 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Perceptual Image Enhancement
Dec 31, 2018



The vast majority of photos taken today are by mobile phones. While their quality is rapidly growing, due to physical limitations and cost constraints, mobile phone cameras struggle to compare in quality with DSLR cameras. This motivates us to computationally enhance these images. We extend upon the results of Ignatov et al., where they are able to translate images from compact mobile cameras into images with comparable quality to high-resolution photos taken by DSLR cameras. However, the neural models employed require large amounts of computational resources and are not lightweight enough to run on mobile devices. We build upon the prior work and explore different network architectures targeting an increase in image quality and speed. With an efficient network architecture which does most of its processing in a lower spatial resolution, we achieve a significantly higher mean opinion score (MOS) than the baseline while speeding up the computation by 6.3 times on a consumer-grade CPU. This suggests a promising direction for neural-network-based photo enhancement using the phone hardware of the future.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
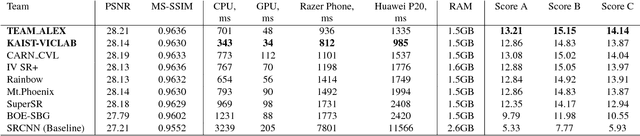

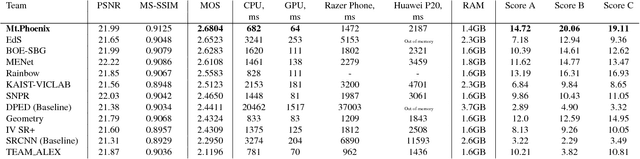
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.
WESPE: Weakly Supervised Photo Enhancer for Digital Cameras
Mar 03, 2018



Low-end and compact mobile cameras demonstrate limited photo quality mainly due to space, hardware and budget constraints. In this work, we propose a deep learning solution that translates photos taken by cameras with limited capabilities into DSLR-quality photos automatically. We tackle this problem by introducing a weakly supervised photo enhancer (WESPE) - a novel image-to-image Generative Adversarial Network-based architecture. The proposed model is trained by under weak supervision: unlike previous works, there is no need for strong supervision in the form of a large annotated dataset of aligned original/enhanced photo pairs. The sole requirement is two distinct datasets: one from the source camera, and one composed of arbitrary high-quality images that can be generally crawled from the Internet - the visual content they exhibit may be unrelated. Hence, our solution is repeatable for any camera: collecting the data and training can be achieved in a couple of hours. In this work, we emphasize on extensive evaluation of obtained results. Besides standard objective metrics and subjective user study, we train a virtual rater in the form of a separate CNN that mimics human raters on Flickr data and use this network to get reference scores for both original and enhanced photos. Our experiments on the DPED, KITTI and Cityscapes datasets as well as pictures from several generations of smartphones demonstrate that WESPE produces comparable or improved qualitative results with state-of-the-art strongly supervised methods.
DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks
Sep 05, 2017

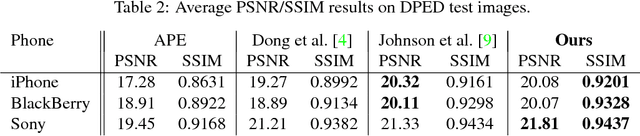

Despite a rapid rise in the quality of built-in smartphone cameras, their physical limitations - small sensor size, compact lenses and the lack of specific hardware, - impede them to achieve the quality results of DSLR cameras. In this work we present an end-to-end deep learning approach that bridges this gap by translating ordinary photos into DSLR-quality images. We propose learning the translation function using a residual convolutional neural network that improves both color rendition and image sharpness. Since the standard mean squared loss is not well suited for measuring perceptual image quality, we introduce a composite perceptual error function that combines content, color and texture losses. The first two losses are defined analytically, while the texture loss is learned in an adversarial fashion. We also present DPED, a large-scale dataset that consists of real photos captured from three different phones and one high-end reflex camera. Our quantitative and qualitative assessments reveal that the enhanced image quality is comparable to that of DSLR-taken photos, while the methodology is generalized to any type of digital camera.