 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Exposing the Challenging Long Tail in Future Prediction of Traffic Actors
Mar 24, 2021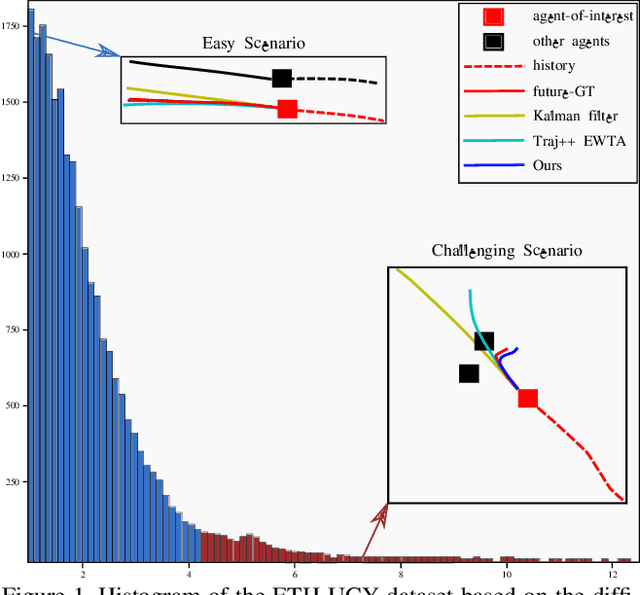
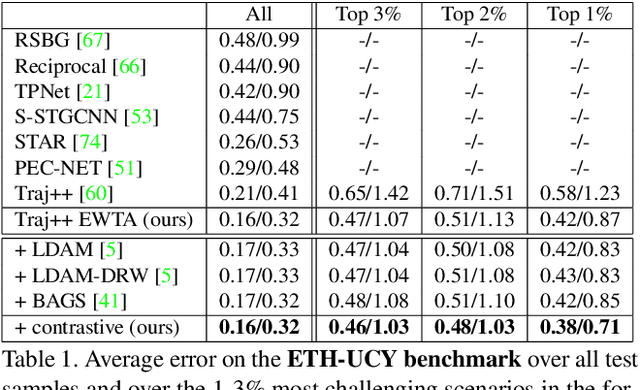
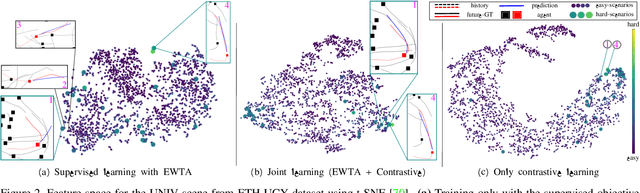
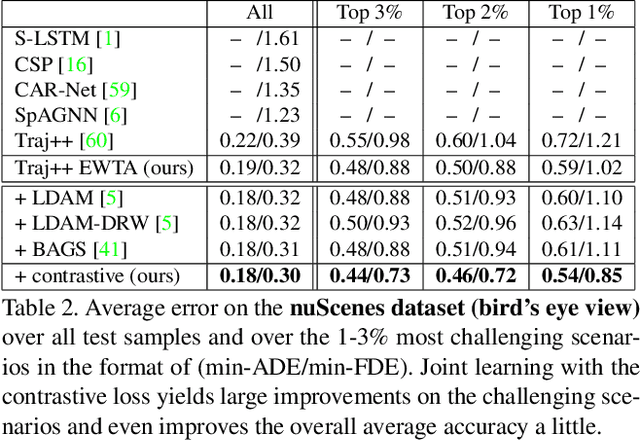
Predicting the states of dynamic traffic actors into the future is important for autonomous systems to operate safelyand efficiently. Remarkably, the most critical scenarios aremuch less frequent and more complex than the uncriticalones. Therefore, uncritical cases dominate the prediction. In this paper, we address specifically the challenging scenarios at the long tail of the dataset distribution. Our analysis shows that the common losses tend to place challenging cases suboptimally in the embedding space. As a consequence, we propose to supplement the usual loss with aloss that places challenging cases closer to each other. This triggers sharing information among challenging cases andlearning specific predictive features. We show on four public datasets that this leads to improved performance on the challenging scenarios while the overall performance stays stable. The approach is agnostic w.r.t. the used network architecture, input modality or viewpoint, and can be integrated into existing solutions easily.
Multimodal Future Localization and Emergence Prediction for Objects in Egocentric View with a Reachability Prior
Jun 08, 2020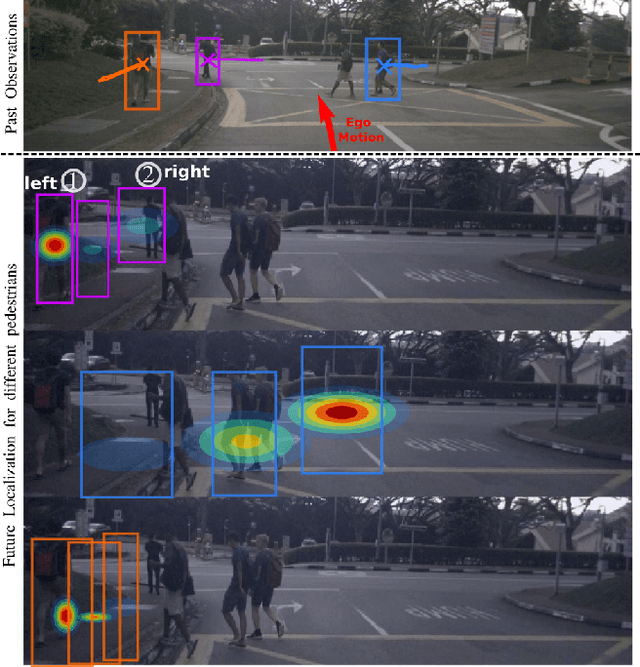

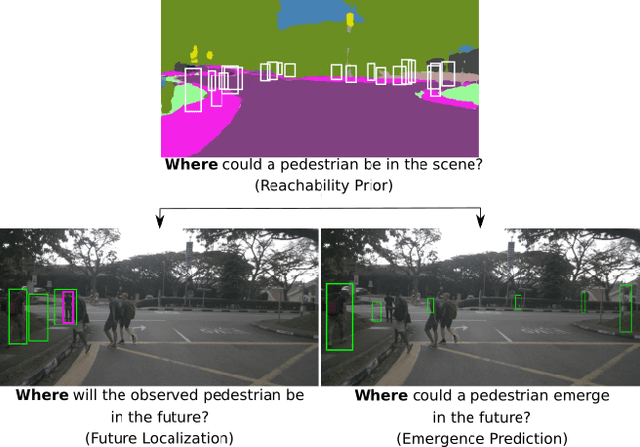

In this paper, we investigate the problem of anticipating future dynamics, particularly the future location of other vehicles and pedestrians, in the view of a moving vehicle. We approach two fundamental challenges: (1) the partial visibility due to the egocentric view with a single RGB camera and considerable field-of-view change due to the egomotion of the vehicle; (2) the multimodality of the distribution of future states. In contrast to many previous works, we do not assume structural knowledge from maps. We rather estimate a reachability prior for certain classes of objects from the semantic map of the present image and propagate it into the future using the planned egomotion. Experiments show that the reachability prior combined with multi-hypotheses learning improves multimodal prediction of the future location of tracked objects and, for the first time, the emergence of new objects. We also demonstrate promising zero-shot transfer to unseen datasets. Source code is available at $\href{https://github.com/lmb-freiburg/FLN-EPN-RPN}{\text{this https URL.}}$
Overcoming Limitations of Mixture Density Networks: A Sampling and Fitting Framework for Multimodal Future Prediction
Jun 09, 2019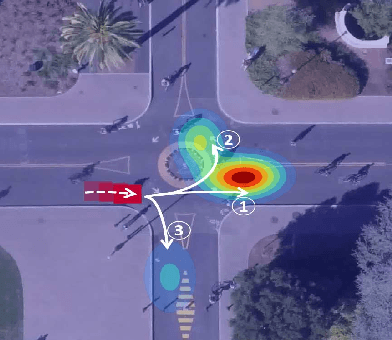
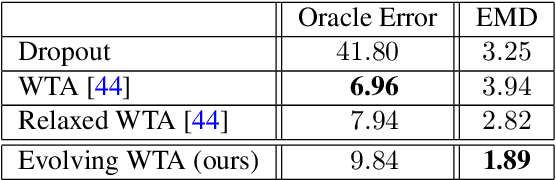
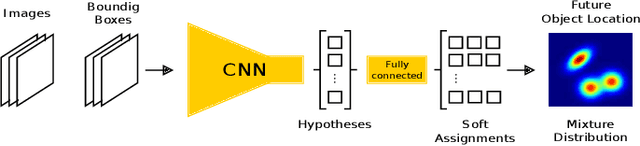
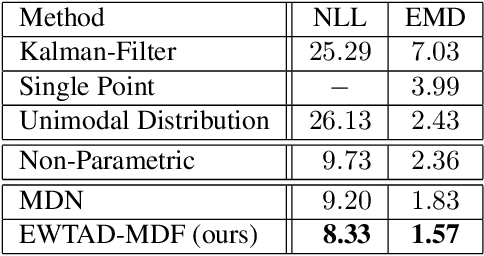
Future prediction is a fundamental principle of intelligence that helps plan actions and avoid possible dangers. As the future is uncertain to a large extent, modeling the uncertainty and multimodality of the future states is of great relevance. Existing approaches are rather limited in this regard and mostly yield a single hypothesis of the future or, at the best, strongly constrained mixture components that suffer from instabilities in training and mode collapse. In this work, we present an approach that involves the prediction of several samples of the future with a winner-takes-all loss and iterative grouping of samples to multiple modes. Moreover, we discuss how to evaluate predicted multimodal distributions, including the common real scenario, where only a single sample from the ground-truth distribution is available for evaluation. We show on synthetic and real data that the proposed approach triggers good estimates of multimodal distributions and avoids mode collapse.