 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Optimal Detector Design with Mutual Information Surrogates
Mar 18, 2025
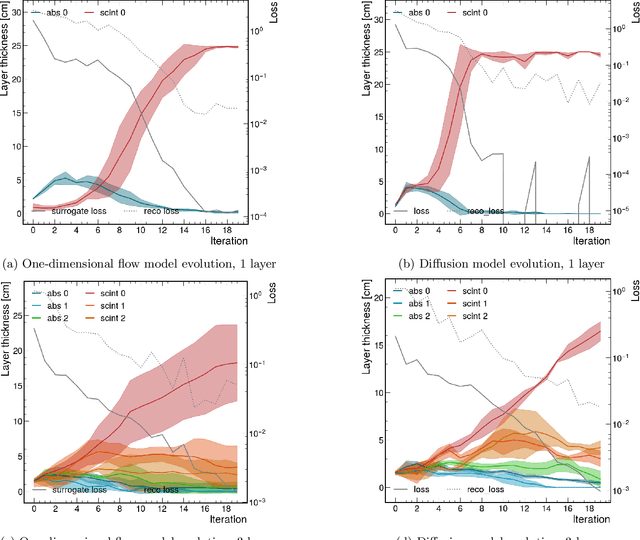
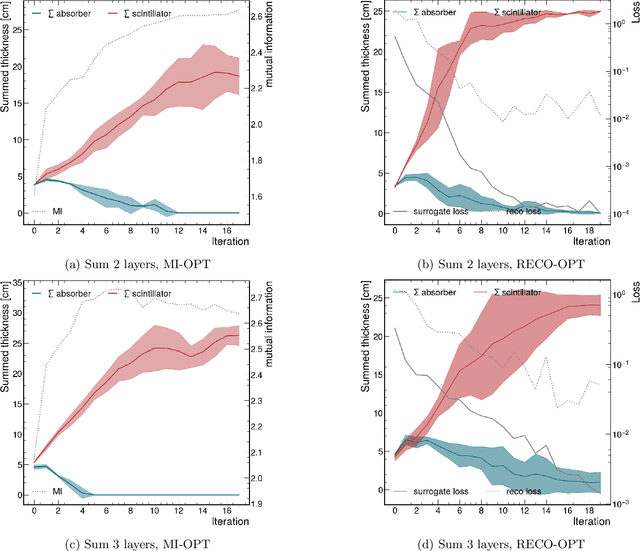
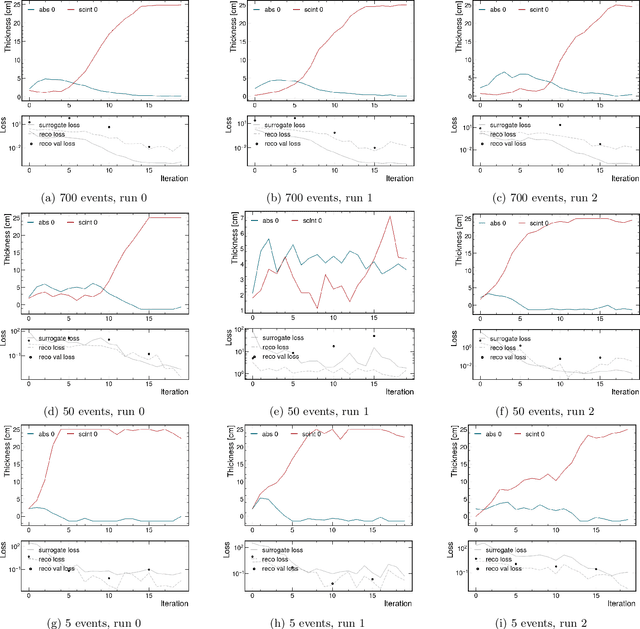
We introduce a novel approach for end-to-end black-box optimization of high energy physics (HEP) detectors using local deep learning (DL) surrogates. These surrogates approximate a scalar objective function that encapsulates the complex interplay of particle-matter interactions and physics analysis goals. In addition to a standard reconstruction-based metric commonly used in the field, we investigate the information-theoretic metric of mutual information. Unlike traditional methods, mutual information is inherently task-agnostic, offering a broader optimization paradigm that is less constrained by predefined targets. We demonstrate the effectiveness of our method in a realistic physics analysis scenario: optimizing the thicknesses of calorimeter detector layers based on simulated particle interactions. The surrogate model learns to approximate objective gradients, enabling efficient optimization with respect to energy resolution. Our findings reveal three key insights: (1) end-to-end black-box optimization using local surrogates is a practical and compelling approach for detector design, providing direct optimization of detector parameters in alignment with physics analysis goals; (2) mutual information-based optimization yields design choices that closely match those from state-of-the-art physics-informed methods, indicating that these approaches operate near optimality and reinforcing their reliability in HEP detector design; and (3) information-theoretic methods provide a powerful, generalizable framework for optimizing scientific instruments. By reframing the optimization process through an information-theoretic lens rather than domain-specific heuristics, mutual information enables the exploration of new avenues for discovery beyond conventional approaches.
LiNeS: Post-training Layer Scaling Prevents Forgetting and Enhances Model Merging
Oct 22, 2024Large pre-trained models exhibit impressive zero-shot performance across diverse tasks, but fine-tuning often leads to catastrophic forgetting, where improvements on a target domain degrade generalization on other tasks. To address this challenge, we introduce LiNeS, Layer-increasing Network Scaling, a post-training editing technique designed to preserve pre-trained generalization while enhancing fine-tuned task performance. LiNeS scales parameter updates linearly based on their layer depth within the network, maintaining shallow layers close to their pre-trained values to preserve general features while allowing deeper layers to retain task-specific representations. We further extend this approach to multi-task model merging scenarios, where layer-wise scaling of merged parameters reduces negative task interference. LiNeS demonstrates significant improvements in both single-task and multi-task settings across various benchmarks in vision and natural language processing. It mitigates forgetting, enhances out-of-distribution generalization, integrates seamlessly with existing multi-task model merging baselines improving their performance across benchmarks and model sizes, and can boost generalization when merging LLM policies aligned with different rewards via RLHF. Importantly, our method is simple to implement and complementary to many existing techniques.
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Jul 10, 2024



Dealing with multi-task trade-offs during inference can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front with a single model, contrary to traditional Multi-Task Learning (MTL) approaches that optimize for a single trade-off which has to be decided prior to training. However, recent PFL methodologies suffer from limited scalability, slow convergence and excessive memory requirements compared to MTL approaches while exhibiting inconsistent mappings from preference space to objective space. In this paper, we introduce PaLoRA, a novel parameter-efficient method that augments the original model with task-specific low-rank adapters and continuously parameterizes the Pareto Front in their convex hull. Our approach dedicates the original model and the adapters towards learning general and task-specific features, respectively. Additionally, we propose a deterministic sampling schedule of preference vectors that reinforces this division of labor, enabling faster convergence and scalability to real world networks. Our experimental results show that PaLoRA outperforms MTL and PFL baselines across various datasets, scales to large networks and provides a continuous parameterization of the Pareto Front, reducing the memory overhead $23.8-31.7$ times compared with competing PFL baselines in scene understanding benchmarks.
DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Averaging
Feb 04, 2024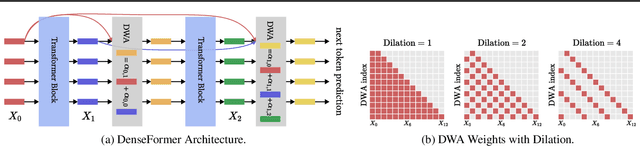
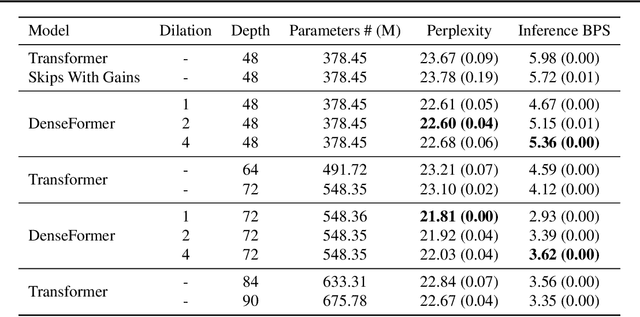
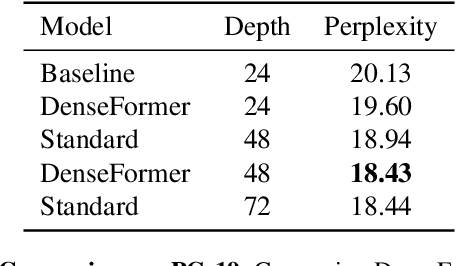
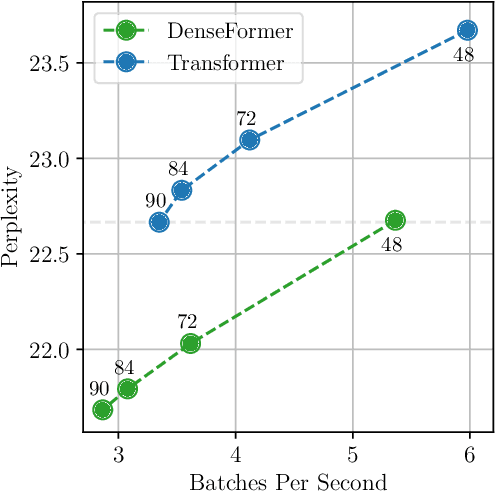
The transformer architecture from Vaswani et al. (2017) is now ubiquitous across application domains, from natural language processing to speech processing and image understanding. We propose DenseFormer, a simple modification to the standard architecture that improves the perplexity of the model without increasing its size -- adding a few thousand parameters for large-scale models in the 100B parameters range. Our approach relies on an additional averaging step after each transformer block, which computes a weighted average of current and past representations -- we refer to this operation as Depth-Weighted-Average (DWA). The learned DWA weights exhibit coherent patterns of information flow, revealing the strong and structured reuse of activations from distant layers. Experiments demonstrate that DenseFormer is more data efficient, reaching the same perplexity of much deeper transformer models, and that for the same perplexity, these new models outperform transformer baselines in terms of memory efficiency and inference time.
DeepEMD: A Transformer-based Fast Estimation of the Earth Mover's Distance
Nov 16, 2023



The Earth Mover's Distance (EMD) is the measure of choice between point clouds. However the computational cost to compute it makes it prohibitive as a training loss, and the standard approach is to use a surrogate such as the Chamfer distance. We propose an attention-based model to compute an accurate approximation of the EMD that can be used as a training loss for generative models. To get the necessary accurate estimation of the gradients we train our model to explicitly compute the matching between point clouds instead of EMD itself. We cast this new objective as the estimation of an attention matrix that approximates the ground truth matching matrix. Experiments show that this model provides an accurate estimate of the EMD and its gradient with a wall clock speed-up of more than two orders of magnitude with respect to the exact Hungarian matching algorithm and one order of magnitude with respect to the standard approximate Sinkhorn algorithm, allowing in particular to train a point cloud VAE with the EMD itself. Extensive evaluation show the remarkable behaviour of this model when operating out-of-distribution, a key requirement for a distance surrogate. Finally, the model generalizes very well to point clouds during inference several times larger than during training.
SequeL: A Continual Learning Library in PyTorch and JAX
Apr 21, 2023
Continual Learning is an important and challenging problem in machine learning, where models must adapt to a continuous stream of new data without forgetting previously acquired knowledge. While existing frameworks are built on PyTorch, the rising popularity of JAX might lead to divergent codebases, ultimately hindering reproducibility and progress. To address this problem, we introduce SequeL, a flexible and extensible library for Continual Learning that supports both PyTorch and JAX frameworks. SequeL provides a unified interface for a wide range of Continual Learning algorithms, including regularization-based approaches, replay-based approaches, and hybrid approaches. The library is designed towards modularity and simplicity, making the API suitable for both researchers and practitioners. We release SequeL\footnote{\url{https://github.com/nik-dim/sequel}} as an open-source library, enabling researchers and developers to easily experiment and extend the library for their own purposes.
Flatten the Curve: Efficiently Training Low-Curvature Neural Networks
Jun 14, 2022

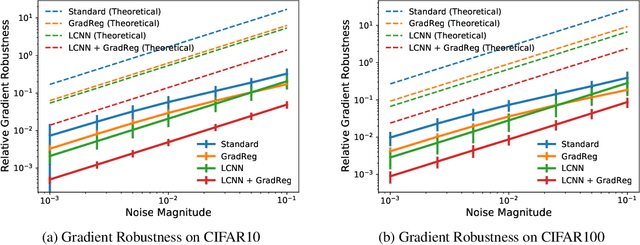
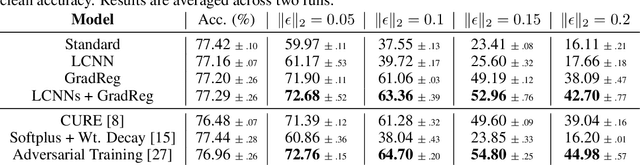
The highly non-linear nature of deep neural networks causes them to be susceptible to adversarial examples and have unstable gradients which hinders interpretability. However, existing methods to solve these issues, such as adversarial training, are expensive and often sacrifice predictive accuracy. In this work, we consider curvature, which is a mathematical quantity which encodes the degree of non-linearity. Using this, we demonstrate low-curvature neural networks (LCNNs) that obtain drastically lower curvature than standard models while exhibiting similar predictive performance, which leads to improved robustness and stable gradients, with only a marginally increased training time. To achieve this, we minimize a data-independent upper bound on the curvature of a neural network, which decomposes overall curvature in terms of curvatures and slopes of its constituent layers. To efficiently minimize this bound, we introduce two novel architectural components: first, a non-linearity called centered-softplus that is a stable variant of the softplus non-linearity, and second, a Lipschitz-constrained batch normalization layer. Our experiments show that LCNNs have lower curvature, more stable gradients and increased off-the-shelf adversarial robustness when compared to their standard high-curvature counterparts, all without affecting predictive performance. Our approach is easy to use and can be readily incorporated into existing neural network models.
HyperMixer: An MLP-based Green AI Alternative to Transformers
Mar 07, 2022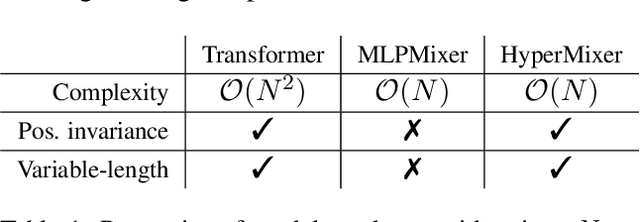
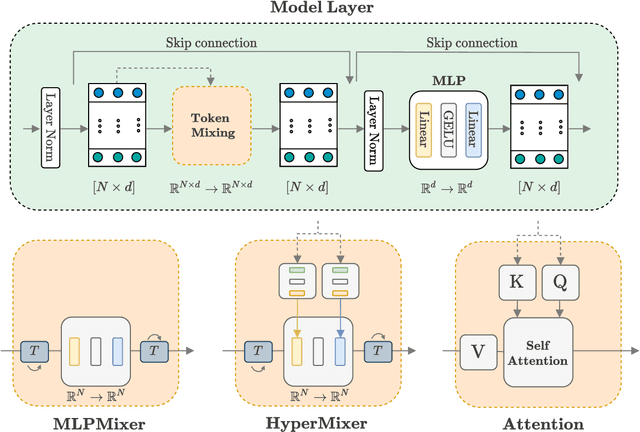
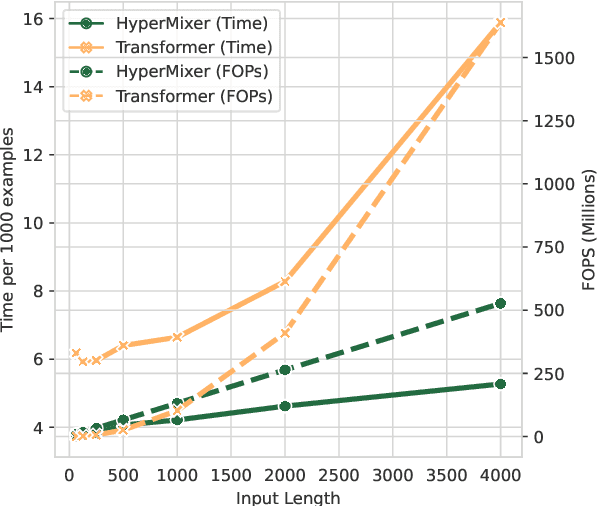
Transformer-based architectures are the model of choice for natural language understanding, but they come at a significant cost, as they have quadratic complexity in the input length and can be difficult to tune. In the pursuit of Green AI, we investigate simple MLP-based architectures. We find that existing architectures such as MLPMixer, which achieves token mixing through a static MLP applied to each feature independently, are too detached from the inductive biases required for natural language understanding. In this paper, we propose a simple variant, HyperMixer, which forms the token mixing MLP dynamically using hypernetworks. Empirically, we demonstrate that our model performs better than alternative MLP-based models, and on par with Transformers. In contrast to Transformers, HyperMixer achieves these results at substantially lower costs in terms of processing time, training data, and hyperparameter tuning.
Taming GANs with Lookahead
Jun 25, 2020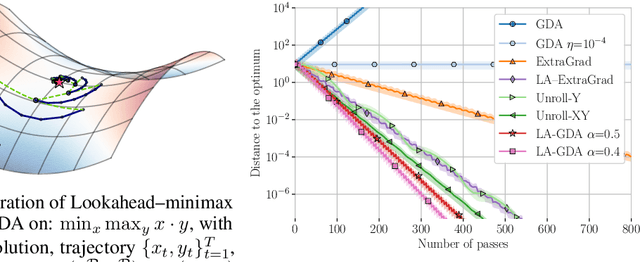
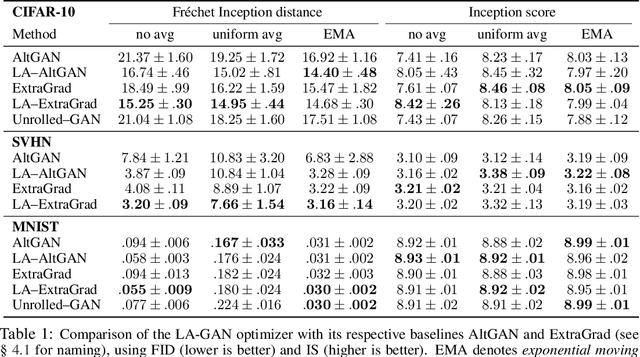


Generative Adversarial Networks are notoriously challenging to train. The underlying minimax optimization is highly susceptible to the variance of the stochastic gradient and the rotational component of the associated game vector field. We empirically demonstrate the effectiveness of the Lookahead meta-optimization method for optimizing games, originally proposed for standard minimization. The backtracking step of Lookahead naturally handles the rotational game dynamics, which in turn enables the gradient ascent descent method to converge on challenging toy games often analyzed in the literature. Moreover, it implicitly handles high variance without using large mini-batches, known to be essential for reaching state of the art performance. Experimental results on MNIST, SVHN, and CIFAR-10, demonstrate a clear advantage of combining Lookahead with Adam or extragradient, in terms of performance, memory footprint, and improved stability. Using 30-fold fewer parameters and 16-fold smaller minibatches we outperform the reported performance of the class-dependent BigGAN on CIFAR-10 by obtaining FID of $13.65$ \emph{without} using the class labels, bringing state-of-the-art GAN training within reach of common computational resources.
Gradient Alignment in Deep Neural Networks
Jun 16, 2020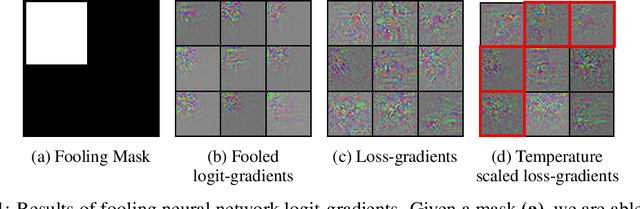

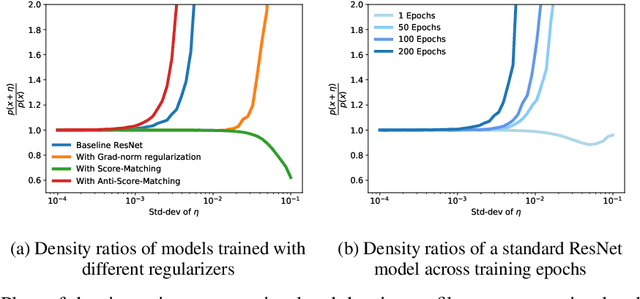

One cornerstone of interpretable deep learning is the high degree of visual alignment that input-gradients, i.e.,the gradients of the output w.r.t. inputs, exhibit with the input data. This alignment is assumed to arise as a result of the model's generalization, justifying its use for interpretability. However, recent work has shown that it is possible to 'fool' models into having arbitrary gradients while achieving good generalization, thus falsifying the assumption above. This leaves an open question: if not generalization, what causes input-gradients to align with input data? In this work, we first show that it is simple to 'fool' input-gradients using the shift-invariance property of softmax, and that gradient structure is unrelated to model generalization. Second, we re-interpret the logits of standard classifiers as unnormalized log-densities of the data distribution, and find that we can improve this gradient alignment via a generative modelling objective called score-matching.To show this, we derive a novel approximation to the score-matching objective that eliminates the need for expensive Hessian computations, which may be of independent interest.Our experiments help us identify one factor that causes input-gradient alignment in models, that being the approximate generative modelling behaviour of the normalized logit distributions.