 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperMixer: An MLP-based Green AI Alternative to Transformers
Paper and Code
Mar 07, 2022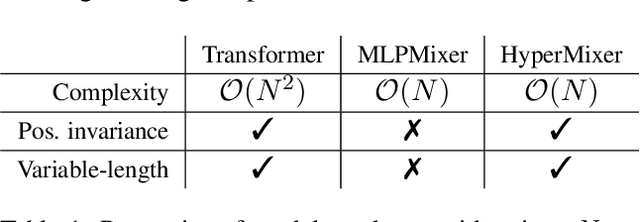
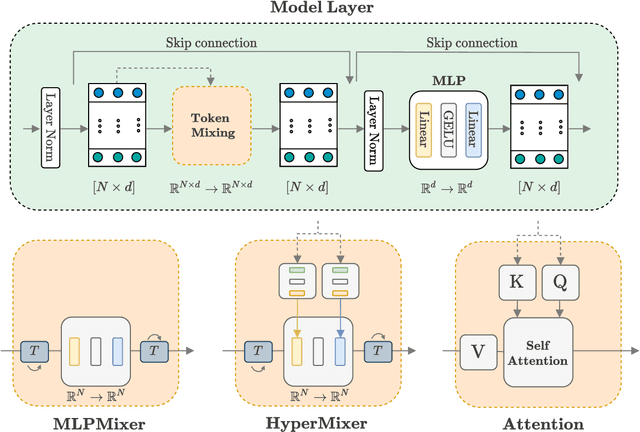
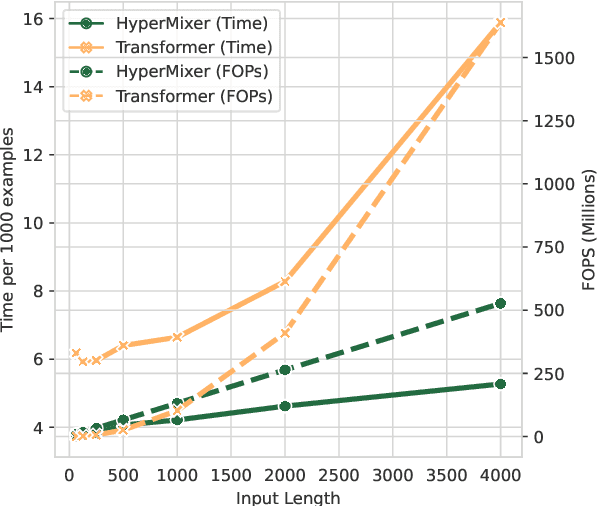
Transformer-based architectures are the model of choice for natural language understanding, but they come at a significant cost, as they have quadratic complexity in the input length and can be difficult to tune. In the pursuit of Green AI, we investigate simple MLP-based architectures. We find that existing architectures such as MLPMixer, which achieves token mixing through a static MLP applied to each feature independently, are too detached from the inductive biases required for natural language understanding. In this paper, we propose a simple variant, HyperMixer, which forms the token mixing MLP dynamically using hypernetworks. Empirically, we demonstrate that our model performs better than alternative MLP-based models, and on par with Transformers. In contrast to Transformers, HyperMixer achieves these results at substantially lower costs in terms of processing time, training data, and hyperparameter tuning.