 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRet: Improved Retriever for Code Editing
May 30, 2025



In this paper, we introduce CoRet, a dense retrieval model designed for code-editing tasks that integrates code semantics, repository structure, and call graph dependencies. The model focuses on retrieving relevant portions of a code repository based on natural language queries such as requests to implement new features or fix bugs. These retrieved code chunks can then be presented to a user or to a second code-editing model or agent. To train CoRet, we propose a loss function explicitly designed for repository-level retrieval. On SWE-bench and Long Code Arena's bug localisation datasets, we show that our model substantially improves retrieval recall by at least 15 percentage points over existing models, and ablate the design choices to show their importance in achieving these results.
Choice of PEFT Technique in Continual Learning: Prompt Tuning is Not All You Need
Jun 05, 2024



Recent Continual Learning (CL) methods have combined pretrained Transformers with prompt tuning, a parameter-efficient fine-tuning (PEFT) technique. We argue that the choice of prompt tuning in prior works was an undefended and unablated decision, which has been uncritically adopted by subsequent research, but warrants further research to understand its implications. In this paper, we conduct this research and find that the choice of prompt tuning as a PEFT method hurts the overall performance of the CL system. To illustrate this, we replace prompt tuning with LoRA in two state-of-the-art continual learning methods: Learning to Prompt and S-Prompts. These variants consistently achieve higher accuracy across a wide range of domain-incremental and class-incremental benchmarks, while being competitive in inference speed. Our work highlights a crucial argument: unexamined choices can hinder progress in the field, and rigorous ablations, such as the PEFT method, are required to drive meaningful adoption of CL techniques in real-world applications.
Continual Learning with Low Rank Adaptation
Nov 29, 2023



Recent work using pretrained transformers has shown impressive performance when fine-tuned with data from the downstream problem of interest. However, they struggle to retain that performance when the data characteristics changes. In this paper, we focus on continual learning, where a pre-trained transformer is updated to perform well on new data, while retaining its performance on data it was previously trained on. Earlier works have tackled this primarily through methods inspired from prompt tuning. We question this choice, and investigate the applicability of Low Rank Adaptation (LoRA) to continual learning. On a range of domain-incremental learning benchmarks, our LoRA-based solution, CoLoR, yields state-of-the-art performance, while still being as parameter efficient as the prompt tuning based methods.
PAUMER: Patch Pausing Transformer for Semantic Segmentation
Nov 01, 2023We study the problem of improving the efficiency of segmentation transformers by using disparate amounts of computation for different parts of the image. Our method, PAUMER, accomplishes this by pausing computation for patches that are deemed to not need any more computation before the final decoder. We use the entropy of predictions computed from intermediate activations as the pausing criterion, and find this aligns well with semantics of the image. Our method has a unique advantage that a single network trained with the proposed strategy can be effortlessly adapted at inference to various run-time requirements by modulating its pausing parameters. On two standard segmentation datasets, Cityscapes and ADE20K, we show that our method operates with about a $50\%$ higher throughput with an mIoU drop of about $0.65\%$ and $4.6\%$ respectively.
Test time Adaptation through Perturbation Robustness
Oct 19, 2021
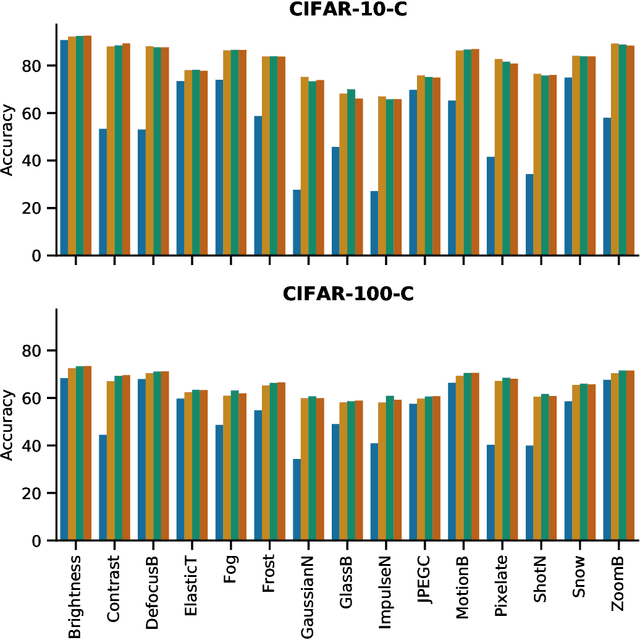

Data samples generated by several real world processes are dynamic in nature \textit{i.e.}, their characteristics vary with time. Thus it is not possible to train and tackle all possible distributional shifts between training and inference, using the host of transfer learning methods in literature. In this paper, we tackle this problem of adapting to domain shift at inference time \textit{i.e.}, we do not change the training process, but quickly adapt the model at test-time to handle any domain shift. For this, we propose to enforce consistency of predictions of data sampled in the vicinity of test sample on the image manifold. On a host of test scenarios like dealing with corruptions (CIFAR-10-C and CIFAR-100-C), and domain adaptation (VisDA-C), our method is at par or significantly outperforms previous methods.
On the Tunability of Optimizers in Deep Learning
Oct 25, 2019
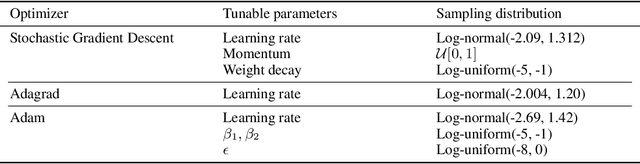
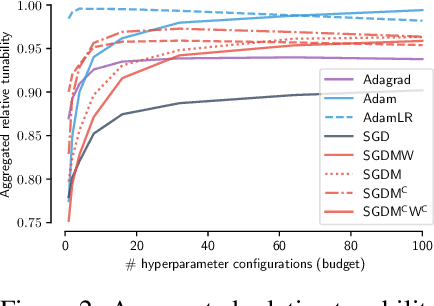
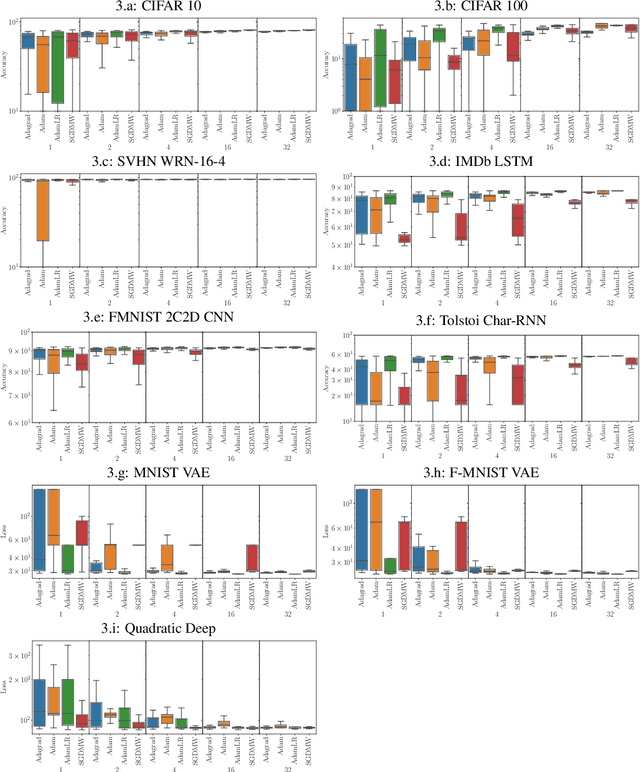
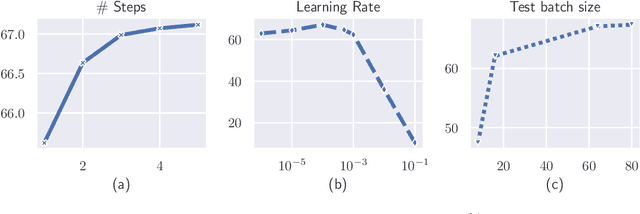
There is no consensus yet on the question whether adaptive gradient methods like Adam are easier to use than non-adaptive optimization methods like SGD. In this work, we fill in the important, yet ambiguous concept of `ease-of-use' by defining an optimizer's \emph{tunability}: How easy is it to find good hyperparameter configurations using automatic random hyperparameter search? We propose a practical and universal quantitative measure for optimizer tunability that can form the basis for a fair optimizer benchmark. Evaluating a variety of optimizers on an extensive set of standard datasets and architectures, we find that Adam is the most tunable for the majority of problems, especially with a low budget for hyperparameter tuning.