 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorrowing from yourself: Faster future video segmentation with partial channel update
Paper and Code
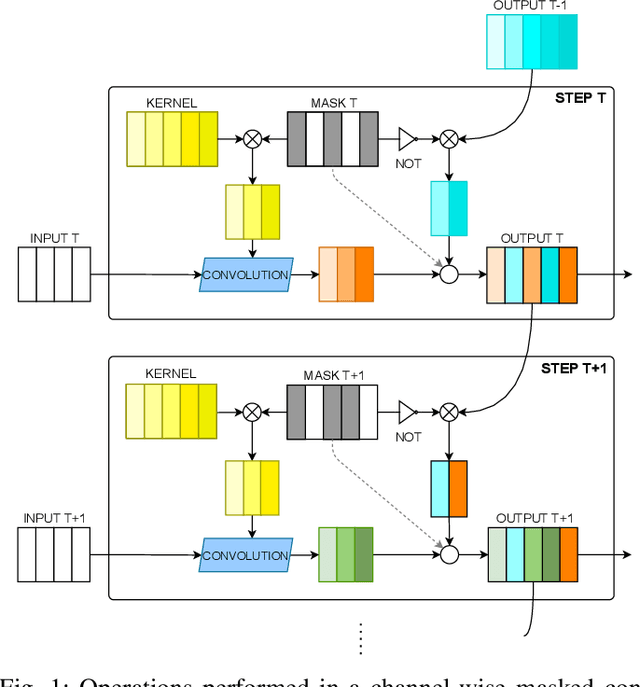
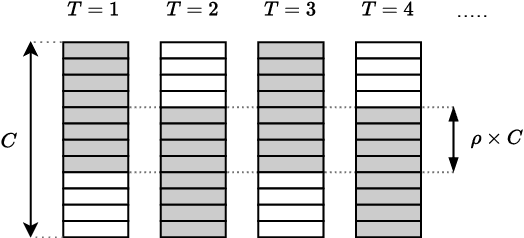
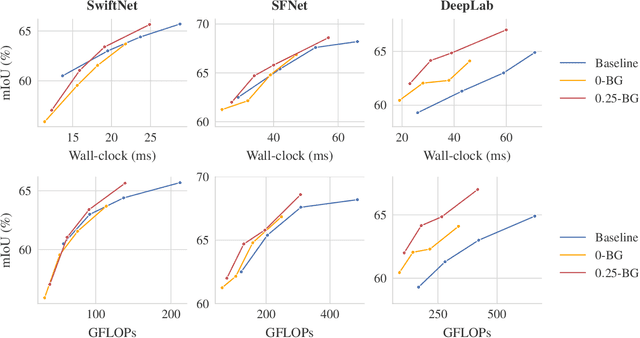
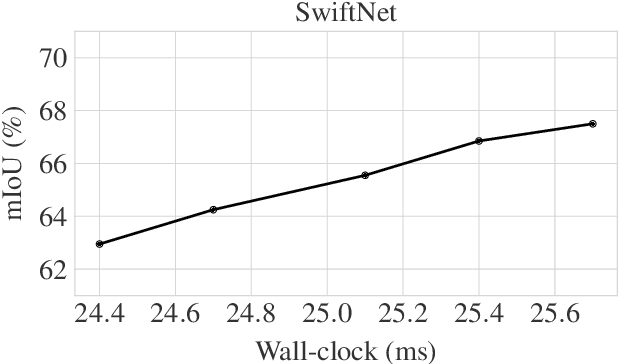
Semantic segmentation is a well-addressed topic in the computer vision literature, but the design of fast and accurate video processing networks remains challenging. In addition, to run on embedded hardware, computer vision models often have to make compromises on accuracy to run at the required speed, so that a latency/accuracy trade-off is usually at the heart of these real-time systems' design. For the specific case of videos, models have the additional possibility to make use of computations made for previous frames to mitigate the accuracy loss while being real-time. In this work, we propose to tackle the task of fast future video segmentation prediction through the use of convolutional layers with time-dependent channel masking. This technique only updates a chosen subset of the feature maps at each time-step, bringing simultaneously less computation and latency, and allowing the network to leverage previously computed features. We apply this technique to several fast architectures and experimentally confirm its benefits for the future prediction subtask.