 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Aware Early Fusion of Acoustic and Linguistic Embeddings for Cognitive Status Classification
Jan 30, 2026Speech contains both acoustic and linguistic patterns that reflect cognitive decline, and therefore models describing only one domain cannot fully capture such complexity. This study investigates how early fusion (EF) of speech and its corresponding transcription text embeddings, with attention to encoder layer depth, can improve cognitive status classification. Using a DementiaBank-derived collection of recordings (1,629 speakers; cognitively normal controls$\unicode{x2013}$CN, Mild Cognitive Impairment$\unicode{x2013}$MCI, and Alzheimer's Disease and Related Dementias$\unicode{x2013}$ADRD), we extracted frame-aligned embeddings from different internal layers of wav2vec 2.0 or Whisper combined with DistilBERT or RoBERTa. Unimodal, EF and late fusion (LF) models were trained with a transformer classifier, optimized, and then evaluated across 10 seeds. Performance consistently peaked in mid encoder layers ($\sim$8$\unicode{x2013}$10), with the single best F1 at Whisper + RoBERTa layer 9 and the best log loss at Whisper + DistilBERT layer 10. Acoustic-only models consistently outperformed text-only variants. EF boosts discrimination for genuinely acoustic embeddings, whereas LF improves probability calibration. Layer choice critically shapes clinical multimodal synergy.
Self-FiLM: Conditioning GANs with self-supervised representations for bandwidth extension based speaker recognition
Mar 07, 2023



Speech super-resolution/Bandwidth Extension (BWE) can improve downstream tasks like Automatic Speaker Verification (ASV). We introduce a simple novel technique called Self-FiLM to inject self-supervision into existing BWE models via Feature-wise Linear Modulation. We hypothesize that such information captures domain/environment information, which can give zero-shot generalization. Self-FiLM Conditional GAN (CGAN) gives 18% relative improvement in Equal Error Rate and 8.5% in minimum Decision Cost Function using state-of-the-art ASV system on SRE21 test. We further by 1) deep feature loss from time-domain models and 2) re-training of data2vec 2.0 models on naturalistic wideband (VoxCeleb) and telephone data (SRE Superset etc.). Lastly, we integrate self-supervision with CycleGAN to present a completely unsupervised solution that matches the semi-supervised performance.
Time-domain speech super-resolution with GAN based modeling for telephony speaker verification
Sep 04, 2022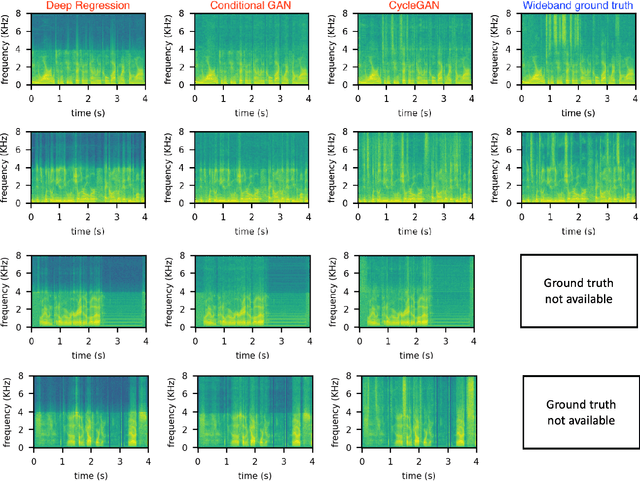
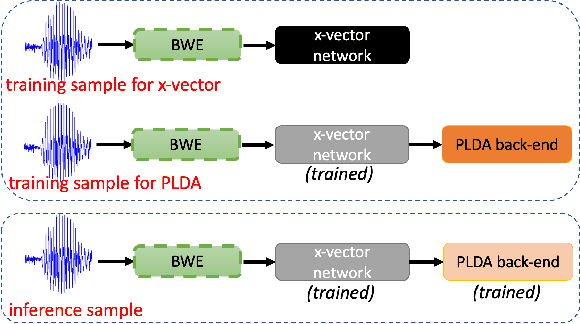
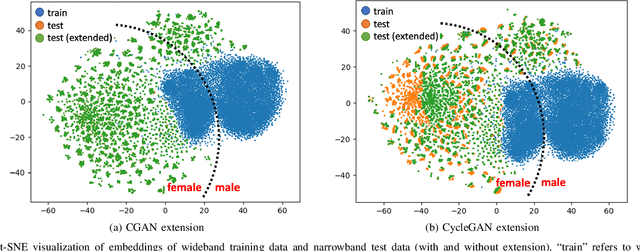
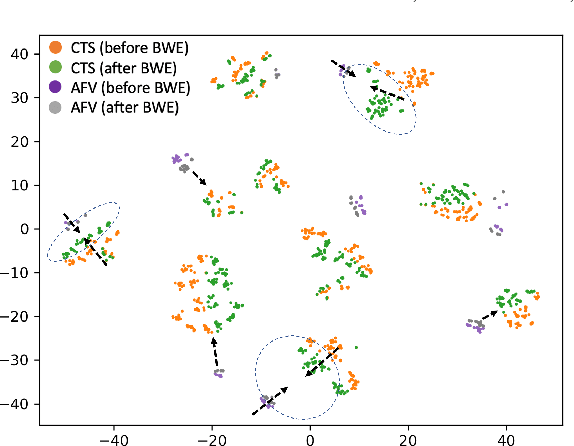
Automatic Speaker Verification (ASV) technology has become commonplace in virtual assistants. However, its performance suffers when there is a mismatch between the train and test domains. Mixed bandwidth training, i.e., pooling training data from both domains, is a preferred choice for developing a universal model that works for both narrowband and wideband domains. We propose complementing this technique by performing neural upsampling of narrowband signals, also known as bandwidth extension. Our main goal is to discover and analyze high-performing time-domain Generative Adversarial Network (GAN) based models to improve our downstream state-of-the-art ASV system. We choose GANs since they (1) are powerful for learning conditional distribution and (2) allow flexible plug-in usage as a pre-processor during the training of downstream task (ASV) with data augmentation. Prior works mainly focus on feature-domain bandwidth extension and limited experimental setups. We address these limitations by 1) using time-domain extension models, 2) reporting results on three real test sets, 2) extending training data, and 3) devising new test-time schemes. We compare supervised (conditional GAN) and unsupervised GANs (CycleGAN) and demonstrate average relative improvement in Equal Error Rate of 8.6% and 7.7%, respectively. For further analysis, we study changes in spectrogram visual quality, audio perceptual quality, t-SNE embeddings, and ASV score distributions. We show that our bandwidth extension leads to phenomena such as a shift of telephone (test) embeddings towards wideband (train) signals, a negative correlation of perceptual quality with downstream performance, and condition-independent score calibration.
Joint domain adaptation and speech bandwidth extension using time-domain GANs for speaker verification
Mar 30, 2022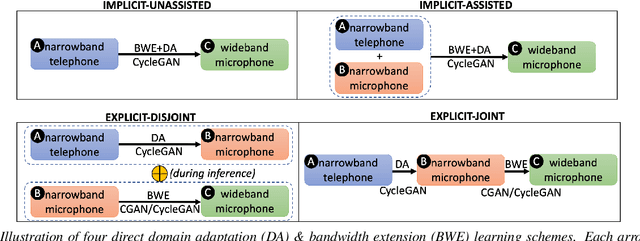
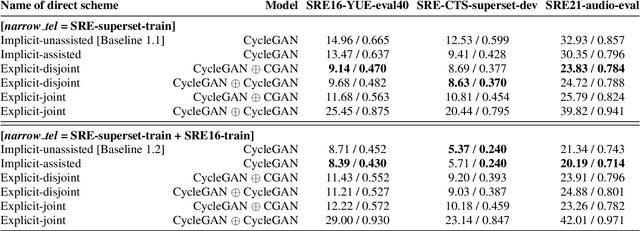
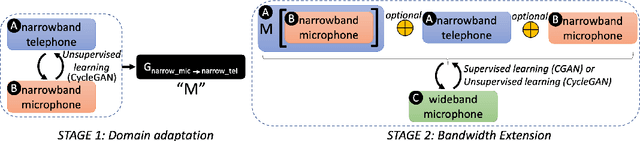

Speech systems developed for a particular choice of acoustic domain and sampling frequency do not translate easily to others. The usual practice is to learn domain adaptation and bandwidth extension models independently. Contrary to this, we propose to learn both tasks together. Particularly, we learn to map narrowband conversational telephone speech to wideband microphone speech. We developed parallel and non-parallel learning solutions which utilize both paired and unpaired data. First, we first discuss joint and disjoint training of multiple generative models for our tasks. Then, we propose a two-stage learning solution where we use a pre-trained domain adaptation system for pre-processing in bandwidth extension training. We evaluated our schemes on a Speaker Verification downstream task. We used the JHU-MIT experimental setup for NIST SRE21, which comprises SRE16, SRE-CTS Superset and SRE21. Our results provide the first evidence that learning both tasks is better than learning just one. On SRE16, our best system achieves 22% relative improvement in Equal Error Rate w.r.t. a direct learning baseline and 8% w.r.t. a strong bandwidth expansion system.
Deep Feature CycleGANs: Speaker Identity Preserving Non-parallel Microphone-Telephone Domain Adaptation for Speaker Verification
Apr 03, 2021

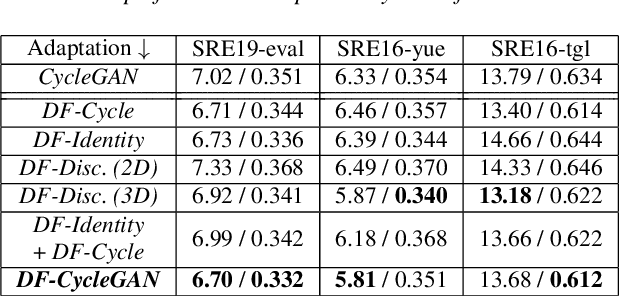
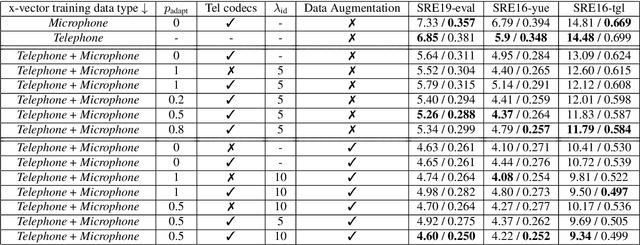
With the increase in the availability of speech from varied domains, it is imperative to use such out-of-domain data to improve existing speech systems. Domain adaptation is a prominent pre-processing approach for this. We investigate it for adapt microphone speech to the telephone domain. Specifically, we explore CycleGAN-based unpaired translation of microphone data to improve the x-vector/speaker embedding network for Telephony Speaker Verification. We first demonstrate the efficacy of this on real challenging data and then, to improve further, we modify the CycleGAN formulation to make the adaptation task-specific. We modify CycleGAN's identity loss, cycle-consistency loss, and adversarial loss to operate in the deep feature space. Deep features of a signal are extracted from an auxiliary (speaker embedding) network and, hence, preserves speaker identity. Our 3D convolution-based Deep Feature Discriminators (DFD) show relative improvements of 5-10% in terms of equal error rate. To dive deeper, we study a challenging scenario of pooling (adapted) microphone and telephone data with data augmentations and telephone codecs. Finally, we highlight the sensitivity of CycleGAN hyper-parameters and introduce a parameter called probability of adaptation.
Unsupervised Acoustic Unit Discovery by Leveraging a Language-Independent Subword Discriminative Feature Representation
Apr 02, 2021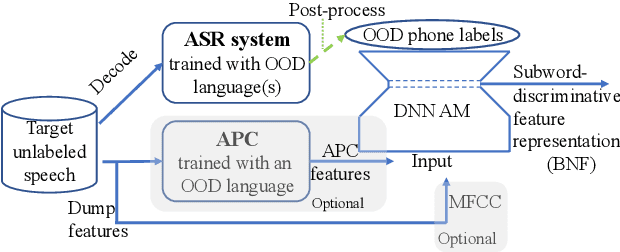
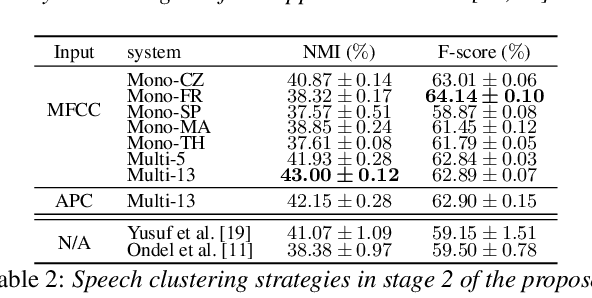
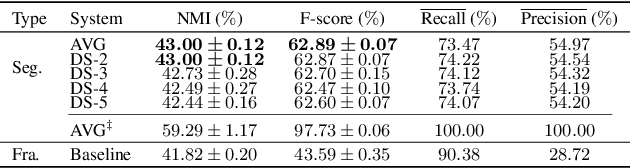
This paper tackles automatically discovering phone-like acoustic units (AUD) from unlabeled speech data. Past studies usually proposed single-step approaches. We propose a two-stage approach: the first stage learns a subword-discriminative feature representation and the second stage applies clustering to the learned representation and obtains phone-like clusters as the discovered acoustic units. In the first stage, a recently proposed method in the task of unsupervised subword modeling is improved by replacing a monolingual out-of-domain (OOD) ASR system with a multilingual one to create a subword-discriminative representation that is more language-independent. In the second stage, segment-level k-means is adopted, and two methods to represent the variable-length speech segments as fixed-dimension feature vectors are compared. Experiments on a very low-resource Mboshi language corpus show that our approach outperforms state-of-the-art AUD in both normalized mutual information (NMI) and F-score. The multilingual ASR improved upon the monolingual ASR in providing OOD phone labels and in estimating the phone boundaries. A comparison of our systems with and without knowing the ground-truth phone boundaries showed a 16% NMI performance gap, suggesting that the current approach can significantly benefit from improved phone boundary estimation.
Adversarial Attacks and Defenses for Speaker Identification Systems
Jan 22, 2021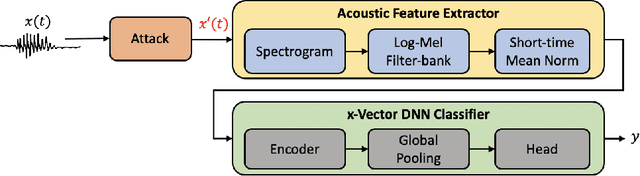
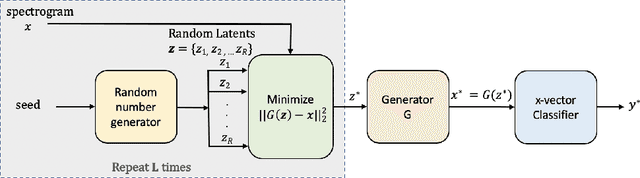

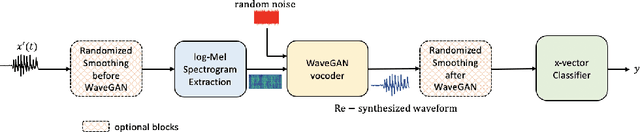
Research in automatic speaker recognition (SR) has been undertaken for several decades, reaching great performance. However, researchers discovered potential loopholes in these technologies like spoofing attacks. Quite recently, a new genre of attack, termed adversarial attacks, has been proved to be fatal in computer vision and it is vital to study their effects on SR systems. This paper examines how state-of-the-art speaker identification (SID) systems are vulnerable to adversarial attacks and how to defend against them. We investigated adversarial attacks common in the literature like fast gradient sign method (FGSM), iterative-FGSM / basic iterative method (BIM) and Carlini-Wagner (CW). Furthermore, we propose four pre-processing defenses against these attacks - randomized smoothing, DefenseGAN, variational autoencoder (VAE) and WaveGAN vocoder. We found that SID is extremely vulnerable under Iterative FGSM and CW attacks. Randomized smoothing defense robustified the system for imperceptible BIM and CW attacks recovering classification accuracies ~97%. Defenses based on generative models (DefenseGAN, VAE and WaveGAN) project adversarial examples (outside manifold) back into the clean manifold. In the case that attacker cannot adapt the attack to the defense (black-box defense), WaveGAN performed the best, being close to clean condition (Accuracy>97%). However, if the attack is adapted to the defense - assuming the attacker has access to the defense model (white-box defense), VAE and WaveGAN protection dropped significantly-50% and 37% accuracy for CW attack. To counteract this,we combined randomized smoothing with VAE or WaveGAN. We found that smoothing followed by WaveGAN vocoder was the most effective defense overall. As a black-box defense, it provides 93% average accuracy. As white-box defense, accuracy only degraded for iterative attacks with perceptible perturbations (L>=0.01).
How Phonotactics Affect Multilingual and Zero-shot ASR Performance
Oct 22, 2020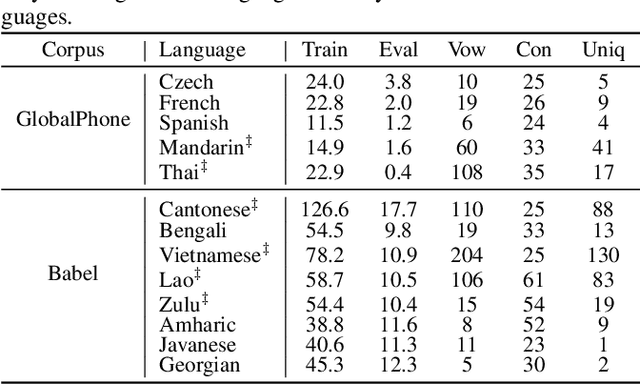
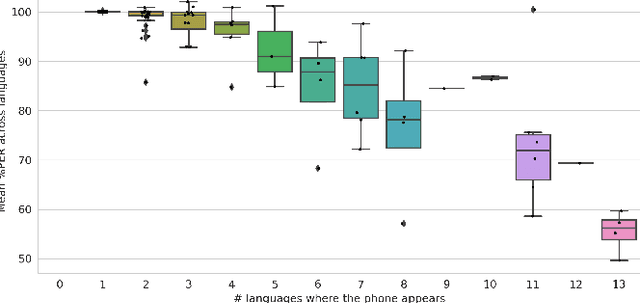
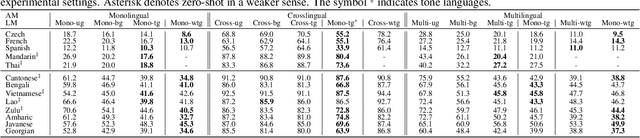
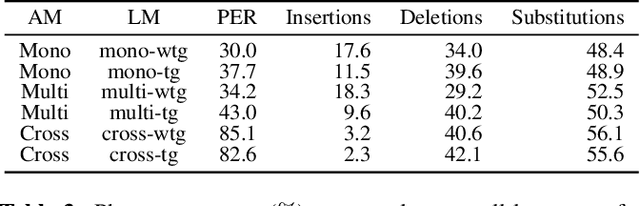
The idea of combining multiple languages' recordings to train a single automatic speech recognition (ASR) model brings the promise of the emergence of universal speech representation. Recently, a Transformer encoder-decoder model has been shown to leverage multilingual data well in IPA transcriptions of languages presented during training. However, the representations it learned were not successful in zero-shot transfer to unseen languages. Because that model lacks an explicit factorization of the acoustic model (AM) and language model (LM), it is unclear to what degree the performance suffered from differences in pronunciation or the mismatch in phonotactics. To gain more insight into the factors limiting zero-shot ASR transfer, we replace the encoder-decoder with a hybrid ASR system consisting of a separate AM and LM. Then, we perform an extensive evaluation of monolingual, multilingual, and crosslingual (zero-shot) acoustic and language models on a set of 13 phonetically diverse languages. We show that the gain from modeling crosslingual phonotactics is limited, and imposing a too strong model can hurt the zero-shot transfer. Furthermore, we find that a multilingual LM hurts a multilingual ASR system's performance, and retaining only the target language's phonotactic data in LM training is preferable.
That Sounds Familiar: an Analysis of Phonetic Representations Transfer Across Languages
May 16, 2020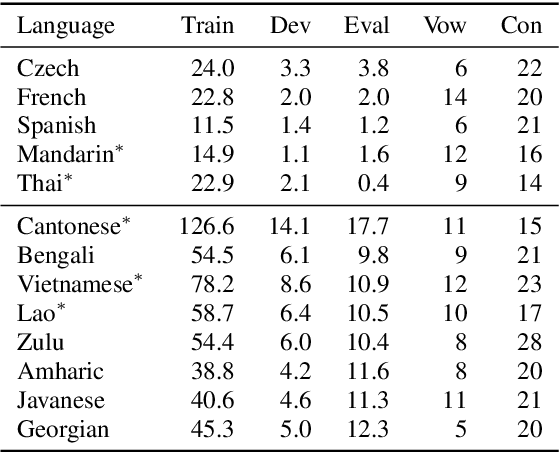
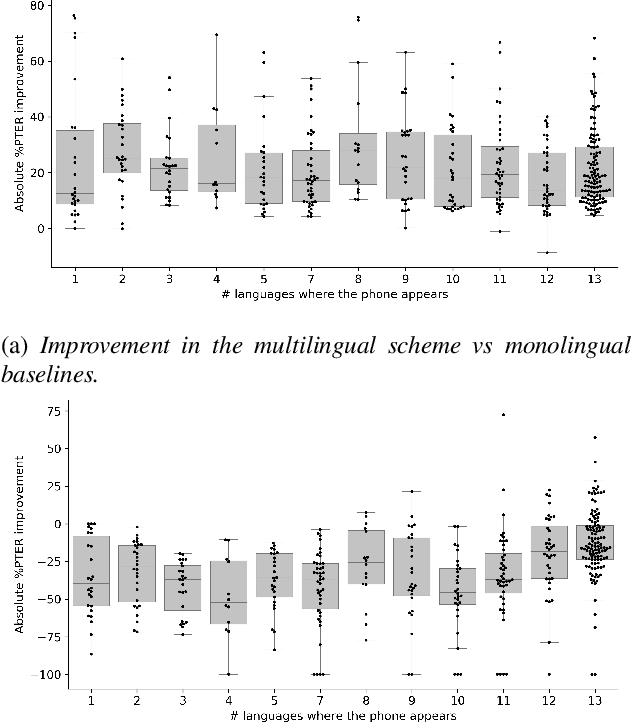
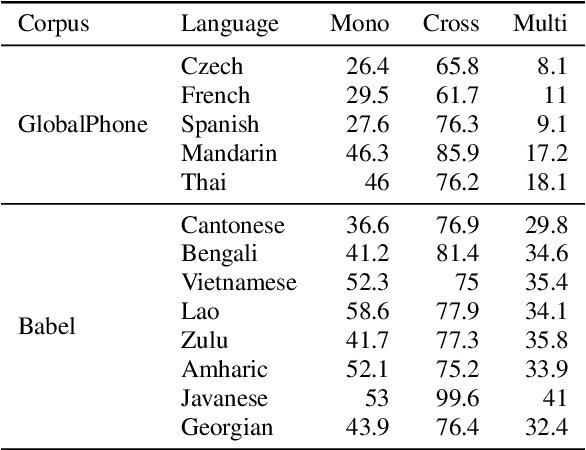
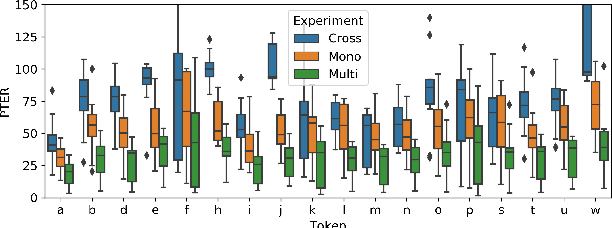
Only a handful of the world's languages are abundant with the resources that enable practical applications of speech processing technologies. One of the methods to overcome this problem is to use the resources existing in other languages to train a multilingual automatic speech recognition (ASR) model, which, intuitively, should learn some universal phonetic representations. In this work, we focus on gaining a deeper understanding of how general these representations might be, and how individual phones are getting improved in a multilingual setting. To that end, we select a phonetically diverse set of languages, and perform a series of monolingual, multilingual and crosslingual (zero-shot) experiments. The ASR is trained to recognize the International Phonetic Alphabet (IPA) token sequences. We observe significant improvements across all languages in the multilingual setting, and stark degradation in the crosslingual setting, where the model, among other errors, considers Javanese as a tone language. Notably, as little as 10 hours of the target language training data tremendously reduces ASR error rates. Our analysis uncovered that even the phones that are unique to a single language can benefit greatly from adding training data from other languages - an encouraging result for the low-resource speech community.