 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSS: Synthesizing long Digital Ink using Data augmentation, Style encoding and Split generation
Nov 29, 2023As text generative models can give increasingly long answers, we tackle the problem of synthesizing long text in digital ink. We show that the commonly used models for this task fail to generalize to long-form data and how this problem can be solved by augmenting the training data, changing the model architecture and the inference procedure. These methods use contrastive learning technique and are tailored specifically for the handwriting domain. They can be applied to any encoder-decoder model that works with digital ink. We demonstrate that our method reduces the character error rate on long-form English data by half compared to baseline RNN and by 16% compared to the previous approach that aims at addressing the same problem. We show that all three parts of the method improve recognizability of generated inks. In addition, we evaluate synthesized data in a human study and find that people perceive most of generated data as real.
Sampling and Ranking for Digital Ink Generation on a tight computational budget
Jun 02, 2023

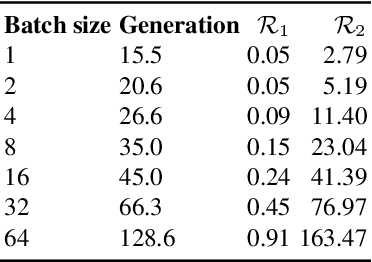

Digital ink (online handwriting) generation has a number of potential applications for creating user-visible content, such as handwriting autocompletion, spelling correction, and beautification. Writing is personal and usually the processing is done on-device. Ink generative models thus need to produce high quality content quickly, in a resource constrained environment. In this work, we study ways to maximize the quality of the output of a trained digital ink generative model, while staying within an inference time budget. We use and compare the effect of multiple sampling and ranking techniques, in the first ablation study of its kind in the digital ink domain. We confirm our findings on multiple datasets - writing in English and Vietnamese, as well as mathematical formulas - using two model types and two common ink data representations. In all combinations, we report a meaningful improvement in the recognizability of the synthetic inks, in some cases more than halving the character error rate metric, and describe a way to select the optimal combination of sampling and ranking techniques for any given computational budget.
Can we learn gradients by Hamiltonian Neural Networks?
Oct 31, 2021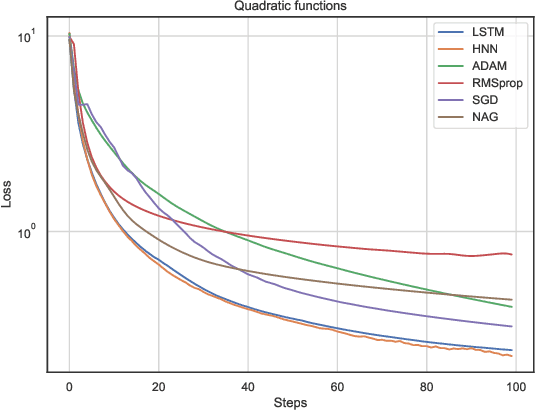
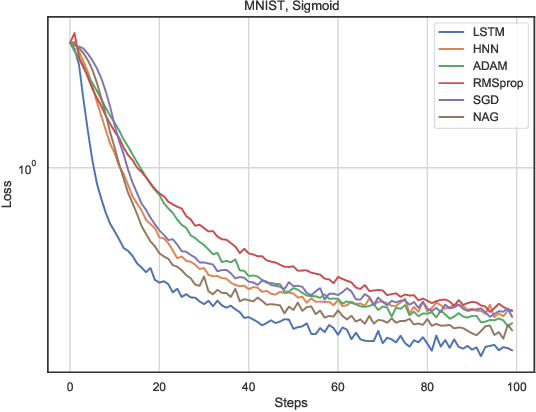
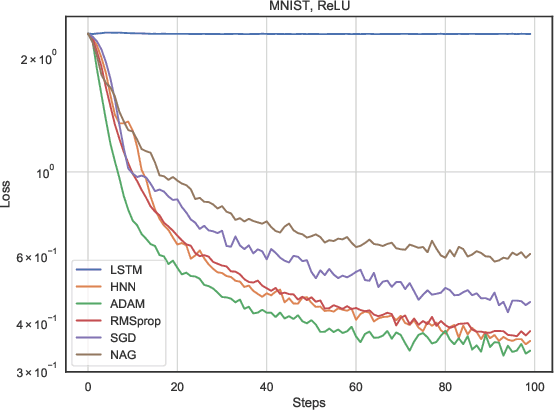
In this work, we propose a meta-learner based on ODE neural networks that learns gradients. This approach makes the optimizer is more flexible inducing an automatic inductive bias to the given task. Using the simplest Hamiltonian Neural Network we demonstrate that our method outperforms a meta-learner based on LSTM for an artificial task and the MNIST dataset with ReLU activations in the optimizee. Furthermore, it also surpasses the classic optimization methods for the artificial task and achieves comparable results for MNIST.
Self-Supervised Neural Architecture Search for Imbalanced Datasets
Sep 20, 2021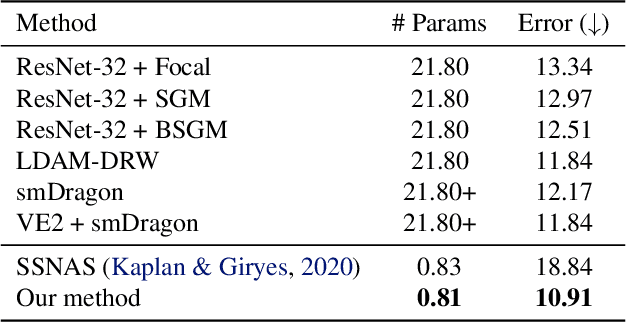
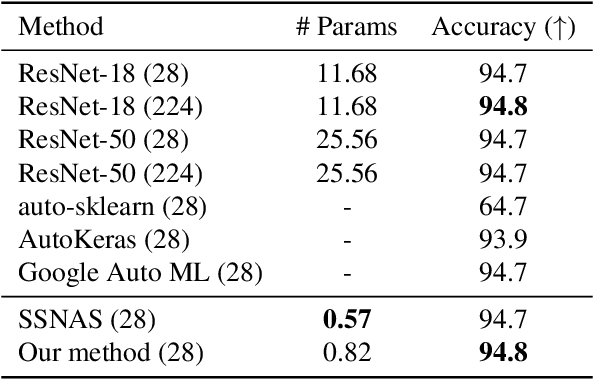
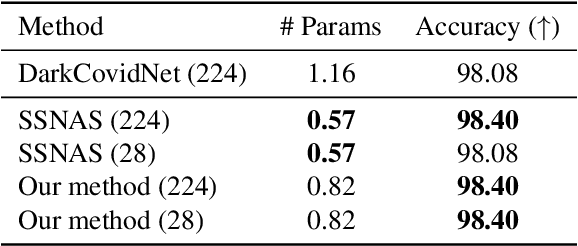
Neural Architecture Search (NAS) provides state-of-the-art results when trained on well-curated datasets with annotated labels. However, annotating data or even having balanced number of samples can be a luxury for practitioners from different scientific fields, e.g., in the medical domain. To that end, we propose a NAS-based framework that bears the threefold contributions: (a) we focus on the self-supervised scenario, i.e., where no labels are required to determine the architecture, and (b) we assume the datasets are imbalanced, (c) we design each component to be able to run on a resource constrained setup, i.e., on a single GPU (e.g. Google Colab). Our components build on top of recent developments in self-supervised learning~\citep{zbontar2021barlow}, self-supervised NAS~\citep{kaplan2020self} and extend them for the case of imbalanced datasets. We conduct experiments on an (artificially) imbalanced version of CIFAR-10 and we demonstrate our proposed method outperforms standard neural networks, while using $27\times$ less parameters. To validate our assumption on a naturally imbalanced dataset, we also conduct experiments on ChestMNIST and COVID-19 X-ray. The results demonstrate how the proposed method can be used in imbalanced datasets, while it can be fully run on a single GPU. Code is available \href{https://github.com/TimofeevAlex/ssnas_imbalanced}{here}.