 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Single-Image Intrinsic Decomposition using Illumination-Varying Image Sequences
Sep 03, 2018



Machine learning based Single Image Intrinsic Decomposition (SIID) methods decompose a captured scene into its albedo and shading images by using the knowledge of a large set of known and realistic ground truth decompositions. Collecting and annotating such a dataset is an approach that cannot scale to sufficient variety and realism. We free ourselves from this limitation by training on unannotated images. Our method leverages the observation that two images of the same scene but with different lighting provide useful information on their intrinsic properties: by definition, albedo is invariant to lighting conditions, and cross-combining the estimated albedo of a first image with the estimated shading of a second one should lead back to the second one's input image. We transcribe this relationship into a siamese training scheme for a deep convolutional neural network that decomposes a single image into albedo and shading. The siamese setting allows us to introduce a new loss function including such cross-combinations, and to train solely on (time-lapse) images, discarding the need for any ground truth annotations. As a result, our method has the good properties of i) taking advantage of the time-varying information of image sequences in the (pre-computed) training step, ii) not requiring ground truth data to train on, and iii) being able to decompose single images of unseen scenes at runtime. To demonstrate and evaluate our work, we additionally propose a new rendered dataset containing illumination-varying scenes and a set of quantitative metrics to evaluate SIID algorithms. Despite its unsupervised nature, our results compete with state of the art methods, including supervised and non data-driven methods.
DARN: a Deep Adversial Residual Network for Intrinsic Image Decomposition
Mar 20, 2018
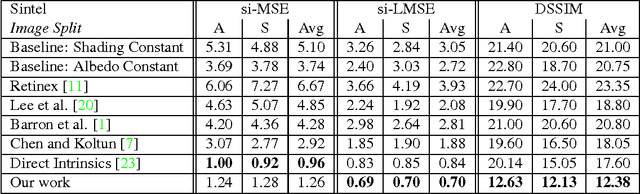
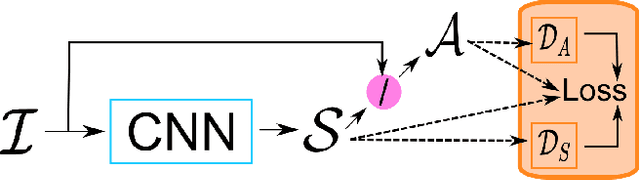

We present a new deep supervised learning method for intrinsic decomposition of a single image into its albedo and shading components. Our contributions are based on a new fully convolutional neural network that estimates absolute albedo and shading jointly. Our solution relies on a single end-to-end deep sequence of residual blocks and a perceptually-motivated metric formed by two adversarially trained discriminators. As opposed to classical intrinsic image decomposition work, it is fully data-driven, hence does not require any physical priors like shading smoothness or albedo sparsity, nor does it rely on geometric information such as depth. Compared to recent deep learning techniques, we simplify the architecture, making it easier to build and train, and constrain it to generate a valid and reversible decomposition. We rediscuss and augment the set of quantitative metrics so as to account for the more challenging recovery of non scale-invariant quantities. We train and demonstrate our architecture on the publicly available MPI Sintel dataset and its intrinsic image decomposition, show attenuated overfitting issues and discuss generalizability to other data. Results show that our work outperforms the state of the art deep algorithms both on the qualitative and quantitative aspect.
The WILDTRACK Multi-Camera Person Dataset
Jul 28, 2017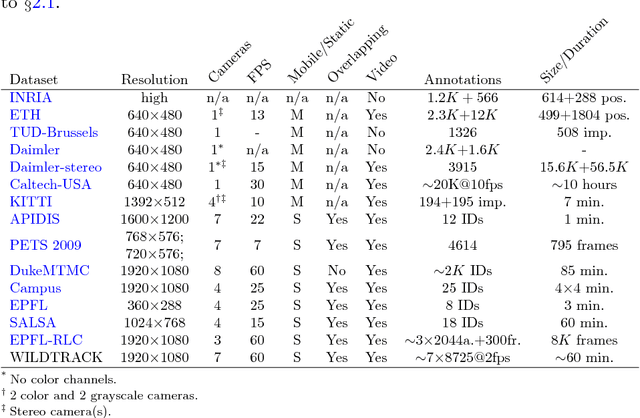


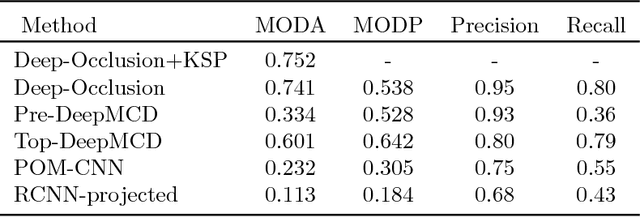
People detection methods are highly sensitive to the perpetual occlusions among the targets. As multi-camera set-ups become more frequently encountered, joint exploitation of the across views information would allow for improved detection performances. We provide a large-scale HD dataset named WILDTRACK which finally makes advanced deep learning methods applicable to this problem. The seven-static-camera set-up captures realistic and challenging scenarios of walking people. Notably, its camera calibration with jointly high-precision projection widens the range of algorithms which may make use of this dataset. In aim to help accelerate the research on automatic camera calibration, such annotations also accompany this dataset. Furthermore, the rich-in-appearance visual context of the pedestrian class makes this dataset attractive for monocular pedestrian detection as well, since: the HD cameras are placed relatively close to the people, and the size of the dataset further increases seven-fold. In summary, we overview existing multi-camera datasets and detection methods, enumerate details of our dataset, and we benchmark multi-camera state of the art detectors on this new dataset.