 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Alignment in Deep Neural Networks
Paper and Code
Jun 16, 2020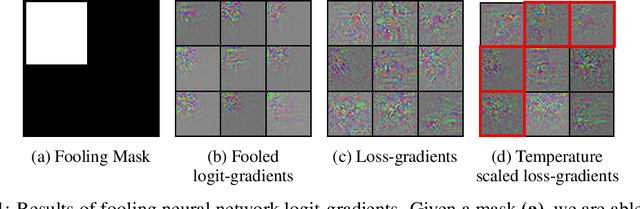

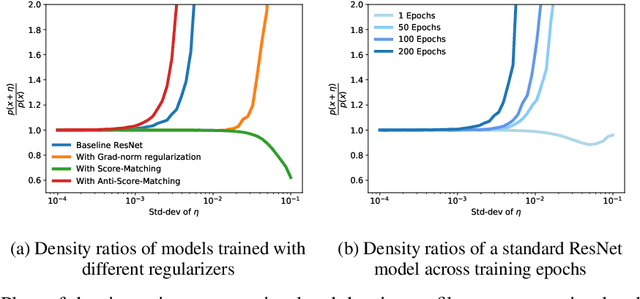

One cornerstone of interpretable deep learning is the high degree of visual alignment that input-gradients, i.e.,the gradients of the output w.r.t. inputs, exhibit with the input data. This alignment is assumed to arise as a result of the model's generalization, justifying its use for interpretability. However, recent work has shown that it is possible to 'fool' models into having arbitrary gradients while achieving good generalization, thus falsifying the assumption above. This leaves an open question: if not generalization, what causes input-gradients to align with input data? In this work, we first show that it is simple to 'fool' input-gradients using the shift-invariance property of softmax, and that gradient structure is unrelated to model generalization. Second, we re-interpret the logits of standard classifiers as unnormalized log-densities of the data distribution, and find that we can improve this gradient alignment via a generative modelling objective called score-matching.To show this, we derive a novel approximation to the score-matching objective that eliminates the need for expensive Hessian computations, which may be of independent interest.Our experiments help us identify one factor that causes input-gradient alignment in models, that being the approximate generative modelling behaviour of the normalized logit distributions.