Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discriminative Learning of Sounds for Audio Event Classification
Paper and Code
May 20, 2021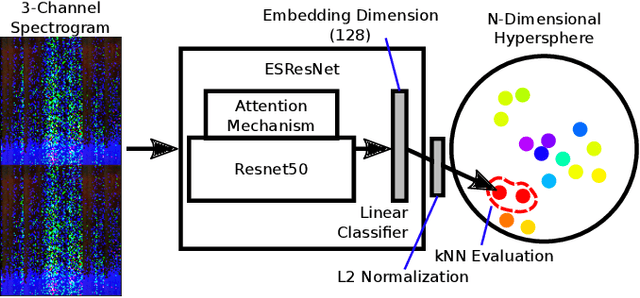
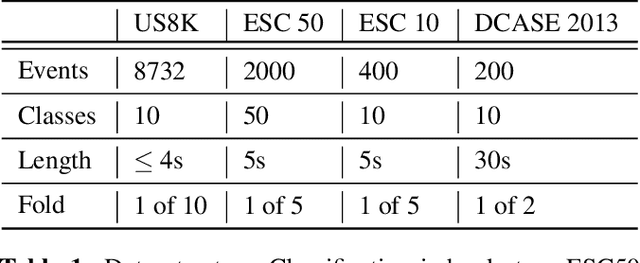
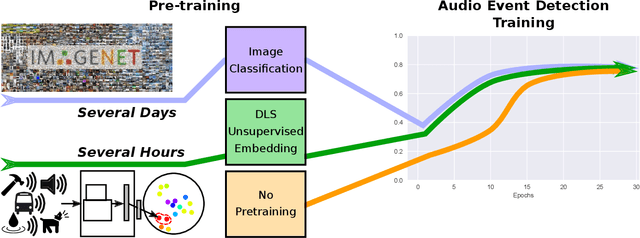

Recent progress in network-based audio event classification has shown the benefit of pre-training models on visual data such as ImageNet. While this process allows knowledge transfer across different domains, training a model on large-scale visual datasets is time consuming. On several audio event classification benchmarks, we show a fast and effective alternative that pre-trains the model unsupervised, only on audio data and yet delivers on-par performance with ImageNet pre-training. Furthermore, we show that our discriminative audio learning can be used to transfer knowledge across audio datasets and optionally include ImageNet pre-training.
* ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech
and Signal Processing (ICASSP) | 978-1-7281-7605-5/20/$31.00 (c) 2021 IEEE |
DOI: 10.1109/ICASSP39728.2021.9413482
View paper on