 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Attention Model for Weakly Labeled Audio Event Classification
Paper and Code
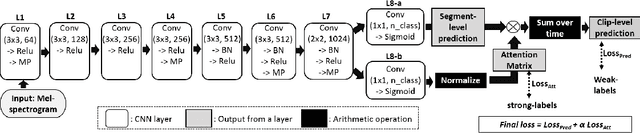

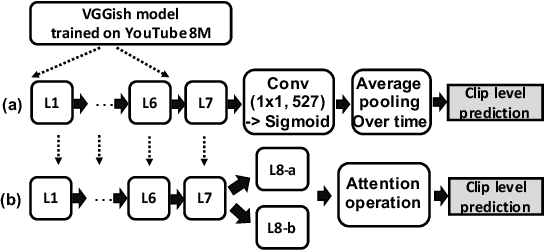
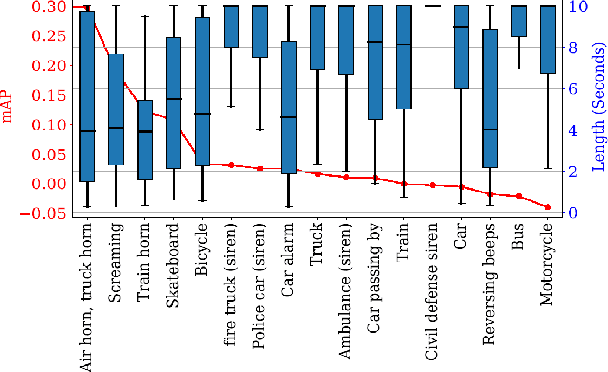
We describe a novel weakly labeled Audio Event Classification approach based on a self-supervised attention model. The weakly labeled framework is used to eliminate the need for expensive data labeling procedure and self-supervised attention is deployed to help a model distinguish between relevant and irrelevant parts of a weakly labeled audio clip in a more effective manner compared to prior attention models. We also propose a highly effective strongly supervised attention model when strong labels are available. This model also serves as an upper bound for the self-supervised model. The performances of the model with self-supervised attention training are comparable to the strongly supervised one which is trained using strong labels. We show that our self-supervised attention method is especially beneficial for short audio events. We achieve 8.8% and 17.6% relative mean average precision improvements over the current state-of-the-art systems for SL-DCASE-17 and balanced AudioSet.