 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSynth: Multi-Agent Metadata Generation from Implicit Feedback in Black-Box Systems
Oct 01, 2025Meta titles and descriptions strongly shape engagement in search and recommendation platforms, yet optimizing them remains challenging. Search engine ranking models are black box environments, explicit labels are unavailable, and feedback such as click-through rate (CTR) arrives only post-deployment. Existing template, LLM, and retrieval-augmented approaches either lack diversity, hallucinate attributes, or ignore whether candidate phrasing has historically succeeded in ranking. This leaves a gap in directly leveraging implicit signals from observable outcomes. We introduce MetaSynth, a multi-agent retrieval-augmented generation framework that learns from implicit search feedback. MetaSynth builds an exemplar library from top-ranked results, generates candidate snippets conditioned on both product content and exemplars, and iteratively refines outputs via evaluator-generator loops that enforce relevance, promotional strength, and compliance. On both proprietary e-commerce data and the Amazon Reviews corpus, MetaSynth outperforms strong baselines across NDCG, MRR, and rank metrics. Large-scale A/B tests further demonstrate 10.26% CTR and 7.51% clicks. Beyond metadata, this work contributes a general paradigm for optimizing content in black-box systems using implicit signals.
Two vs. Four-Channel Sound Event Localization and Detection
Sep 23, 2023Sound event localization and detection (SELD) systems estimate both the direction-of-arrival (DOA) and class of sound sources over time. In the DCASE 2022 SELD Challenge (Task 3), models are designed to operate in a 4-channel setting. While beneficial to further the development of SELD systems using a multichannel recording setup such as first-order Ambisonics (FOA), most consumer electronics devices rarely are able to record using more than two channels. For this reason, in this work we investigate the performance of the DCASE 2022 SELD baseline model using three audio input representations: FOA, binaural, and stereo. We perform a novel comparative analysis illustrating the effect of these audio input representations on SELD performance. Crucially, we show that binaural and stereo (i.e. 2-channel) audio-based SELD models are still able to localize and detect sound sources laterally quite well, despite overall performance degrading as less audio information is provided. Further, we segment our analysis by scenes containing varying degrees of sound source polyphony to better understand the effect of audio input representation on localization and detection performance as scene conditions become increasingly complex.
Discovering Phonetic Inventories with Crosslingual Automatic Speech Recognition
Jan 28, 2022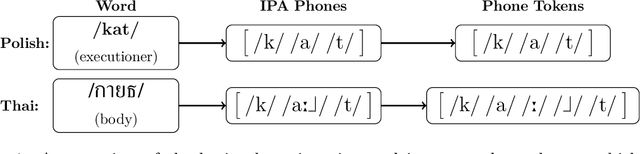
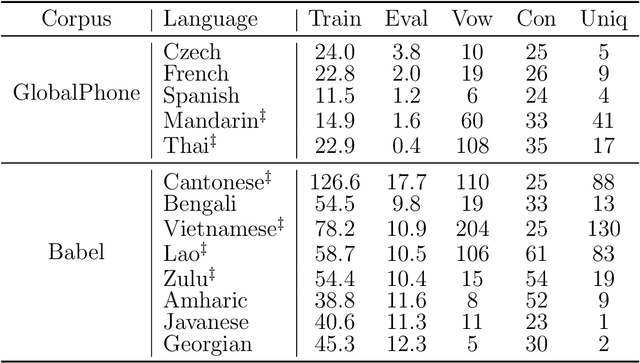
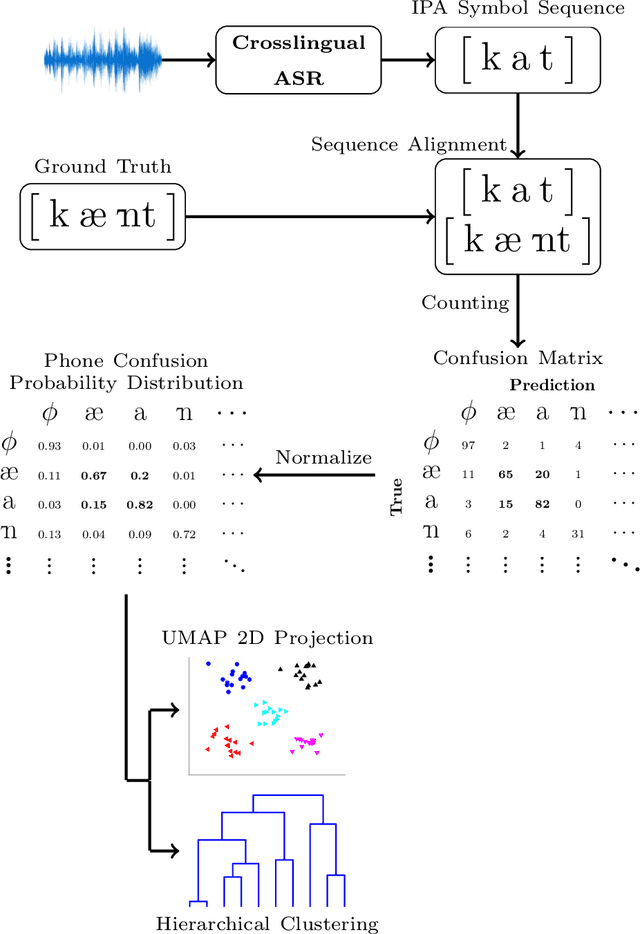
The high cost of data acquisition makes Automatic Speech Recognition (ASR) model training problematic for most existing languages, including languages that do not even have a written script, or for which the phone inventories remain unknown. Past works explored multilingual training, transfer learning, as well as zero-shot learning in order to build ASR systems for these low-resource languages. While it has been shown that the pooling of resources from multiple languages is helpful, we have not yet seen a successful application of an ASR model to a language unseen during training. A crucial step in the adaptation of ASR from seen to unseen languages is the creation of the phone inventory of the unseen language. The ultimate goal of our work is to build the phone inventory of a language unseen during training in an unsupervised way without any knowledge about the language. In this paper, we 1) investigate the influence of different factors (i.e., model architecture, phonotactic model, type of speech representation) on phone recognition in an unknown language; 2) provide an analysis of which phones transfer well across languages and which do not in order to understand the limitations of and areas for further improvement for automatic phone inventory creation; and 3) present different methods to build a phone inventory of an unseen language in an unsupervised way. To that end, we conducted mono-, multi-, and crosslingual experiments on a set of 13 phonetically diverse languages and several in-depth analyses. We found a number of universal phone tokens (IPA symbols) that are well-recognized cross-linguistically. Through a detailed analysis of results, we conclude that unique sounds, similar sounds, and tone languages remain a major challenge for phonetic inventory discovery.
How Phonotactics Affect Multilingual and Zero-shot ASR Performance
Oct 22, 2020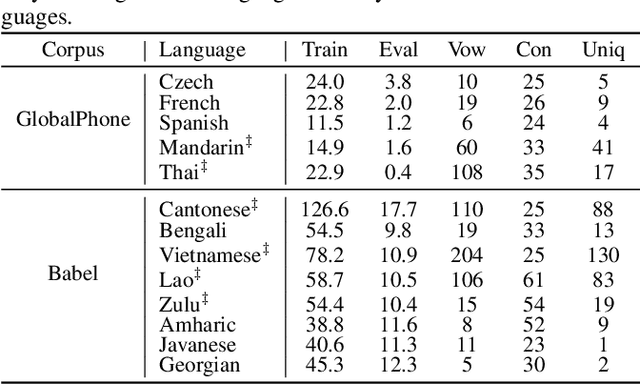
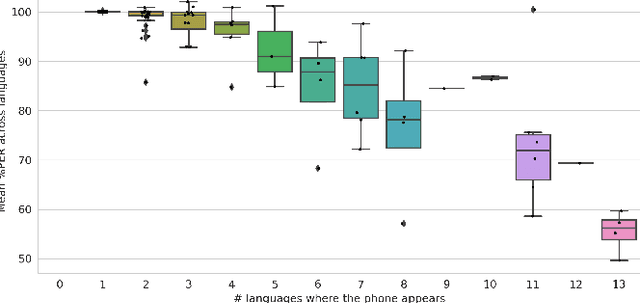
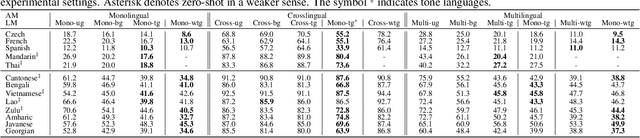
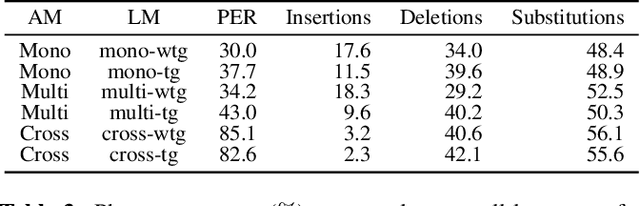
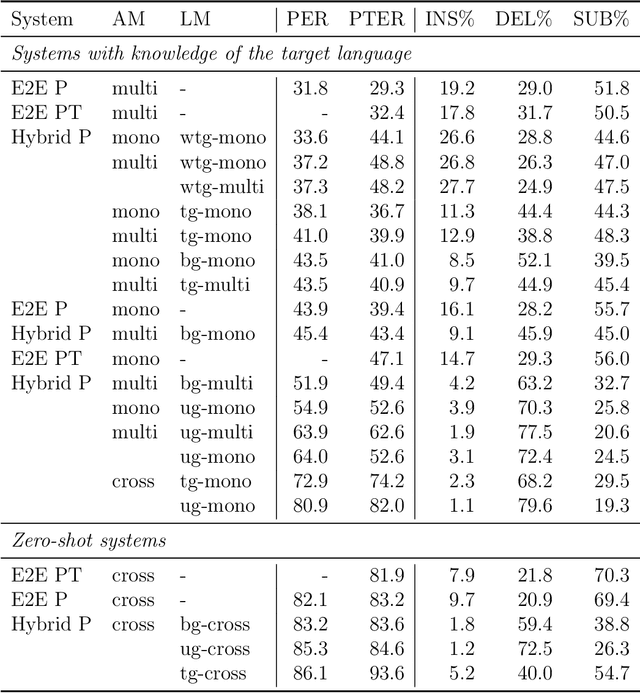
The idea of combining multiple languages' recordings to train a single automatic speech recognition (ASR) model brings the promise of the emergence of universal speech representation. Recently, a Transformer encoder-decoder model has been shown to leverage multilingual data well in IPA transcriptions of languages presented during training. However, the representations it learned were not successful in zero-shot transfer to unseen languages. Because that model lacks an explicit factorization of the acoustic model (AM) and language model (LM), it is unclear to what degree the performance suffered from differences in pronunciation or the mismatch in phonotactics. To gain more insight into the factors limiting zero-shot ASR transfer, we replace the encoder-decoder with a hybrid ASR system consisting of a separate AM and LM. Then, we perform an extensive evaluation of monolingual, multilingual, and crosslingual (zero-shot) acoustic and language models on a set of 13 phonetically diverse languages. We show that the gain from modeling crosslingual phonotactics is limited, and imposing a too strong model can hurt the zero-shot transfer. Furthermore, we find that a multilingual LM hurts a multilingual ASR system's performance, and retaining only the target language's phonotactic data in LM training is preferable.
Automatic Estimation of Inteligibility Measure for Consonants in Speech
May 12, 2020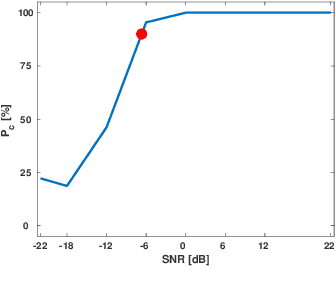
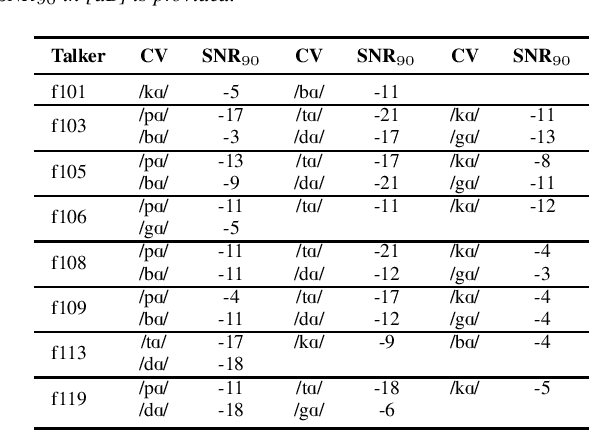


In this article, we provide a model to estimate a real-valued measure of the intelligibility of individual speech segments. We trained regression models based on Convolutional Neural Networks (CNN) for stop consonants \textipa{/p,t,k,b,d,g/} associated with vowel \textipa{/A/}, to estimate the corresponding Signal to Noise Ratio (SNR) at which the Consonant-Vowel (CV) sound becomes intelligible for Normal Hearing (NH) ears. The intelligibility measure for each sound is called SNR$_{90}$, and is defined to be the SNR level at which human participants are able to recognize the consonant at least 90\% correctly, on average, as determined in prior experiments with NH subjects. Performance of the CNN is compared to a baseline prediction based on automatic speech recognition (ASR), specifically, a constant offset subtracted from the SNR at which the ASR becomes capable of correctly labeling the consonant. Compared to baseline, our models were able to accurately estimate the SNR$_{90}$~intelligibility measure with less than 2 [dB$^2$] Mean Squared Error (MSE) on average, while the baseline ASR-defined measure computes SNR$_{90}$~with a variance of 5.2 to 26.6 [dB$^2$], depending on the consonant.