 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoDispNet: Improving Disparity Estimation with AutoML
Paper and Code

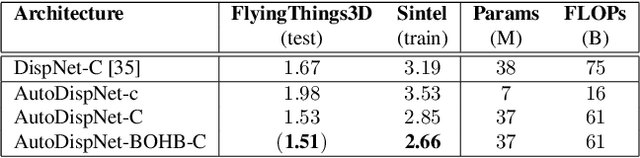

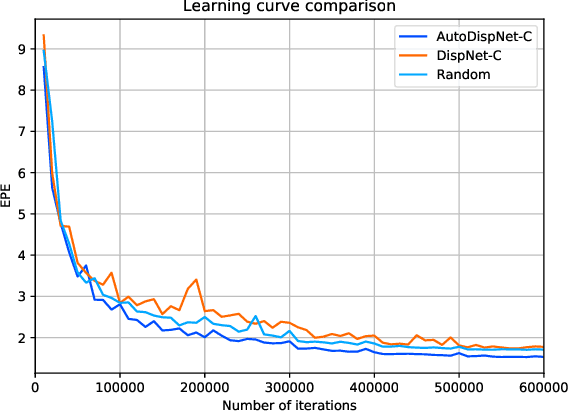
Much research work in computer vision is being spent on optimizing existing network architectures to obtain a few more percentage points on benchmarks. Recent AutoML approaches promise to relieve us from this effort. However, they are mainly designed for comparatively small-scale classification tasks. In this work, we show how to use and extend existing AutoML techniques to efficiently optimize large-scale U-Net-like encoder-decoder architectures. In particular, we leverage gradient-based neural architecture search and Bayesian optimization for hyperparameter search. The resulting optimization does not require a large company-scale compute cluster. We show results on disparity estimation that clearly outperform the manually optimized baseline and reach state-of-the-art performance.