 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeσ-GPTs: A New Approach to Autoregressive Models
Apr 15, 2024Autoregressive models, such as the GPT family, use a fixed order, usually left-to-right, to generate sequences. However, this is not a necessity. In this paper, we challenge this assumption and show that by simply adding a positional encoding for the output, this order can be modulated on-the-fly per-sample which offers key advantageous properties. It allows for the sampling of and conditioning on arbitrary subsets of tokens, and it also allows sampling in one shot multiple tokens dynamically according to a rejection strategy, leading to a sub-linear number of model evaluations. We evaluate our method across various domains, including language modeling, path-solving, and aircraft vertical rate prediction, decreasing the number of steps required for generation by an order of magnitude.
Accurate Extrinsic Prediction of Physical Systems Using Transformers
Oct 20, 2022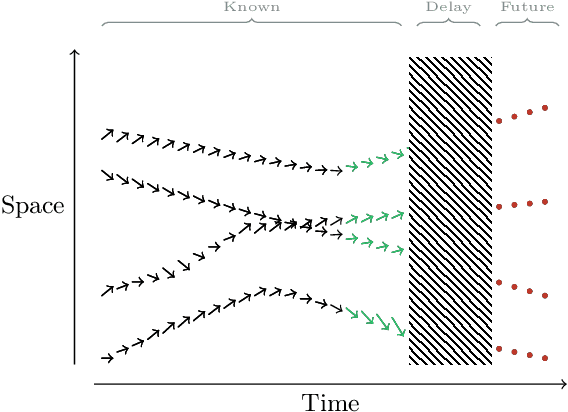
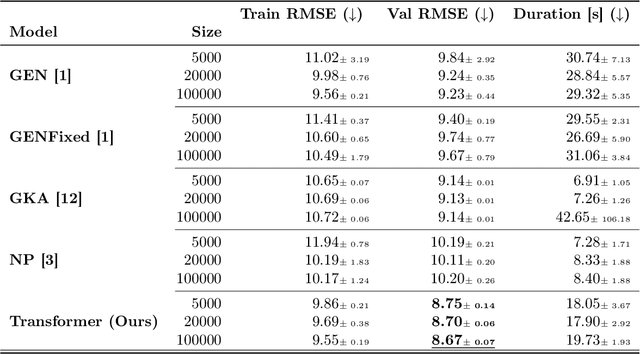
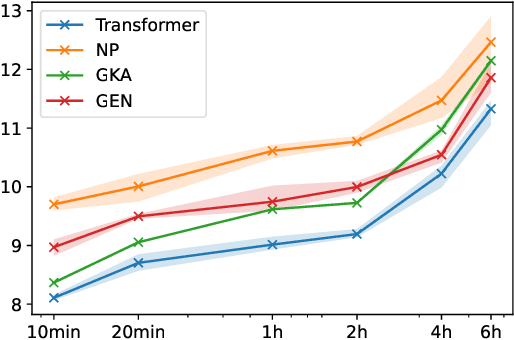
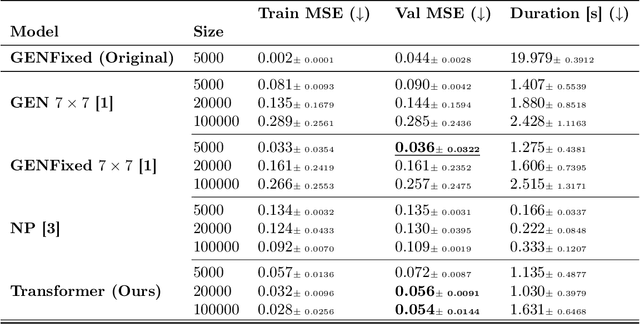
Accurate high-altitude wind forecasting is important for air traffic control. And the large volume of data available for this task makes deep neural network-based models a possibility. However, special methods are required because the data is measured only sparsely: along the main aircraft trajectories and arranged sparsely in space, namely along the main air corridors. Several deep learning approaches have been proposed, and in this work, we show that Transformers can fit this data efficiently and are able to extrapolate coherently from a context set. We show this by an extensive comparison of Transformers to numerous existing deep learning-based baselines in the literature. Besides high-altitude wind forecasting, we compare competing models on other dynamical physical systems, namely those modelled by partial differential equations, in particular the Poisson equation and Darcy Flow equation. For these experiments, in the case where the data is arranged non-regularly in space, Transformers outperform all the other evaluated methods. We also compared them in a more standard setup where the data is arranged on a grid and show that the Transformers are competitive with state-of-the-art methods, even though it does not require regular spacing. The code and datasets of the different experiments will be made publicly available at publication time.
HyperMixer: An MLP-based Green AI Alternative to Transformers
Mar 07, 2022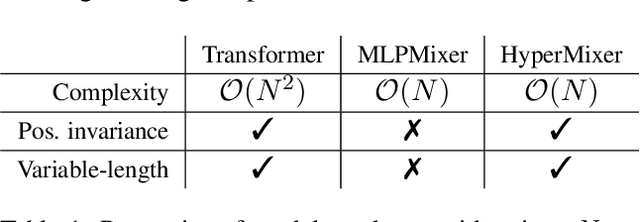
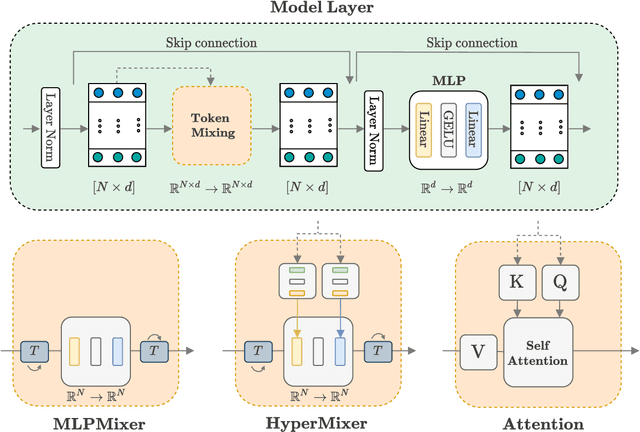
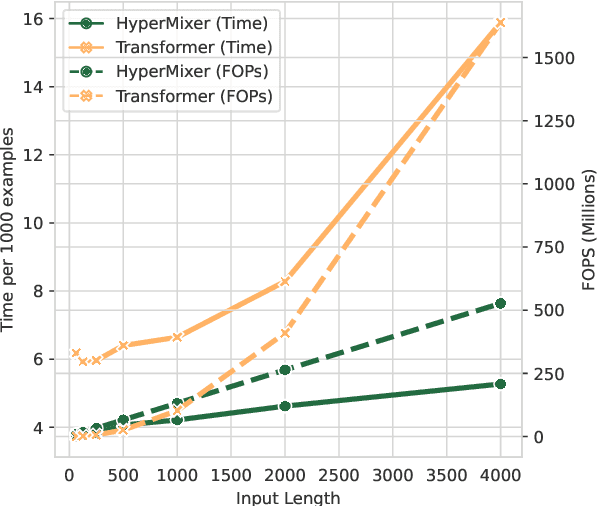
Transformer-based architectures are the model of choice for natural language understanding, but they come at a significant cost, as they have quadratic complexity in the input length and can be difficult to tune. In the pursuit of Green AI, we investigate simple MLP-based architectures. We find that existing architectures such as MLPMixer, which achieves token mixing through a static MLP applied to each feature independently, are too detached from the inductive biases required for natural language understanding. In this paper, we propose a simple variant, HyperMixer, which forms the token mixing MLP dynamically using hypernetworks. Empirically, we demonstrate that our model performs better than alternative MLP-based models, and on par with Transformers. In contrast to Transformers, HyperMixer achieves these results at substantially lower costs in terms of processing time, training data, and hyperparameter tuning.
Efficient Wind Speed Nowcasting with GPU-Accelerated Nearest Neighbors Algorithm
Dec 20, 2021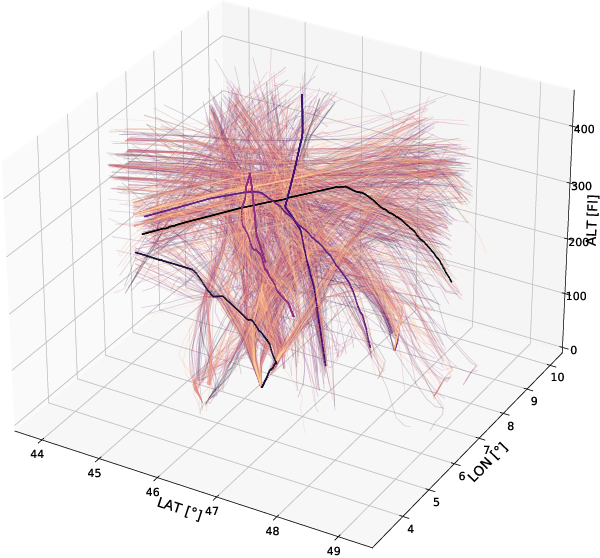

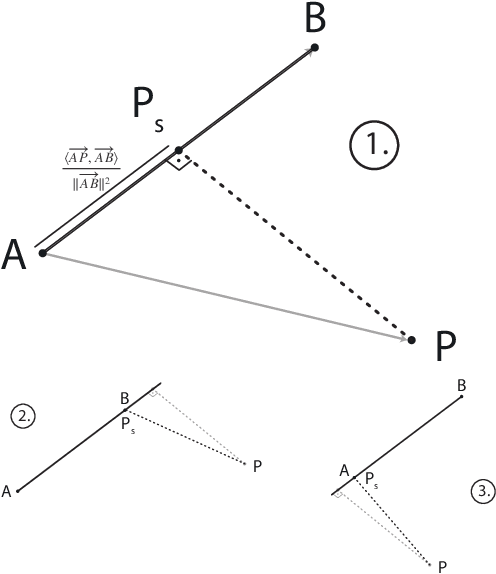
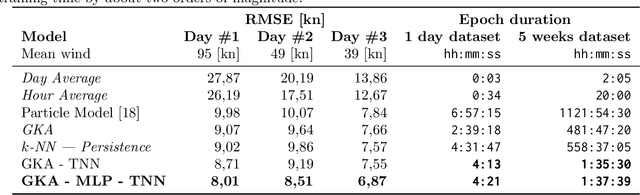
This paper proposes a simple yet efficient high-altitude wind nowcasting pipeline. It processes efficiently a vast amount of live data recorded by airplanes over the whole airspace and reconstructs the wind field with good accuracy. It creates a unique context for each point in the dataset and then extrapolates from it. As creating such context is computationally intensive, this paper proposes a novel algorithm that reduces the time and memory cost by efficiently fetching nearest neighbors in a data set whose elements are organized along smooth trajectories that can be approximated with piece-wise linear structures. We introduce an efficient and exact strategy implemented through algebraic tensorial operations, which is well-suited to modern GPU-based computing infrastructure. This method employs a scalable Euclidean metric and allows masking data points along one dimension. When applied, this method is more efficient than plain Euclidean k-NN and other well-known data selection methods such as KDTrees and provides a several-fold speedup. We provide an implementation in PyTorch and a novel data set to allow the replication of empirical results.