 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRet: Improved Retriever for Code Editing
May 30, 2025



In this paper, we introduce CoRet, a dense retrieval model designed for code-editing tasks that integrates code semantics, repository structure, and call graph dependencies. The model focuses on retrieving relevant portions of a code repository based on natural language queries such as requests to implement new features or fix bugs. These retrieved code chunks can then be presented to a user or to a second code-editing model or agent. To train CoRet, we propose a loss function explicitly designed for repository-level retrieval. On SWE-bench and Long Code Arena's bug localisation datasets, we show that our model substantially improves retrieval recall by at least 15 percentage points over existing models, and ablate the design choices to show their importance in achieving these results.
Nonparametric Variational Regularisation of Pretrained Transformers
Dec 01, 2023



The current paradigm of large-scale pre-training and fine-tuning Transformer large language models has lead to significant improvements across the board in natural language processing. However, such large models are susceptible to overfitting to their training data, and as a result the models perform poorly when the domain changes. Also, due to the model's scale, the cost of fine-tuning the model to the new domain is large. Nonparametric Variational Information Bottleneck (NVIB) has been proposed as a regulariser for training cross-attention in Transformers, potentially addressing the overfitting problem. We extend the NVIB framework to replace all types of attention functions in Transformers, and show that existing pretrained Transformers can be reinterpreted as Nonparametric Variational (NV) models using a proposed identity initialisation. We then show that changing the initialisation introduces a novel, information-theoretic post-training regularisation in the attention mechanism, which improves out-of-domain generalisation without any training. This success supports the hypothesis that pretrained Transformers are implicitly NV Bayesian models.
Learning to Abstract with Nonparametric Variational Information Bottleneck
Oct 26, 2023



Learned representations at the level of characters, sub-words, words and sentences, have each contributed to advances in understanding different NLP tasks and linguistic phenomena. However, learning textual embeddings is costly as they are tokenization specific and require different models to be trained for each level of abstraction. We introduce a novel language representation model which can learn to compress to different levels of abstraction at different layers of the same model. We apply Nonparametric Variational Information Bottleneck (NVIB) to stacked Transformer self-attention layers in the encoder, which encourages an information-theoretic compression of the representations through the model. We find that the layers within the model correspond to increasing levels of abstraction and that their representations are more linguistically informed. Finally, we show that NVIB compression results in a model which is more robust to adversarial perturbations.
A Variational AutoEncoder for Transformers with Nonparametric Variational Information Bottleneck
Aug 12, 2022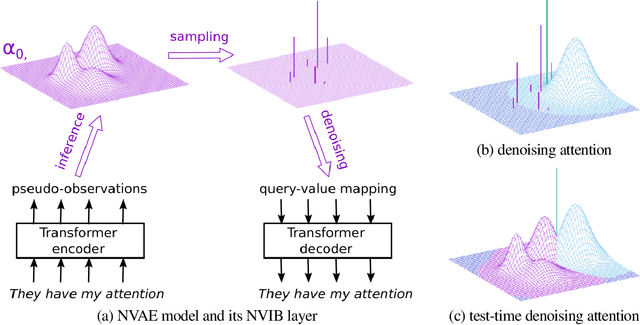
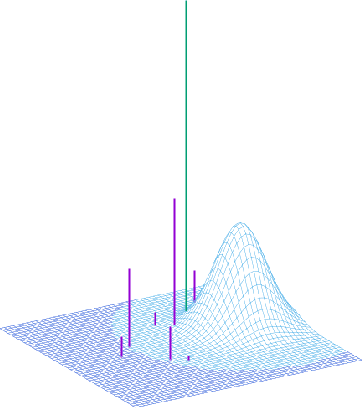

We propose a VAE for Transformers by developing a variational information bottleneck regulariser for Transformer embeddings. We formalise the embedding space of Transformer encoders as mixture probability distributions, and use Bayesian nonparametrics to derive a nonparametric variational information bottleneck (NVIB) for such attention-based embeddings. The variable number of mixture components supported by nonparametric methods captures the variable number of vectors supported by attention, and the exchangeability of our nonparametric distributions captures the permutation invariance of attention. This allows NVIB to regularise the number of vectors accessible with attention, as well as the amount of information in individual vectors. By regularising the cross-attention of a Transformer encoder-decoder with NVIB, we propose a nonparametric variational autoencoder (NVAE). Initial experiments on training a NVAE on natural language text show that the induced embedding space has the desired properties of a VAE for Transformers.
HyperMixer: An MLP-based Green AI Alternative to Transformers
Mar 07, 2022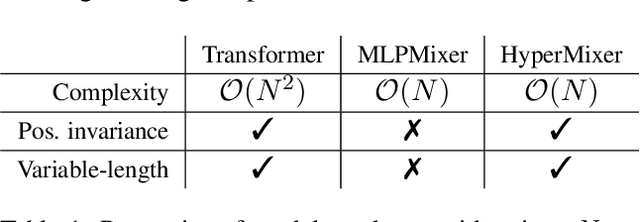
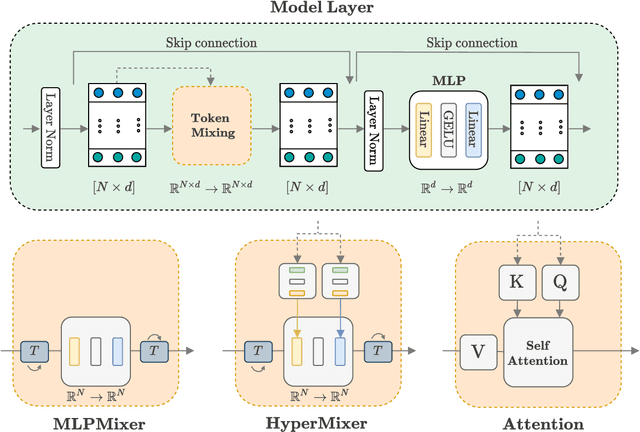
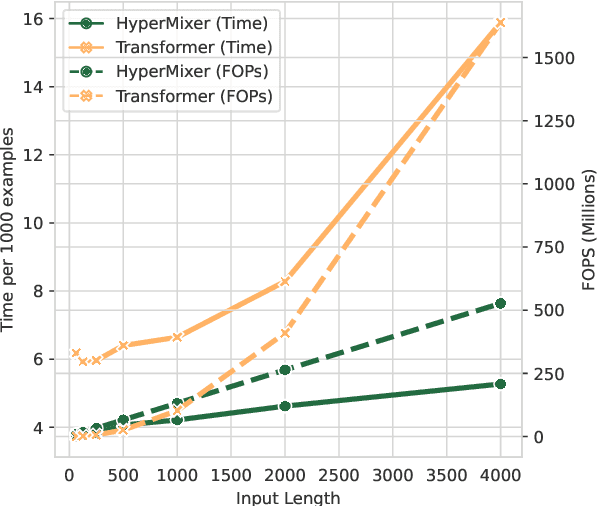
Transformer-based architectures are the model of choice for natural language understanding, but they come at a significant cost, as they have quadratic complexity in the input length and can be difficult to tune. In the pursuit of Green AI, we investigate simple MLP-based architectures. We find that existing architectures such as MLPMixer, which achieves token mixing through a static MLP applied to each feature independently, are too detached from the inductive biases required for natural language understanding. In this paper, we propose a simple variant, HyperMixer, which forms the token mixing MLP dynamically using hypernetworks. Empirically, we demonstrate that our model performs better than alternative MLP-based models, and on par with Transformers. In contrast to Transformers, HyperMixer achieves these results at substantially lower costs in terms of processing time, training data, and hyperparameter tuning.