023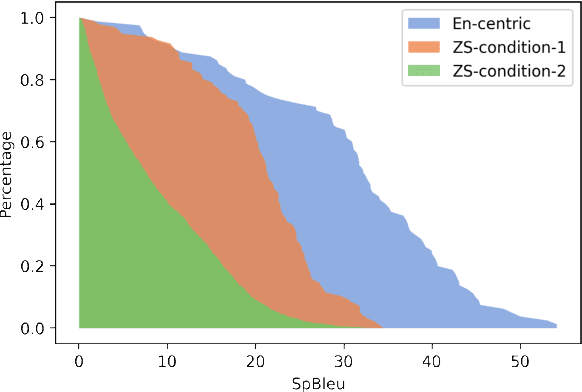
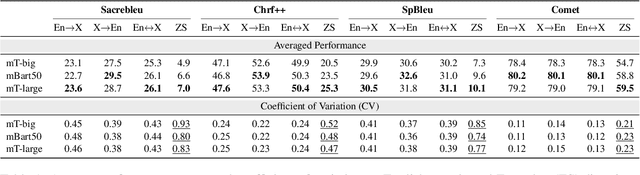
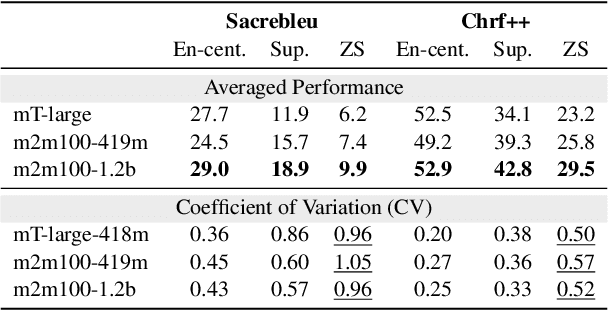
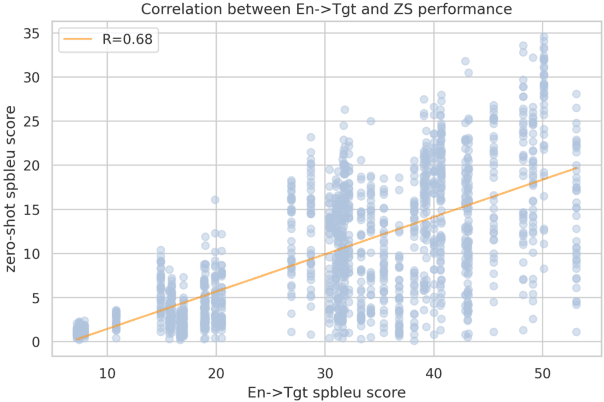
Multilingual Neural Machine Translation (MNMT) facilitates knowledge sharing but often suffers from poor zero-shot (ZS) translation qualities. While prior work has explored the causes of overall low ZS performance, our work introduces a fresh perspective: the presence of high variations in ZS performance. This suggests that MNMT does not uniformly exhibit poor ZS capability; instead, certain translation directions yield reasonable results. Through systematic experimentation involving 1,560 language directions spanning 40 languages, we identify three key factors contributing to high variations in ZS NMT performance: 1) target side translation capability 2) vocabulary overlap 3) linguistic properties. Our findings highlight that the target side translation quality is the most influential factor, with vocabulary overlap consistently impacting ZS performance. Additionally, linguistic properties, such as language family and writing system, play a role, particularly with smaller models. Furthermore, we suggest that the off-target issue is a symptom of inadequate ZS performance, emphasizing that zero-shot translation challenges extend beyond addressing the off-target problem. We release the data and models serving as a benchmark to study zero-shot for future research at https://github.com/Smu-Tan/ZS-NMT-Variations
UvA-MT's Participation in the WMT23 General Translation Shared Task
Oct 15, 2023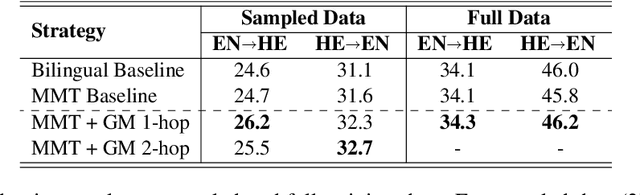
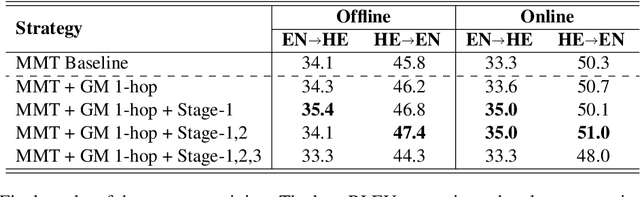
This paper describes the UvA-MT's submission to the WMT 2023 shared task on general machine translation. We participate in the constrained track in two directions: English <-> Hebrew. In this competition, we show that by using one model to handle bidirectional tasks, as a minimal setting of Multilingual Machine Translation (MMT), it is possible to achieve comparable results with that of traditional bilingual translation for both directions. By including effective strategies, like back-translation, re-parameterized embedding table, and task-oriented fine-tuning, we obtained competitive final results in the automatic evaluation for both English -> Hebrew and Hebrew -> English directions.
Document AI: A Comparative Study of Transformer-Based, Graph-Based Models, and Convolutional Neural Networks For Document Layout Analysis
Aug 29, 2023Document AI aims to automatically analyze documents by leveraging natural language processing and computer vision techniques. One of the major tasks of Document AI is document layout analysis, which structures document pages by interpreting the content and spatial relationships of layout, image, and text. This task can be image-centric, wherein the aim is to identify and label various regions such as authors and paragraphs, or text-centric, where the focus is on classifying individual words in a document. Although there are increasingly sophisticated methods for improving layout analysis, doubts remain about the extent to which their findings can be generalized to a broader context. Specifically, prior work developed systems based on very different architectures, such as transformer-based, graph-based, and CNNs. However, no work has mentioned the effectiveness of these models in a comparative analysis. Moreover, while language-independent Document AI models capable of knowledge transfer have been developed, it remains to be investigated to what degree they can effectively transfer knowledge. In this study, we aim to fill these gaps by conducting a comparative evaluation of state-of-the-art models in document layout analysis and investigating the potential of cross-lingual layout analysis by utilizing machine translation techniques.
Make Your Pre-trained Model Reversible: From Parameter to Memory Efficient Fine-Tuning
Jun 11, 2023Parameter-efficient fine-tuning (PEFT) of pre-trained language models (PLMs) has emerged as a highly successful approach, with training only a small number of parameters without sacrificing performance and becoming the de-facto learning paradigm with the increasing size of PLMs. However, existing PEFT methods are not memory-efficient, because they still require caching most of the intermediate activations for the gradient calculation, akin to fine-tuning. One effective way to reduce the activation memory is to apply a reversible model, so the intermediate activations are not necessary to be cached and can be recomputed. Nevertheless, modifying a PLM to its reversible variant with PEFT is not straightforward, since the reversible model has a distinct architecture from the currently released PLMs. In this paper, we first investigate what is a key factor for the success of existing PEFT methods, and realize that it's essential to preserve the PLM's starting point when initializing a PEFT method. With this finding, we propose memory-efficient fine-tuning (MEFT) that inserts adapters into a PLM, preserving the PLM's starting point and making it reversible without additional pre-training. We evaluate MEFT on the GLUE benchmark and five question-answering tasks with various backbones, BERT, RoBERTa, BART and OPT. MEFT significantly reduces the activation memory up to 84% of full fine-tuning with a negligible amount of trainable parameters. Moreover, MEFT achieves the same score on GLUE and a comparable score on the question-answering tasks as full fine-tuning.
Towards leveraging latent knowledge and Dialogue context for real-world conversational question answering
Dec 17, 2022



In many real-world scenarios, the absence of external knowledge source like Wikipedia restricts question answering systems to rely on latent internal knowledge in limited dialogue data. In addition, humans often seek answers by asking several questions for more comprehensive information. As the dialog becomes more extensive, machines are challenged to refer to previous conversation rounds to answer questions. In this work, we propose to leverage latent knowledge in existing conversation logs via a neural Retrieval-Reading system, enhanced with a TFIDF-based text summarizer refining lengthy conversational history to alleviate the long context issue. Our experiments show that our Retrieval-Reading system can exploit retrieved background knowledge to generate significantly better answers. The results also indicate that our context summarizer significantly helps both the retriever and the reader by introducing more concise and less noisy contextual information.