 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-headed Neural Ensemble Search
Jul 09, 2021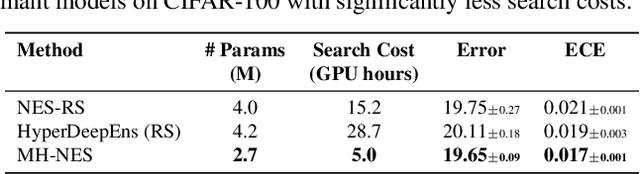
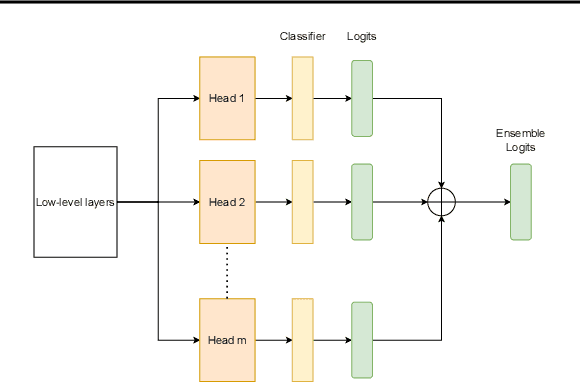
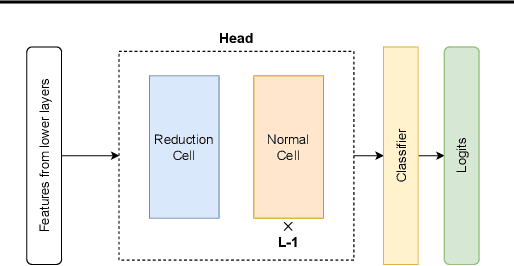
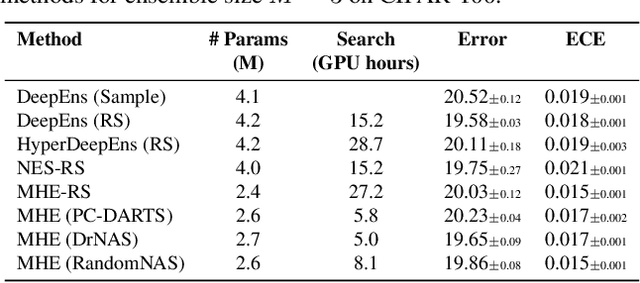
Ensembles of CNN models trained with different seeds (also known as Deep Ensembles) are known to achieve superior performance over a single copy of the CNN. Neural Ensemble Search (NES) can further boost performance by adding architectural diversity. However, the scope of NES remains prohibitive under limited computational resources. In this work, we extend NES to multi-headed ensembles, which consist of a shared backbone attached to multiple prediction heads. Unlike Deep Ensembles, these multi-headed ensembles can be trained end to end, which enables us to leverage one-shot NAS methods to optimize an ensemble objective. With extensive empirical evaluations, we demonstrate that multi-headed ensemble search finds robust ensembles 3 times faster, while having comparable performance to other ensemble search methods, in both predictive performance and uncertainty calibration.
What Causes Optical Flow Networks to be Vulnerable to Physical Adversarial Attacks
Mar 30, 2021
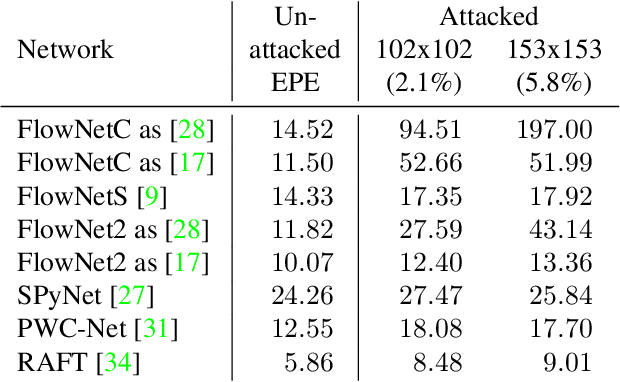


Recent work demonstrated the lack of robustness of optical flow networks to physical, patch-based adversarial attacks. The possibility to physically attack a basic component of automotive systems is a reason for serious concerns. In this paper, we analyze the cause of the problem and show that the lack of robustness is rooted in the classical aperture problem of optical flow estimation in combination with bad choices in the details of the network architecture. We show how these mistakes can be rectified in order to make optical flow networks robust to physical, patch-based attacks.
Improving robustness against common corruptions with frequency biased models
Mar 30, 2021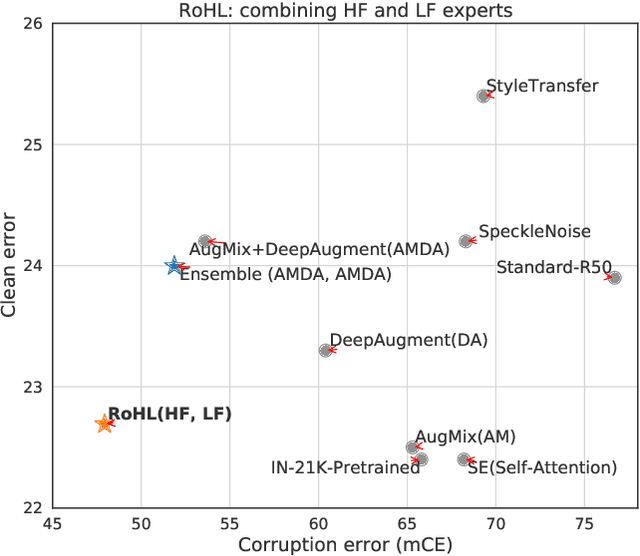
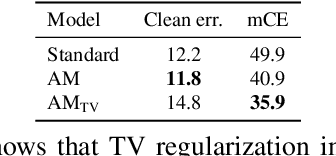
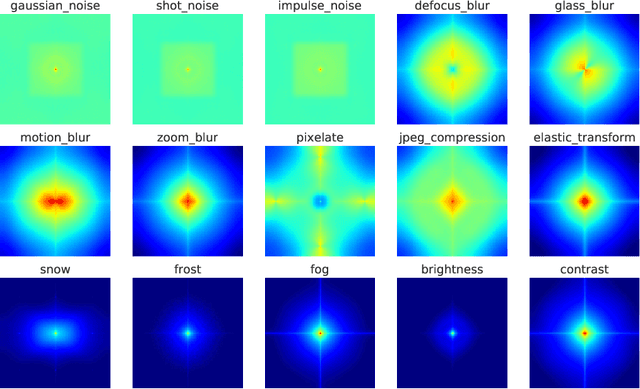
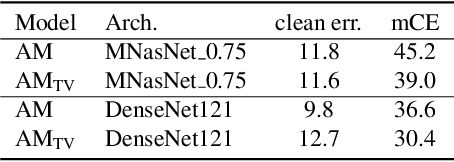
CNNs perform remarkably well when the training and test distributions are i.i.d, but unseen image corruptions can cause a surprisingly large drop in performance. In various real scenarios, unexpected distortions, such as random noise, compression artefacts, or weather distortions are common phenomena. Improving performance on corrupted images must not result in degraded i.i.d performance - a challenge faced by many state-of-the-art robust approaches. Image corruption types have different characteristics in the frequency spectrum and would benefit from a targeted type of data augmentation, which, however, is often unknown during training. In this paper, we introduce a mixture of two expert models specializing in high and low-frequency robustness, respectively. Moreover, we propose a new regularization scheme that minimizes the total variation (TV) of convolution feature-maps to increase high-frequency robustness. The approach improves on corrupted images without degrading in-distribution performance. We demonstrate this on ImageNet-C and also for real-world corruptions on an automotive dataset, both for object classification and object detection.
Optimized Generic Feature Learning for Few-shot Classification across Domains
Jan 22, 2020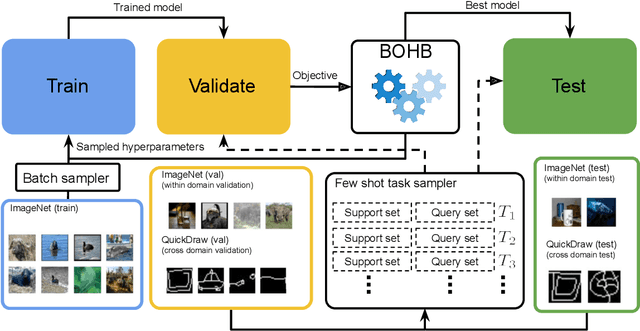

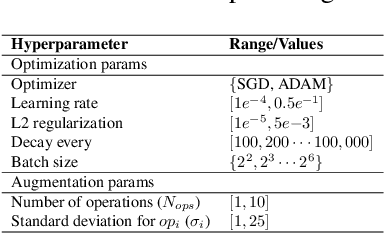
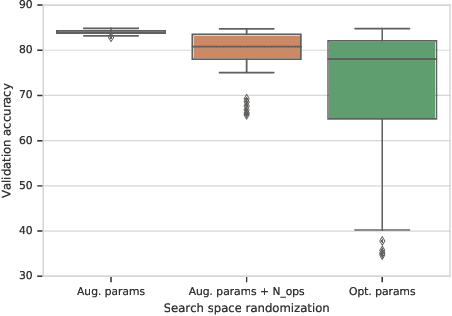
To learn models or features that generalize across tasks and domains is one of the grand goals of machine learning. In this paper, we propose to use cross-domain, cross-task data as validation objective for hyper-parameter optimization (HPO) to improve on this goal. Given a rich enough search space, optimization of hyper-parameters learn features that maximize validation performance and, due to the objective, generalize across tasks and domains. We demonstrate the effectiveness of this strategy on few-shot image classification within and across domains. The learned features outperform all previous few-shot and meta-learning approaches.
Understanding and Robustifying Differentiable Architecture Search
Sep 20, 2019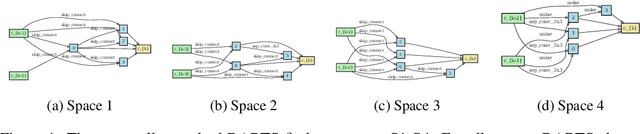
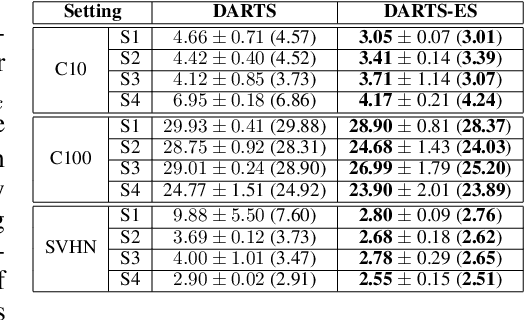
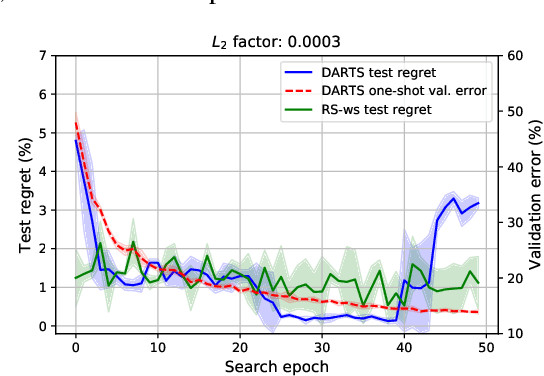
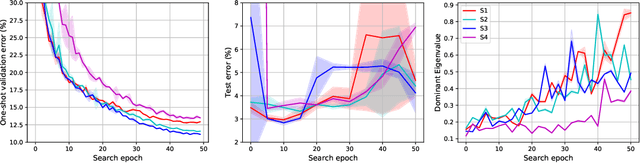
Differentiable Architecture Search (DARTS) has attracted a lot of attention due to its simplicity and small search costs achieved by a continuous relaxation and an approximation of the resulting bi-level optimization problem. However, DARTS does not work robustly for new problems: we identify a wide range of search spaces for which DARTS yields degenerate architectures with very poor test performance. We study this failure mode and show that, while DARTS successfully minimizes validation loss, the found solutions generalize poorly when they coincide with high validation loss curvature in the space of architectures. We show that by adding one of various types of regularization we can robustify DARTS to find solutions with smaller Hessian spectrum and with better generalization properties. Based on these observations we propose several simple variations of DARTS that perform substantially more robustly in practice. Our observations are robust across five search spaces on three image classification tasks and also hold for the very different domains of disparity estimation (a dense regression task) and language modelling. We provide our implementation and scripts to facilitate reproducibility.
AutoDispNet: Improving Disparity Estimation with AutoML
May 17, 2019
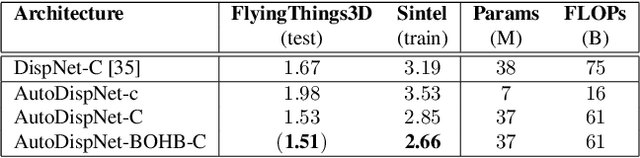

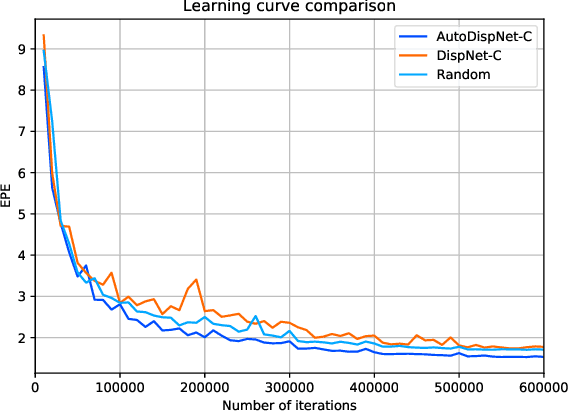
Much research work in computer vision is being spent on optimizing existing network architectures to obtain a few more percentage points on benchmarks. Recent AutoML approaches promise to relieve us from this effort. However, they are mainly designed for comparatively small-scale classification tasks. In this work, we show how to use and extend existing AutoML techniques to efficiently optimize large-scale U-Net-like encoder-decoder architectures. In particular, we leverage gradient-based neural architecture search and Bayesian optimization for hyperparameter search. The resulting optimization does not require a large company-scale compute cluster. We show results on disparity estimation that clearly outperform the manually optimized baseline and reach state-of-the-art performance.
Occlusions, Motion and Depth Boundaries with a Generic Network for Disparity, Optical Flow or Scene Flow Estimation
Aug 08, 2018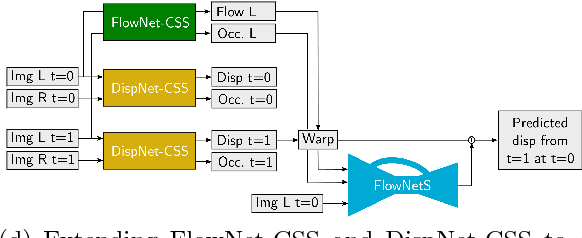


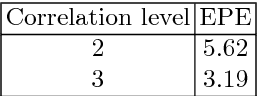
Occlusions play an important role in disparity and optical flow estimation, since matching costs are not available in occluded areas and occlusions indicate depth or motion boundaries. Moreover, occlusions are relevant for motion segmentation and scene flow estimation. In this paper, we present an efficient learning-based approach to estimate occlusion areas jointly with disparities or optical flow. The estimated occlusions and motion boundaries clearly improve over the state-of-the-art. Moreover, we present networks with state-of-the-art performance on the popular KITTI benchmark and good generic performance. Making use of the estimated occlusions, we also show improved results on motion segmentation and scene flow estimation.
FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
Dec 06, 2016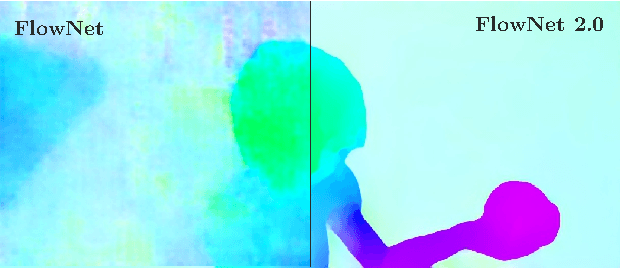
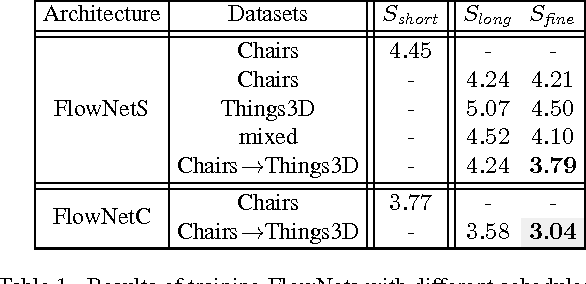
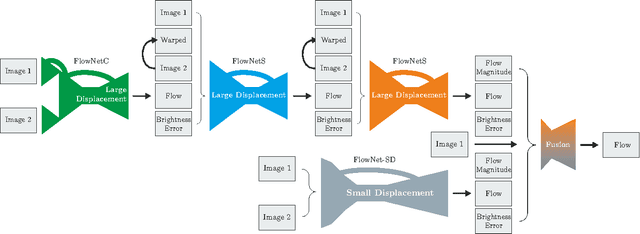

The FlowNet demonstrated that optical flow estimation can be cast as a learning problem. However, the state of the art with regard to the quality of the flow has still been defined by traditional methods. Particularly on small displacements and real-world data, FlowNet cannot compete with variational methods. In this paper, we advance the concept of end-to-end learning of optical flow and make it work really well. The large improvements in quality and speed are caused by three major contributions: first, we focus on the training data and show that the schedule of presenting data during training is very important. Second, we develop a stacked architecture that includes warping of the second image with intermediate optical flow. Third, we elaborate on small displacements by introducing a sub-network specializing on small motions. FlowNet 2.0 is only marginally slower than the original FlowNet but decreases the estimation error by more than 50%. It performs on par with state-of-the-art methods, while running at interactive frame rates. Moreover, we present faster variants that allow optical flow computation at up to 140fps with accuracy matching the original FlowNet.