 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUvA-MT's Participation in the WMT23 General Translation Shared Task
Oct 15, 2023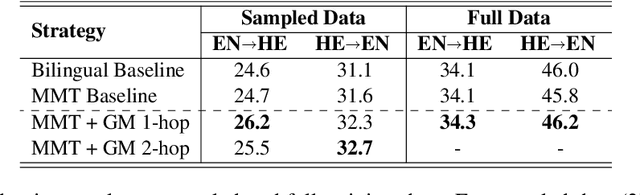
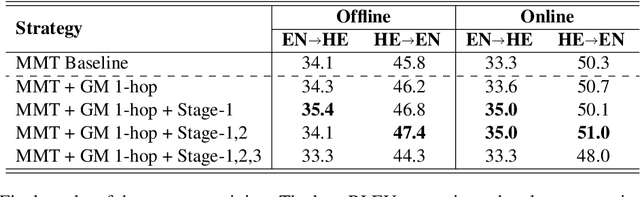
This paper describes the UvA-MT's submission to the WMT 2023 shared task on general machine translation. We participate in the constrained track in two directions: English <-> Hebrew. In this competition, we show that by using one model to handle bidirectional tasks, as a minimal setting of Multilingual Machine Translation (MMT), it is possible to achieve comparable results with that of traditional bilingual translation for both directions. By including effective strategies, like back-translation, re-parameterized embedding table, and task-oriented fine-tuning, we obtained competitive final results in the automatic evaluation for both English -> Hebrew and Hebrew -> English directions.
Joint Dropout: Improving Generalizability in Low-Resource Neural Machine Translation through Phrase Pair Variables
Jul 24, 2023Despite the tremendous success of Neural Machine Translation (NMT), its performance on low-resource language pairs still remains subpar, partly due to the limited ability to handle previously unseen inputs, i.e., generalization. In this paper, we propose a method called Joint Dropout, that addresses the challenge of low-resource neural machine translation by substituting phrases with variables, resulting in significant enhancement of compositionality, which is a key aspect of generalization. We observe a substantial improvement in translation quality for language pairs with minimal resources, as seen in BLEU and Direct Assessment scores. Furthermore, we conduct an error analysis, and find Joint Dropout to also enhance generalizability of low-resource NMT in terms of robustness and adaptability across different domains
How Effective is Byte Pair Encoding for Out-Of-Vocabulary Words in Neural Machine Translation?
Aug 17, 2022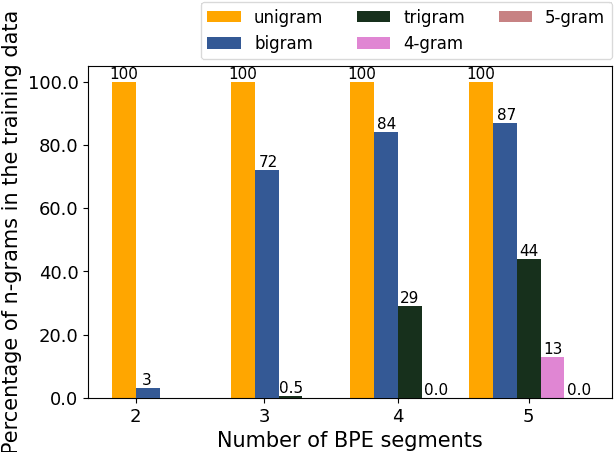



Neural Machine Translation (NMT) is an open vocabulary problem. As a result, dealing with the words not occurring during training (a.k.a. out-of-vocabulary (OOV) words) have long been a fundamental challenge for NMT systems. The predominant method to tackle this problem is Byte Pair Encoding (BPE) which splits words, including OOV words, into sub-word segments. BPE has achieved impressive results for a wide range of translation tasks in terms of automatic evaluation metrics. While it is often assumed that by using BPE, NMT systems are capable of handling OOV words, the effectiveness of BPE in translating OOV words has not been explicitly measured. In this paper, we study to what extent BPE is successful in translating OOV words at the word-level. We analyze the translation quality of OOV words based on word type, number of segments, cross-attention weights, and the frequency of segment n-grams in the training data. Our experiments show that while careful BPE settings seem to be fairly useful in translating OOV words across datasets, a considerable percentage of OOV words are translated incorrectly. Furthermore, we highlight the slightly higher effectiveness of BPE in translating OOV words for special cases, such as named-entities and when the languages involved are linguistically close to each other.
Optimizing Transformer for Low-Resource Neural Machine Translation
Nov 04, 2020
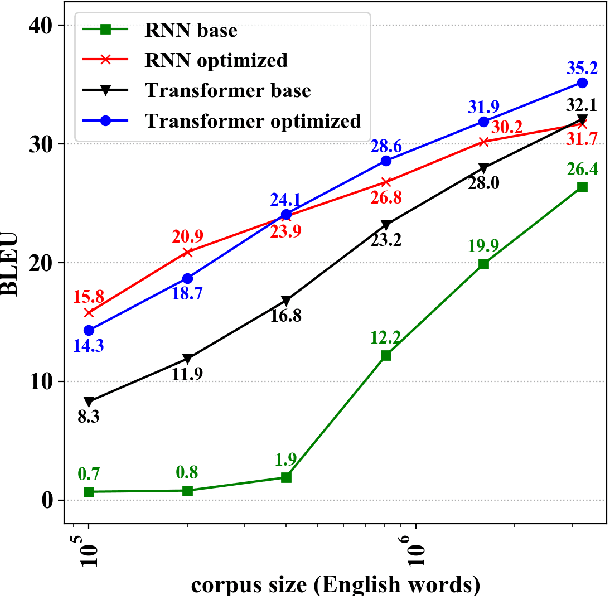
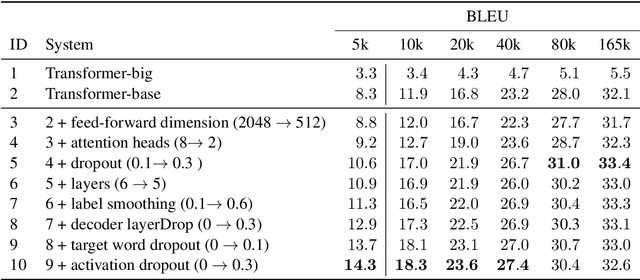
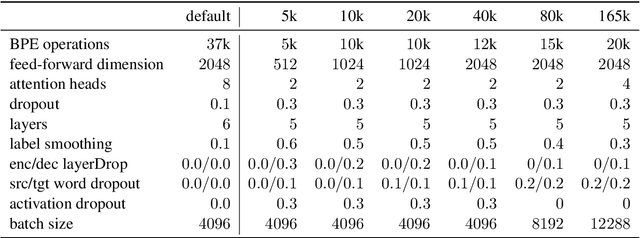
Language pairs with limited amounts of parallel data, also known as low-resource languages, remain a challenge for neural machine translation. While the Transformer model has achieved significant improvements for many language pairs and has become the de facto mainstream architecture, its capability under low-resource conditions has not been fully investigated yet. Our experiments on different subsets of the IWSLT14 training data show that the effectiveness of Transformer under low-resource conditions is highly dependent on the hyper-parameter settings. Our experiments show that using an optimized Transformer for low-resource conditions improves the translation quality up to 7.3 BLEU points compared to using the Transformer default settings.