 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Universal Perception Encoder
Mar 23, 2026Running AI models on smart edge devices can unlock versatile user experiences, but presents challenges due to limited compute and the need to handle multiple tasks simultaneously. This requires a vision encoder with small size but powerful and versatile representations. We present our method, Efficient Universal Perception Encoder (EUPE), which offers both inference efficiency and universally good representations for diverse downstream tasks. We achieve this by distilling from multiple domain-expert foundation vision encoders. Unlike previous agglomerative methods that directly scale down from multiple teachers to an efficient encoder, we demonstrate the importance of first scaling up to a large proxy teacher and then scaling down from this single teacher. Experiments show that EUPE achieves on-par or better performance than individual domain experts of the same size on diverse task domains and also outperforms previous agglomerative encoders. We will release the full family of EUPE models and the code to foster future research.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
Kronecker Recurrent Units
Dec 31, 2017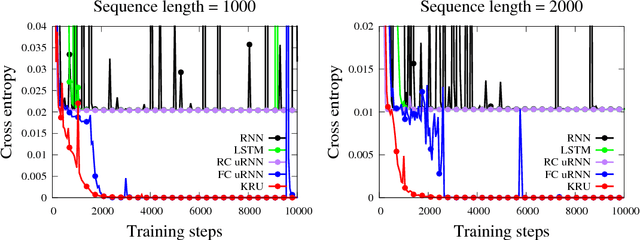
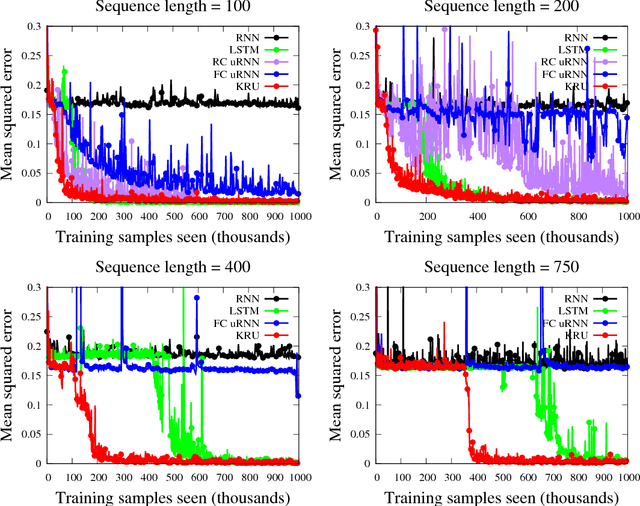
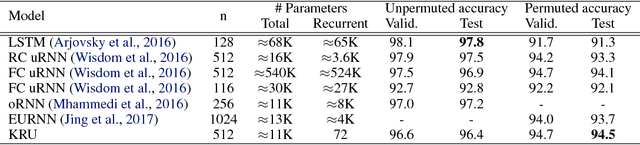
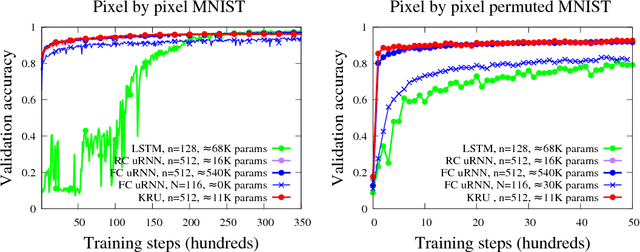
Our work addresses two important issues with recurrent neural networks: (1) they are over-parameterized, and (2) the recurrence matrix is ill-conditioned. The former increases the sample complexity of learning and the training time. The latter causes the vanishing and exploding gradient problem. We present a flexible recurrent neural network model called Kronecker Recurrent Units (KRU). KRU achieves parameter efficiency in RNNs through a Kronecker factored recurrent matrix. It overcomes the ill-conditioning of the recurrent matrix by enforcing soft unitary constraints on the factors. Thanks to the small dimensionality of the factors, maintaining these constraints is computationally efficient. Our experimental results on seven standard data-sets reveal that KRU can reduce the number of parameters by three orders of magnitude in the recurrent weight matrix compared to the existing recurrent models, without trading the statistical performance. These results in particular show that while there are advantages in having a high dimensional recurrent space, the capacity of the recurrent part of the model can be dramatically reduced.
The WILDTRACK Multi-Camera Person Dataset
Jul 28, 2017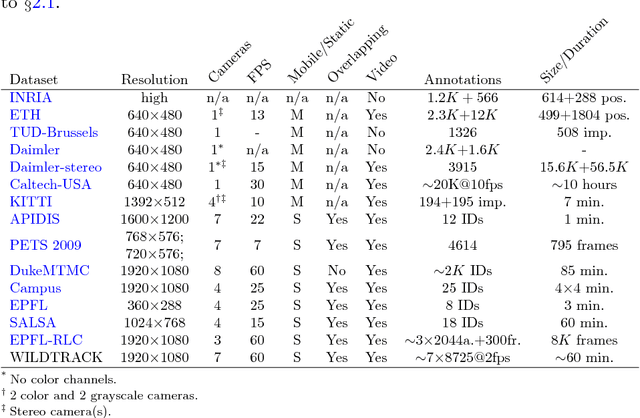


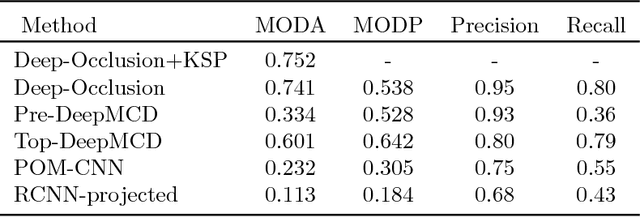
People detection methods are highly sensitive to the perpetual occlusions among the targets. As multi-camera set-ups become more frequently encountered, joint exploitation of the across views information would allow for improved detection performances. We provide a large-scale HD dataset named WILDTRACK which finally makes advanced deep learning methods applicable to this problem. The seven-static-camera set-up captures realistic and challenging scenarios of walking people. Notably, its camera calibration with jointly high-precision projection widens the range of algorithms which may make use of this dataset. In aim to help accelerate the research on automatic camera calibration, such annotations also accompany this dataset. Furthermore, the rich-in-appearance visual context of the pedestrian class makes this dataset attractive for monocular pedestrian detection as well, since: the HD cameras are placed relatively close to the people, and the size of the dataset further increases seven-fold. In summary, we overview existing multi-camera datasets and detection methods, enumerate details of our dataset, and we benchmark multi-camera state of the art detectors on this new dataset.
Scalable Metric Learning via Weighted Approximate Rank Component Analysis
Mar 23, 2016

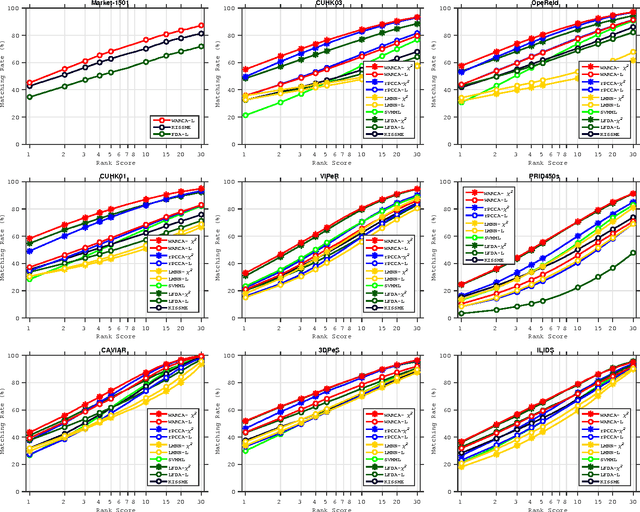
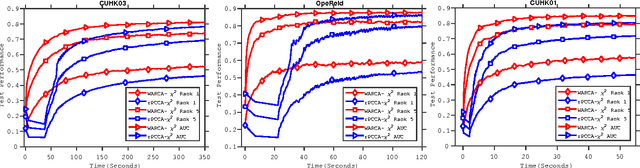
We are interested in the large-scale learning of Mahalanobis distances, with a particular focus on person re-identification. We propose a metric learning formulation called Weighted Approximate Rank Component Analysis (WARCA). WARCA optimizes the precision at top ranks by combining the WARP loss with a regularizer that favors orthonormal linear mappings, and avoids rank-deficient embeddings. Using this new regularizer allows us to adapt the large-scale WSABIE procedure and to leverage the Adam stochastic optimization algorithm, which results in an algorithm that scales gracefully to very large data-sets. Also, we derive a kernelized version which allows to take advantage of state-of-the-art features for re-identification when data-set size permits kernel computation. Benchmarks on recent and standard re-identification data-sets show that our method beats existing state-of-the-art techniques both in term of accuracy and speed. We also provide experimental analysis to shade lights on the properties of the regularizer we use, and how it improves performance.