 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data augmentation perspective on diffusion models and retrieval
Apr 20, 2023Diffusion models excel at generating photorealistic images from text-queries. Naturally, many approaches have been proposed to use these generative abilities to augment training datasets for downstream tasks, such as classification. However, diffusion models are themselves trained on large noisily supervised, but nonetheless, annotated datasets. It is an open question whether the generalization capabilities of diffusion models beyond using the additional data of the pre-training process for augmentation lead to improved downstream performance. We perform a systematic evaluation of existing methods to generate images from diffusion models and study new extensions to assess their benefit for data augmentation. While we find that personalizing diffusion models towards the target data outperforms simpler prompting strategies, we also show that using the training data of the diffusion model alone, via a simple nearest neighbor retrieval procedure, leads to even stronger downstream performance. Overall, our study probes the limitations of diffusion models for data augmentation but also highlights its potential in generating new training data to improve performance on simple downstream vision tasks.
You Mostly Walk Alone: Analyzing Feature Attribution in Trajectory Prediction
Oct 11, 2021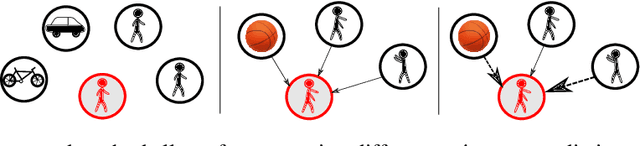
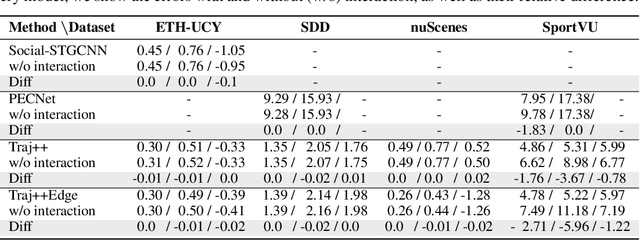

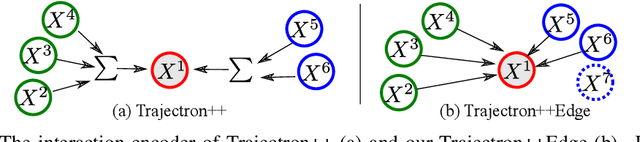
Predicting the future trajectory of a moving agent can be easy when the past trajectory continues smoothly but is challenging when complex interactions with other agents are involved. Recent deep learning approaches for trajectory prediction show promising performance and partially attribute this to successful reasoning about agent-agent interactions. However, it remains unclear which features such black-box models actually learn to use for making predictions. This paper proposes a procedure that quantifies the contributions of different cues to model performance based on a variant of Shapley values. Applying this procedure to state-of-the-art trajectory prediction methods on standard benchmark datasets shows that they are, in fact, unable to reason about interactions. Instead, the past trajectory of the target is the only feature used for predicting its future. For a task with richer social interaction patterns, on the other hand, the tested models do pick up such interactions to a certain extent, as quantified by our feature attribution method. We discuss the limits of the proposed method and its links to causality
On Exposing the Challenging Long Tail in Future Prediction of Traffic Actors
Mar 24, 2021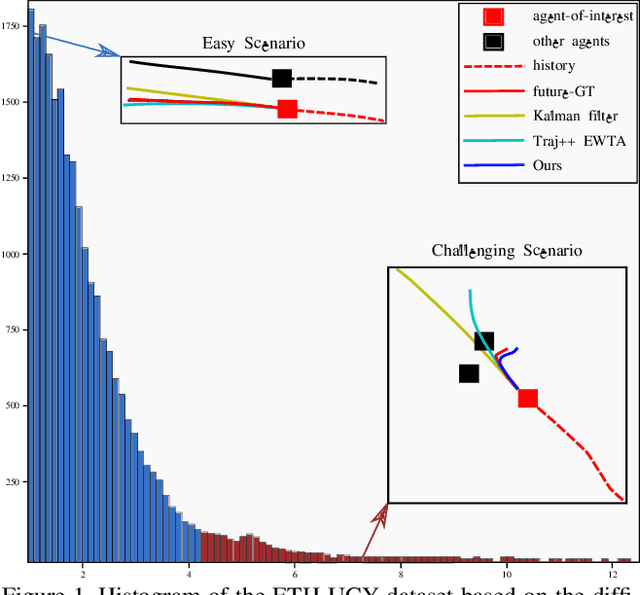
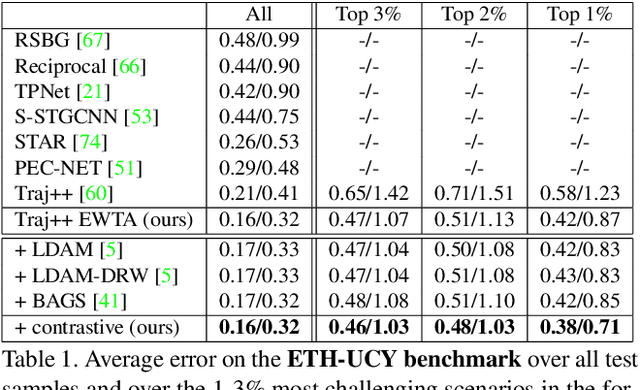
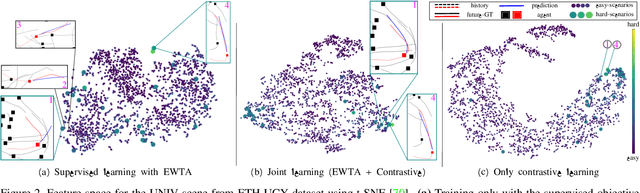
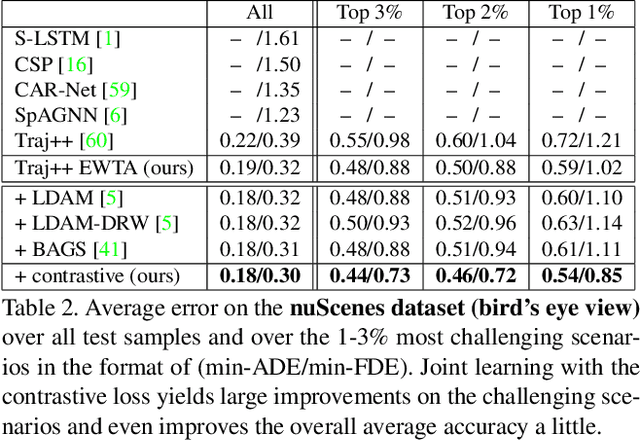
Predicting the states of dynamic traffic actors into the future is important for autonomous systems to operate safelyand efficiently. Remarkably, the most critical scenarios aremuch less frequent and more complex than the uncriticalones. Therefore, uncritical cases dominate the prediction. In this paper, we address specifically the challenging scenarios at the long tail of the dataset distribution. Our analysis shows that the common losses tend to place challenging cases suboptimally in the embedding space. As a consequence, we propose to supplement the usual loss with aloss that places challenging cases closer to each other. This triggers sharing information among challenging cases andlearning specific predictive features. We show on four public datasets that this leads to improved performance on the challenging scenarios while the overall performance stays stable. The approach is agnostic w.r.t. the used network architecture, input modality or viewpoint, and can be integrated into existing solutions easily.
Multimodal Future Localization and Emergence Prediction for Objects in Egocentric View with a Reachability Prior
Jun 08, 2020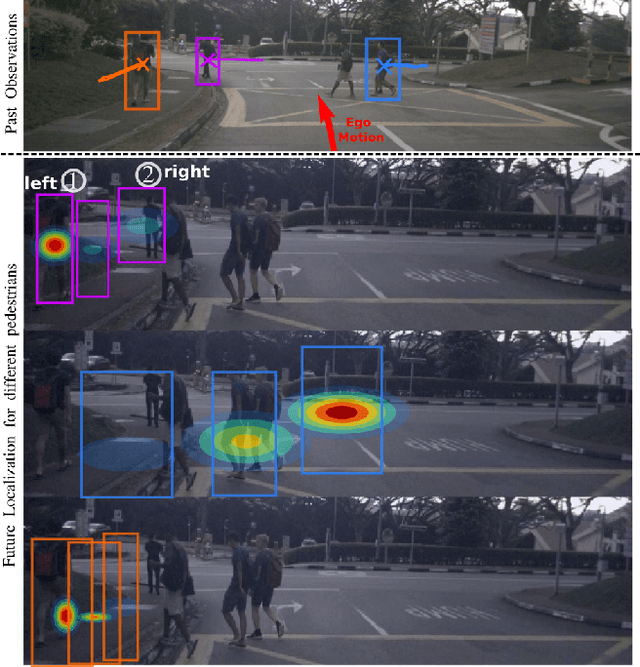

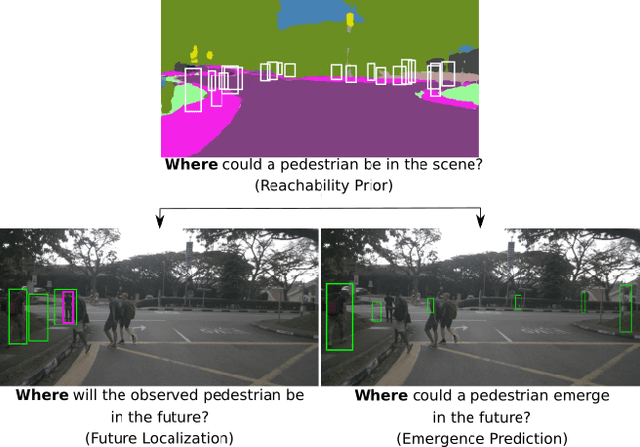

In this paper, we investigate the problem of anticipating future dynamics, particularly the future location of other vehicles and pedestrians, in the view of a moving vehicle. We approach two fundamental challenges: (1) the partial visibility due to the egocentric view with a single RGB camera and considerable field-of-view change due to the egomotion of the vehicle; (2) the multimodality of the distribution of future states. In contrast to many previous works, we do not assume structural knowledge from maps. We rather estimate a reachability prior for certain classes of objects from the semantic map of the present image and propagate it into the future using the planned egomotion. Experiments show that the reachability prior combined with multi-hypotheses learning improves multimodal prediction of the future location of tracked objects and, for the first time, the emergence of new objects. We also demonstrate promising zero-shot transfer to unseen datasets. Source code is available at $\href{https://github.com/lmb-freiburg/FLN-EPN-RPN}{\text{this https URL.}}$
Overcoming Limitations of Mixture Density Networks: A Sampling and Fitting Framework for Multimodal Future Prediction
Jun 09, 2019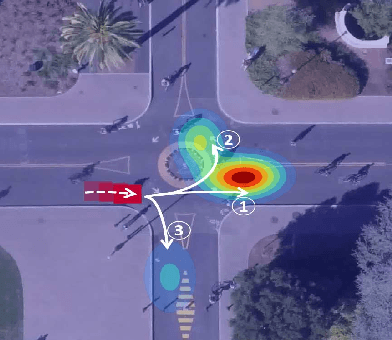
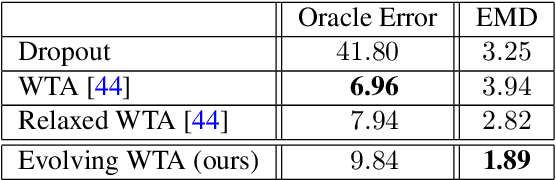
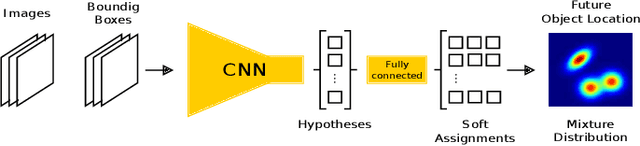
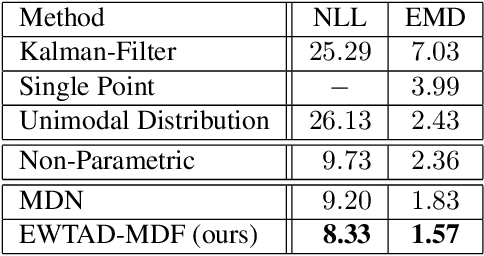
Future prediction is a fundamental principle of intelligence that helps plan actions and avoid possible dangers. As the future is uncertain to a large extent, modeling the uncertainty and multimodality of the future states is of great relevance. Existing approaches are rather limited in this regard and mostly yield a single hypothesis of the future or, at the best, strongly constrained mixture components that suffer from instabilities in training and mode collapse. In this work, we present an approach that involves the prediction of several samples of the future with a winner-takes-all loss and iterative grouping of samples to multiple modes. Moreover, we discuss how to evaluate predicted multimodal distributions, including the common real scenario, where only a single sample from the ground-truth distribution is available for evaluation. We show on synthetic and real data that the proposed approach triggers good estimates of multimodal distributions and avoids mode collapse.
FusionNet and AugmentedFlowNet: Selective Proxy Ground Truth for Training on Unlabeled Images
Aug 20, 2018



Recent work has shown that convolutional neural networks (CNNs) can be used to estimate optical flow with high quality and fast runtime. This makes them preferable for real-world applications. However, such networks require very large training datasets. Engineering the training data is difficult and/or laborious. This paper shows how to augment a network trained on an existing synthetic dataset with large amounts of additional unlabelled data. In particular, we introduce a selection mechanism to assemble from multiple estimates a joint optical flow field, which outperforms that of all input methods. The latter can be used as proxy-ground-truth to train a network on real-world data and to adapt it to specific domains of interest. Our experimental results show that the performance of networks improves considerably, both, in cross-domain and in domain-specific scenarios. As a consequence, we obtain state-of-the-art results on the KITTI benchmarks.
Uncertainty Estimates and Multi-Hypotheses Networks for Optical Flow
Aug 06, 2018



Optical flow estimation can be formulated as an end-to-end supervised learning problem, which yields estimates with a superior accuracy-runtime tradeoff compared to alternative methodology. In this paper, we make such networks estimate their local uncertainty about the correctness of their prediction, which is vital information when building decisions on top of the estimations. For the first time we compare several strategies and techniques to estimate uncertainty in a large-scale computer vision task like optical flow estimation. Moreover, we introduce a new network architecture and loss function that enforce complementary hypotheses and provide uncertainty estimates efficiently with a single forward pass and without the need for sampling or ensembles. We demonstrate the quality of the uncertainty estimates, which is clearly above previous confidence measures on optical flow and allows for interactive frame rates.
End-to-End Learning of Video Super-Resolution with Motion Compensation
Jul 03, 2017



Learning approaches have shown great success in the task of super-resolving an image given a low resolution input. Video super-resolution aims for exploiting additionally the information from multiple images. Typically, the images are related via optical flow and consecutive image warping. In this paper, we provide an end-to-end video super-resolution network that, in contrast to previous works, includes the estimation of optical flow in the overall network architecture. We analyze the usage of optical flow for video super-resolution and find that common off-the-shelf image warping does not allow video super-resolution to benefit much from optical flow. We rather propose an operation for motion compensation that performs warping from low to high resolution directly. We show that with this network configuration, video super-resolution can benefit from optical flow and we obtain state-of-the-art results on the popular test sets. We also show that the processing of whole images rather than independent patches is responsible for a large increase in accuracy.