 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePitfalls of the Gram Loss for Neural Texture Synthesis in Light of Deep Feature Histograms
Jun 16, 2020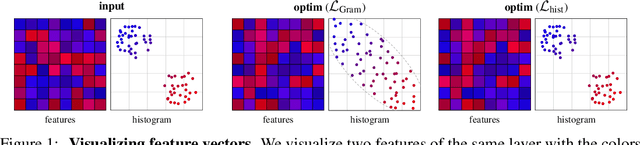
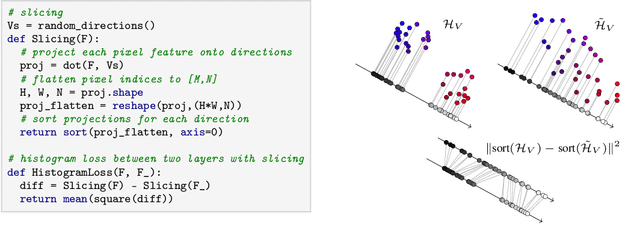
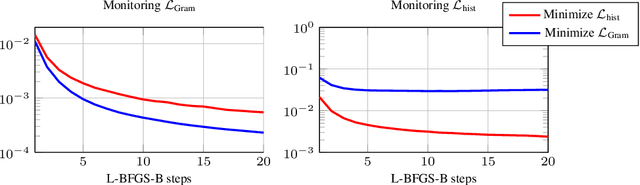

Neural texture synthesis and style transfer are both powered by the Gram matrix as a means to measure deep feature statistics. Despite its ubiquity, this second-order feature descriptor has several shortcomings resulting in visual artifacts, ill-defined interpolation, or inability to capture spatial constraints. Many previous works acknowledge these shortcomings but do not really explain why they occur. Fixing them is thus usually approached by adding new losses, which require parameter tuning and make the problem even more ill-defined, or architecturing complex and/or adversarial networks. In this paper, we propose a comprehensive study of these problems in the light of the multi-dimensional histograms of deep features. With the insights gained from our analysis, we show how to compute a well-defined and efficient textural loss based on histogram transformations. Our textural loss outperforms the Gram matrix in terms of quality, robustness, spatial control, and interpolation. It does not require additional learning or parameter tuning, and can be implemented in a few lines of code.
Unsupervised Deep Single-Image Intrinsic Decomposition using Illumination-Varying Image Sequences
Sep 03, 2018



Machine learning based Single Image Intrinsic Decomposition (SIID) methods decompose a captured scene into its albedo and shading images by using the knowledge of a large set of known and realistic ground truth decompositions. Collecting and annotating such a dataset is an approach that cannot scale to sufficient variety and realism. We free ourselves from this limitation by training on unannotated images. Our method leverages the observation that two images of the same scene but with different lighting provide useful information on their intrinsic properties: by definition, albedo is invariant to lighting conditions, and cross-combining the estimated albedo of a first image with the estimated shading of a second one should lead back to the second one's input image. We transcribe this relationship into a siamese training scheme for a deep convolutional neural network that decomposes a single image into albedo and shading. The siamese setting allows us to introduce a new loss function including such cross-combinations, and to train solely on (time-lapse) images, discarding the need for any ground truth annotations. As a result, our method has the good properties of i) taking advantage of the time-varying information of image sequences in the (pre-computed) training step, ii) not requiring ground truth data to train on, and iii) being able to decompose single images of unseen scenes at runtime. To demonstrate and evaluate our work, we additionally propose a new rendered dataset containing illumination-varying scenes and a set of quantitative metrics to evaluate SIID algorithms. Despite its unsupervised nature, our results compete with state of the art methods, including supervised and non data-driven methods.
DARN: a Deep Adversial Residual Network for Intrinsic Image Decomposition
Mar 20, 2018
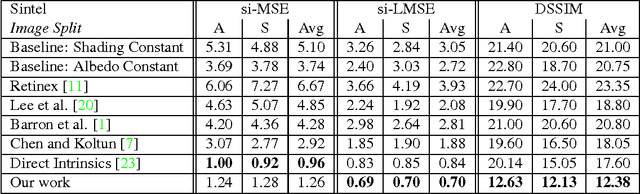
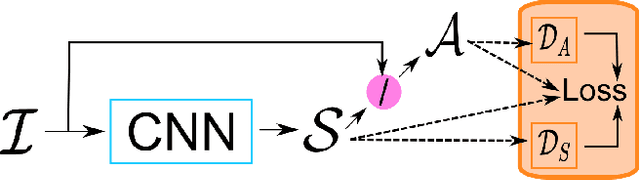

We present a new deep supervised learning method for intrinsic decomposition of a single image into its albedo and shading components. Our contributions are based on a new fully convolutional neural network that estimates absolute albedo and shading jointly. Our solution relies on a single end-to-end deep sequence of residual blocks and a perceptually-motivated metric formed by two adversarially trained discriminators. As opposed to classical intrinsic image decomposition work, it is fully data-driven, hence does not require any physical priors like shading smoothness or albedo sparsity, nor does it rely on geometric information such as depth. Compared to recent deep learning techniques, we simplify the architecture, making it easier to build and train, and constrain it to generate a valid and reversible decomposition. We rediscuss and augment the set of quantitative metrics so as to account for the more challenging recovery of non scale-invariant quantities. We train and demonstrate our architecture on the publicly available MPI Sintel dataset and its intrinsic image decomposition, show attenuated overfitting issues and discuss generalizability to other data. Results show that our work outperforms the state of the art deep algorithms both on the qualitative and quantitative aspect.
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
Mar 03, 2018



Low-end and compact mobile cameras demonstrate limited photo quality mainly due to space, hardware and budget constraints. In this work, we propose a deep learning solution that translates photos taken by cameras with limited capabilities into DSLR-quality photos automatically. We tackle this problem by introducing a weakly supervised photo enhancer (WESPE) - a novel image-to-image Generative Adversarial Network-based architecture. The proposed model is trained by under weak supervision: unlike previous works, there is no need for strong supervision in the form of a large annotated dataset of aligned original/enhanced photo pairs. The sole requirement is two distinct datasets: one from the source camera, and one composed of arbitrary high-quality images that can be generally crawled from the Internet - the visual content they exhibit may be unrelated. Hence, our solution is repeatable for any camera: collecting the data and training can be achieved in a couple of hours. In this work, we emphasize on extensive evaluation of obtained results. Besides standard objective metrics and subjective user study, we train a virtual rater in the form of a separate CNN that mimics human raters on Flickr data and use this network to get reference scores for both original and enhanced photos. Our experiments on the DPED, KITTI and Cityscapes datasets as well as pictures from several generations of smartphones demonstrate that WESPE produces comparable or improved qualitative results with state-of-the-art strongly supervised methods.
DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks
Sep 05, 2017

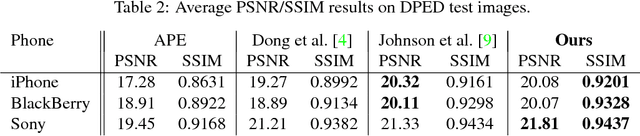

Despite a rapid rise in the quality of built-in smartphone cameras, their physical limitations - small sensor size, compact lenses and the lack of specific hardware, - impede them to achieve the quality results of DSLR cameras. In this work we present an end-to-end deep learning approach that bridges this gap by translating ordinary photos into DSLR-quality images. We propose learning the translation function using a residual convolutional neural network that improves both color rendition and image sharpness. Since the standard mean squared loss is not well suited for measuring perceptual image quality, we introduce a composite perceptual error function that combines content, color and texture losses. The first two losses are defined analytically, while the texture loss is learned in an adversarial fashion. We also present DPED, a large-scale dataset that consists of real photos captured from three different phones and one high-end reflex camera. Our quantitative and qualitative assessments reveal that the enhanced image quality is comparable to that of DSLR-taken photos, while the methodology is generalized to any type of digital camera.