 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeσ-GPTs: A New Approach to Autoregressive Models
Apr 15, 2024Autoregressive models, such as the GPT family, use a fixed order, usually left-to-right, to generate sequences. However, this is not a necessity. In this paper, we challenge this assumption and show that by simply adding a positional encoding for the output, this order can be modulated on-the-fly per-sample which offers key advantageous properties. It allows for the sampling of and conditioning on arbitrary subsets of tokens, and it also allows sampling in one shot multiple tokens dynamically according to a rejection strategy, leading to a sub-linear number of model evaluations. We evaluate our method across various domains, including language modeling, path-solving, and aircraft vertical rate prediction, decreasing the number of steps required for generation by an order of magnitude.
PAUMER: Patch Pausing Transformer for Semantic Segmentation
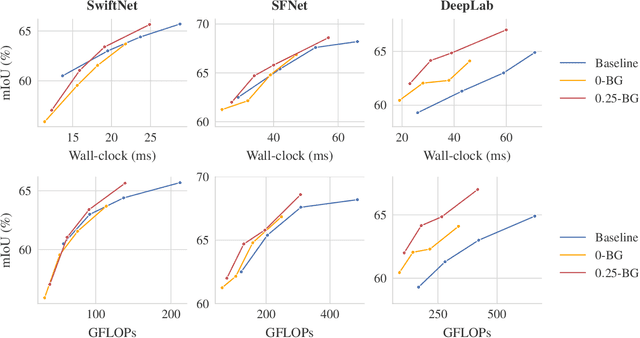
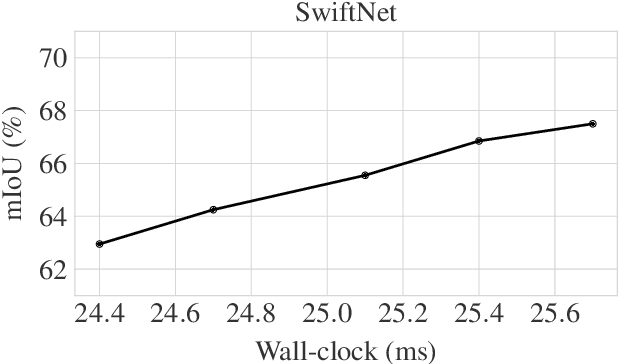
Nov 01, 2023We study the problem of improving the efficiency of segmentation transformers by using disparate amounts of computation for different parts of the image. Our method, PAUMER, accomplishes this by pausing computation for patches that are deemed to not need any more computation before the final decoder. We use the entropy of predictions computed from intermediate activations as the pausing criterion, and find this aligns well with semantics of the image. Our method has a unique advantage that a single network trained with the proposed strategy can be effortlessly adapted at inference to various run-time requirements by modulating its pausing parameters. On two standard segmentation datasets, Cityscapes and ADE20K, we show that our method operates with about a $50\%$ higher throughput with an mIoU drop of about $0.65\%$ and $4.6\%$ respectively.
Borrowing from yourself: Faster future video segmentation with partial channel update
Feb 11, 2022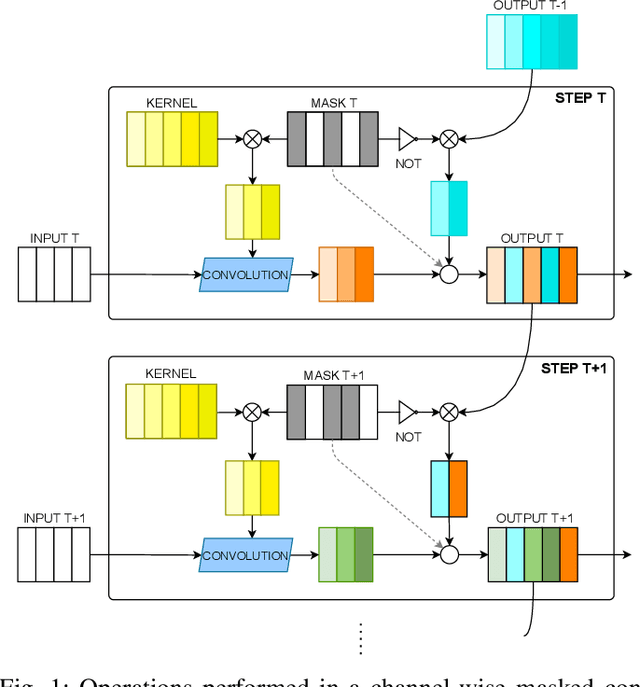
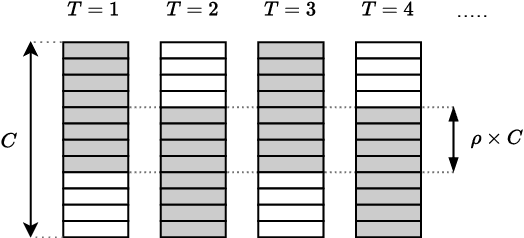
Semantic segmentation is a well-addressed topic in the computer vision literature, but the design of fast and accurate video processing networks remains challenging. In addition, to run on embedded hardware, computer vision models often have to make compromises on accuracy to run at the required speed, so that a latency/accuracy trade-off is usually at the heart of these real-time systems' design. For the specific case of videos, models have the additional possibility to make use of computations made for previous frames to mitigate the accuracy loss while being real-time. In this work, we propose to tackle the task of fast future video segmentation prediction through the use of convolutional layers with time-dependent channel masking. This technique only updates a chosen subset of the feature maps at each time-step, bringing simultaneously less computation and latency, and allowing the network to leverage previously computed features. We apply this technique to several fast architectures and experimentally confirm its benefits for the future prediction subtask.
Fair Latency-Aware Metric for real-time video segmentation networks
Apr 06, 2020
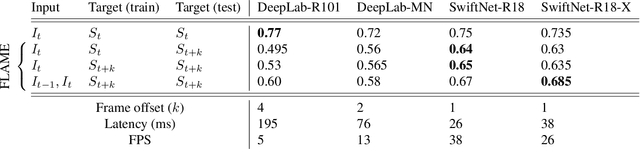
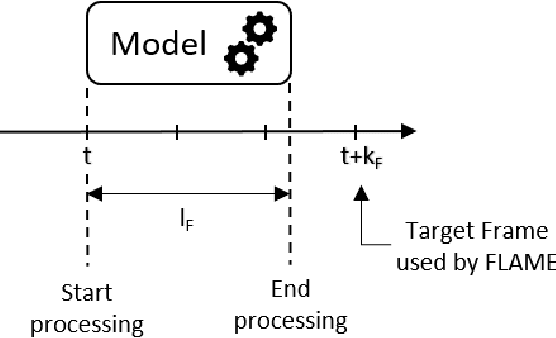

As supervised semantic segmentation is reaching satisfying results, many recent papers focused on making segmentation network architectures faster, smaller and more efficient. In particular, studies often aim to reach the stage to which they can claim to be "real-time". Achieving this goal is especially relevant in the context of real-time video operations for autonomous vehicles and robots, or medical imaging during surgery. The common metric used for assessing these methods is so far the same as the ones used for image segmentation without time constraint: mean Intersection over Union (mIoU). In this paper, we argue that this metric is not relevant enough for real-time video as it does not take into account the processing time (latency) of the network. We propose a similar but more relevant metric called FLAME for video-segmentation networks, that compares the output segmentation of the network with the ground truth segmentation of the current video frame at the time when the network finishes the processing. We perform experiments to compare a few networks using this metric and propose a simple addition to network training to enhance results according to that metric.