 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Exposing the Challenging Long Tail in Future Prediction of Traffic Actors
Mar 24, 2021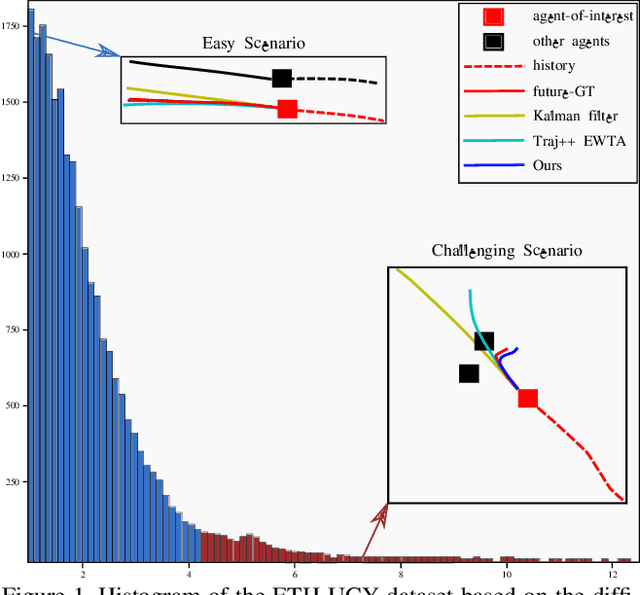
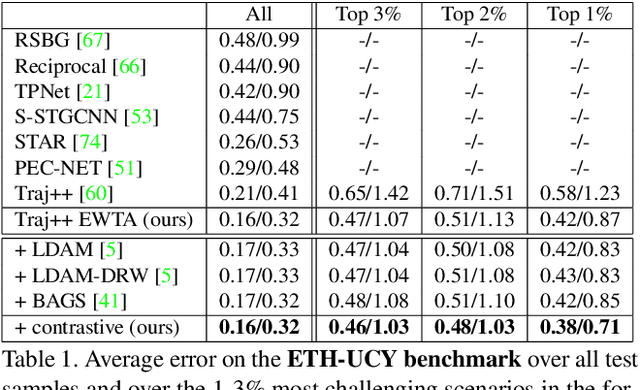
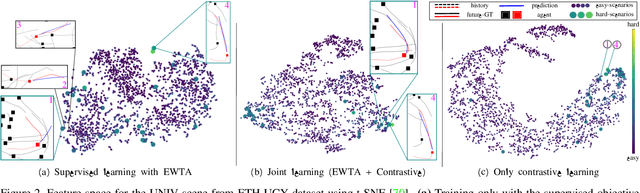
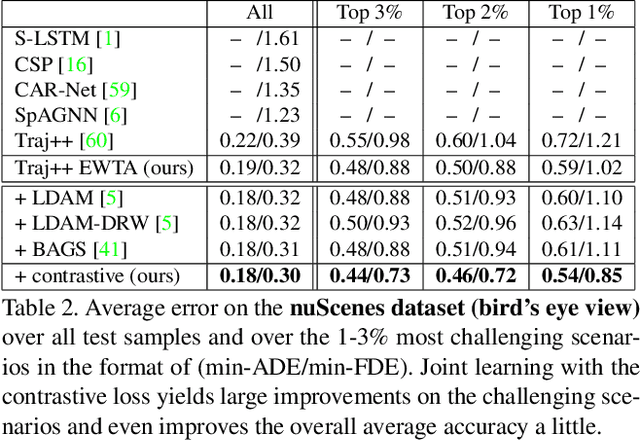
Predicting the states of dynamic traffic actors into the future is important for autonomous systems to operate safelyand efficiently. Remarkably, the most critical scenarios aremuch less frequent and more complex than the uncriticalones. Therefore, uncritical cases dominate the prediction. In this paper, we address specifically the challenging scenarios at the long tail of the dataset distribution. Our analysis shows that the common losses tend to place challenging cases suboptimally in the embedding space. As a consequence, we propose to supplement the usual loss with aloss that places challenging cases closer to each other. This triggers sharing information among challenging cases andlearning specific predictive features. We show on four public datasets that this leads to improved performance on the challenging scenarios while the overall performance stays stable. The approach is agnostic w.r.t. the used network architecture, input modality or viewpoint, and can be integrated into existing solutions easily.
Recovering the Imperfect: Cell Segmentation in the Presence of Dynamically Localized Proteins
Nov 20, 2020
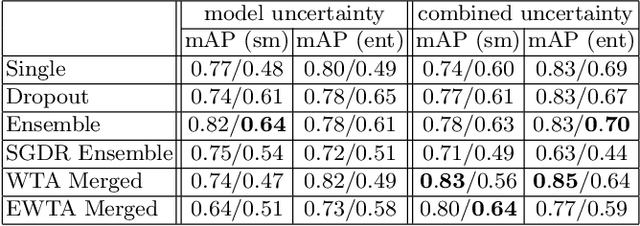


Deploying off-the-shelf segmentation networks on biomedical data has become common practice, yet if structures of interest in an image sequence are visible only temporarily, existing frame-by-frame methods fail. In this paper, we provide a solution to segmentation of imperfect data through time based on temporal propagation and uncertainty estimation. We integrate uncertainty estimation into Mask R-CNN network and propagate motion-corrected segmentation masks from frames with low uncertainty to those frames with high uncertainty to handle temporary loss of signal for segmentation. We demonstrate the value of this approach over frame-by-frame segmentation and regular temporal propagation on data from human embryonic kidney (HEK293T) cells transiently transfected with a fluorescent protein that moves in and out of the nucleus over time. The method presented here will empower microscopic experiments aimed at understanding molecular and cellular function.
Understanding and Robustifying Differentiable Architecture Search
Sep 20, 2019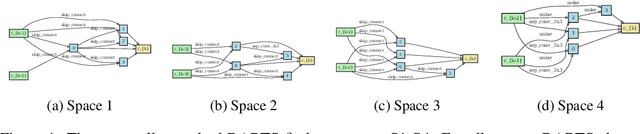
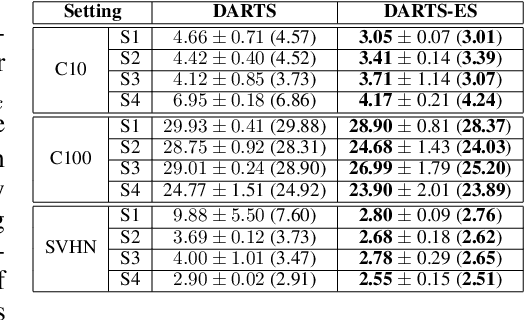
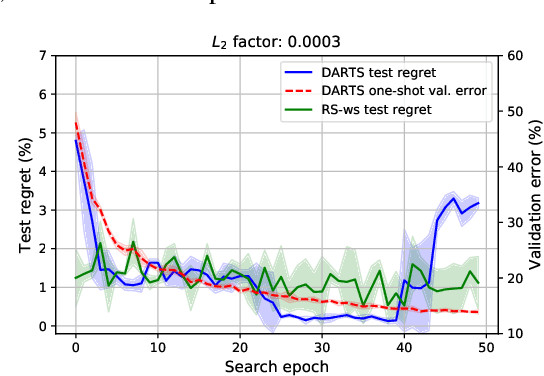
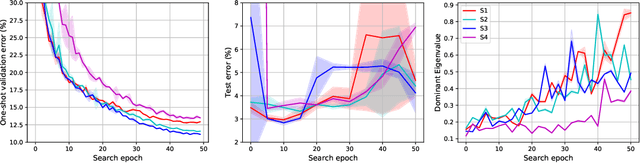
Differentiable Architecture Search (DARTS) has attracted a lot of attention due to its simplicity and small search costs achieved by a continuous relaxation and an approximation of the resulting bi-level optimization problem. However, DARTS does not work robustly for new problems: we identify a wide range of search spaces for which DARTS yields degenerate architectures with very poor test performance. We study this failure mode and show that, while DARTS successfully minimizes validation loss, the found solutions generalize poorly when they coincide with high validation loss curvature in the space of architectures. We show that by adding one of various types of regularization we can robustify DARTS to find solutions with smaller Hessian spectrum and with better generalization properties. Based on these observations we propose several simple variations of DARTS that perform substantially more robustly in practice. Our observations are robust across five search spaces on three image classification tasks and also hold for the very different domains of disparity estimation (a dense regression task) and language modelling. We provide our implementation and scripts to facilitate reproducibility.
AutoDispNet: Improving Disparity Estimation with AutoML
May 17, 2019
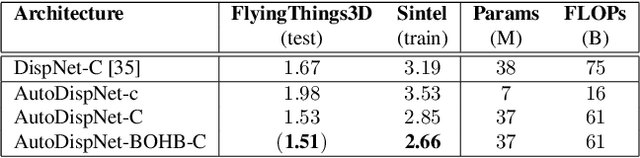

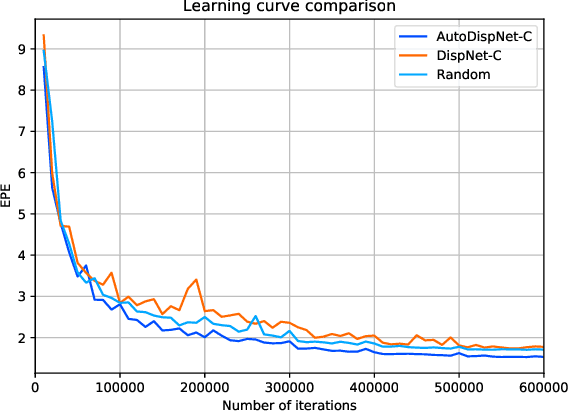
Much research work in computer vision is being spent on optimizing existing network architectures to obtain a few more percentage points on benchmarks. Recent AutoML approaches promise to relieve us from this effort. However, they are mainly designed for comparatively small-scale classification tasks. In this work, we show how to use and extend existing AutoML techniques to efficiently optimize large-scale U-Net-like encoder-decoder architectures. In particular, we leverage gradient-based neural architecture search and Bayesian optimization for hyperparameter search. The resulting optimization does not require a large company-scale compute cluster. We show results on disparity estimation that clearly outperform the manually optimized baseline and reach state-of-the-art performance.