 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming GANs with Lookahead
Paper and Code
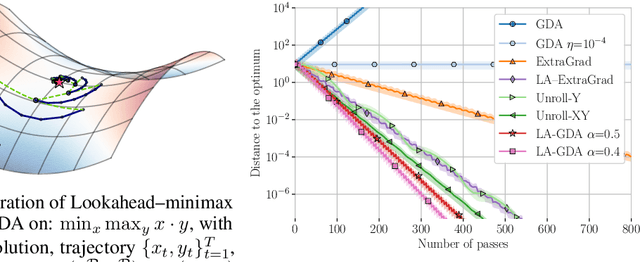
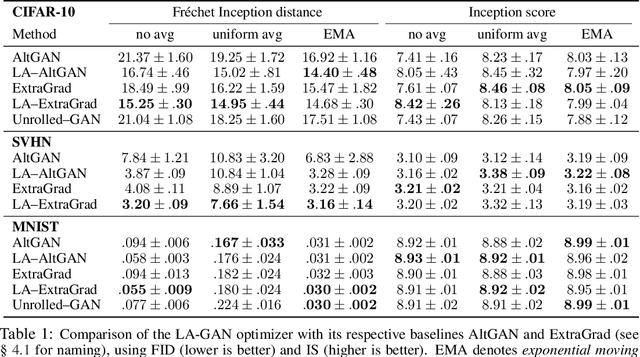


Generative Adversarial Networks are notoriously challenging to train. The underlying minimax optimization is highly susceptible to the variance of the stochastic gradient and the rotational component of the associated game vector field. We empirically demonstrate the effectiveness of the Lookahead meta-optimization method for optimizing games, originally proposed for standard minimization. The backtracking step of Lookahead naturally handles the rotational game dynamics, which in turn enables the gradient ascent descent method to converge on challenging toy games often analyzed in the literature. Moreover, it implicitly handles high variance without using large mini-batches, known to be essential for reaching state of the art performance. Experimental results on MNIST, SVHN, and CIFAR-10, demonstrate a clear advantage of combining Lookahead with Adam or extragradient, in terms of performance, memory footprint, and improved stability. Using 30-fold fewer parameters and 16-fold smaller minibatches we outperform the reported performance of the class-dependent BigGAN on CIFAR-10 by obtaining FID of $13.65$ \emph{without} using the class labels, bringing state-of-the-art GAN training within reach of common computational resources.