 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Estimation of Inteligibility Measure for Consonants in Speech
Paper and Code
May 12, 2020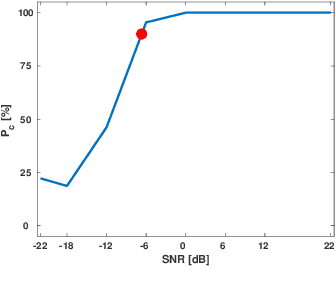
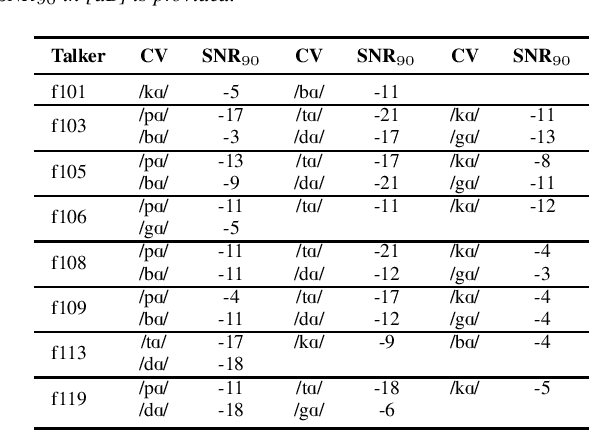


In this article, we provide a model to estimate a real-valued measure of the intelligibility of individual speech segments. We trained regression models based on Convolutional Neural Networks (CNN) for stop consonants \textipa{/p,t,k,b,d,g/} associated with vowel \textipa{/A/}, to estimate the corresponding Signal to Noise Ratio (SNR) at which the Consonant-Vowel (CV) sound becomes intelligible for Normal Hearing (NH) ears. The intelligibility measure for each sound is called SNR$_{90}$, and is defined to be the SNR level at which human participants are able to recognize the consonant at least 90\% correctly, on average, as determined in prior experiments with NH subjects. Performance of the CNN is compared to a baseline prediction based on automatic speech recognition (ASR), specifically, a constant offset subtracted from the SNR at which the ASR becomes capable of correctly labeling the consonant. Compared to baseline, our models were able to accurately estimate the SNR$_{90}$~intelligibility measure with less than 2 [dB$^2$] Mean Squared Error (MSE) on average, while the baseline ASR-defined measure computes SNR$_{90}$~with a variance of 5.2 to 26.6 [dB$^2$], depending on the consonant.