 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisalignment Between Backpropagation and the Hierarchy of Brain Responses to Images
May 27, 2026Backpropagation is the core learning mechanism underlying deep learning. However, whether and how this algorithm is implemented in the brain remains highly debated. In particular, while forward activations of pretrained models reliably map onto the cortical hierarchy of visual processing, it is unknown whether backpropagated gradients exhibit a similar correspondence. Here, we address this question using functional magnetic resonance imaging (fMRI) and magnetoencephalography (MEG) recordings of human brain responses to natural images. For this, we extend standard encoding analyses of forward activations to map backpropagated gradients onto neural data. Focusing on a recent self-supervised vision model (DINOv3) and reproducing results on eight vision models, we find that backpropagated gradients can reliably predict both fMRI and MEG signals, specifically in higher-level visual cortex and for later latencies. However, the spatial and temporal organization of these backpropagated gradients in the brain diverges from the patterns expected under a biologically plausible backpropagation mechanism: specifically, both the order in which gradients are computed and their spatial organization diverge from the temporal and spatial hierarchies of the human brain. Together, these results suggest that, although deep networks and the brain may share similar representational content, they likely rely on fundamentally different mechanisms to learn those representations.
Efficient Universal Perception Encoder
Mar 23, 2026Running AI models on smart edge devices can unlock versatile user experiences, but presents challenges due to limited compute and the need to handle multiple tasks simultaneously. This requires a vision encoder with small size but powerful and versatile representations. We present our method, Efficient Universal Perception Encoder (EUPE), which offers both inference efficiency and universally good representations for diverse downstream tasks. We achieve this by distilling from multiple domain-expert foundation vision encoders. Unlike previous agglomerative methods that directly scale down from multiple teachers to an efficient encoder, we demonstrate the importance of first scaling up to a large proxy teacher and then scaling down from this single teacher. Experiments show that EUPE achieves on-par or better performance than individual domain experts of the same size on diverse task domains and also outperforms previous agglomerative encoders. We will release the full family of EUPE models and the code to foster future research.
Disentangling the Factors of Convergence between Brains and Computer Vision Models
Aug 25, 2025Many AI models trained on natural images develop representations that resemble those of the human brain. However, the factors that drive this brain-model similarity remain poorly understood. To disentangle how the model, training and data independently lead a neural network to develop brain-like representations, we trained a family of self-supervised vision transformers (DINOv3) that systematically varied these different factors. We compare their representations of images to those of the human brain recorded with both fMRI and MEG, providing high resolution in spatial and temporal analyses. We assess the brain-model similarity with three complementary metrics focusing on overall representational similarity, topographical organization, and temporal dynamics. We show that all three factors - model size, training amount, and image type - independently and interactively impact each of these brain similarity metrics. In particular, the largest DINOv3 models trained with the most human-centric images reach the highest brain-similarity. This emergence of brain-like representations in AI models follows a specific chronology during training: models first align with the early representations of the sensory cortices, and only align with the late and prefrontal representations of the brain with considerably more training. Finally, this developmental trajectory is indexed by both structural and functional properties of the human cortex: the representations that are acquired last by the models specifically align with the cortical areas with the largest developmental expansion, thickness, least myelination, and slowest timescales. Overall, these findings disentangle the interplay between architecture and experience in shaping how artificial neural networks come to see the world as humans do, thus offering a promising framework to understand how the human brain comes to represent its visual world.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
You Don't Need Data-Augmentation in Self-Supervised Learning
Jun 13, 2024



Self-Supervised learning (SSL) with Joint-Embedding Architectures (JEA) has led to outstanding performances. All instantiations of this paradigm were trained using strong and well-established hand-crafted data augmentations, leading to the general belief that they are required for the proper training and performance of such models. On the other hand, generative reconstruction-based models such as BEIT and MAE or Joint-Embedding Predictive Architectures such as I-JEPA have shown strong performance without using data augmentations except masking. In this work, we challenge the importance of invariance and data-augmentation in JEAs at scale. By running a case-study on a recent SSL foundation model - DINOv2 - we show that strong image representations can be obtained with JEAs and only cropping without resizing provided the training data is large enough, reaching state-of-the-art results and using the least amount of augmentation in the literature. Through this study, we also discuss the impact of compute constraints on the outcomes of experimental deep learning research, showing that they can lead to very different conclusions.
Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach
May 24, 2024Self-supervised features are the cornerstone of modern machine learning systems. They are typically pre-trained on data collections whose construction and curation typically require extensive human effort. This manual process has some limitations similar to those encountered in supervised learning, e.g., the crowd-sourced selection of data is costly and time-consuming, preventing scaling the dataset size. In this work, we consider the problem of automatic curation of high-quality datasets for self-supervised pre-training. We posit that such datasets should be large, diverse and balanced, and propose a clustering-based approach for building ones satisfying all these criteria. Our method involves successive and hierarchical applications of $k$-means on a large and diverse data repository to obtain clusters that distribute uniformly among data concepts, followed by a hierarchical, balanced sampling step from these clusters. Extensive experiments on three different data domains including web-based images, satellite images and text show that features trained on our automatically curated datasets outperform those trained on uncurated data while being on par or better than ones trained on manually curated data.
Better (pseudo-)labels for semi-supervised instance segmentation
Mar 18, 2024



Despite the availability of large datasets for tasks like image classification and image-text alignment, labeled data for more complex recognition tasks, such as detection and segmentation, is less abundant. In particular, for instance segmentation annotations are time-consuming to produce, and the distribution of instances is often highly skewed across classes. While semi-supervised teacher-student distillation methods show promise in leveraging vast amounts of unlabeled data, they suffer from miscalibration, resulting in overconfidence in frequently represented classes and underconfidence in rarer ones. Additionally, these methods encounter difficulties in efficiently learning from a limited set of examples. We introduce a dual-strategy to enhance the teacher model's training process, substantially improving the performance on few-shot learning. Secondly, we propose a calibration correction mechanism that that enables the student model to correct the teacher's calibration errors. Using our approach, we observed marked improvements over a state-of-the-art supervised baseline performance on the LVIS dataset, with an increase of 2.8% in average precision (AP) and 10.3% gain in AP for rare classes.
DINOv2: Learning Robust Visual Features without Supervision
Apr 14, 2023
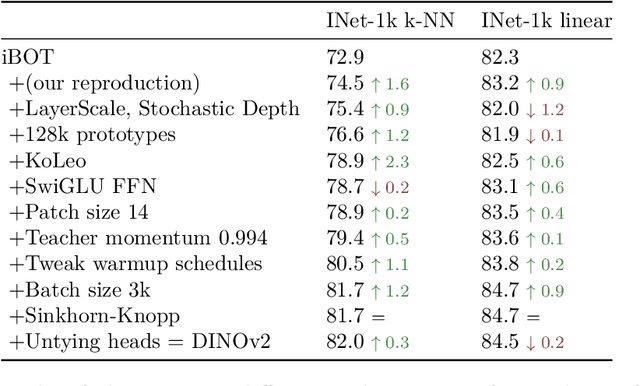
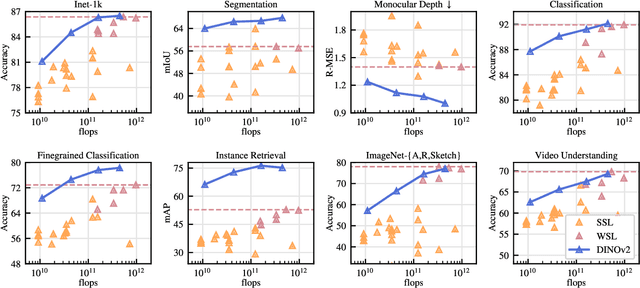
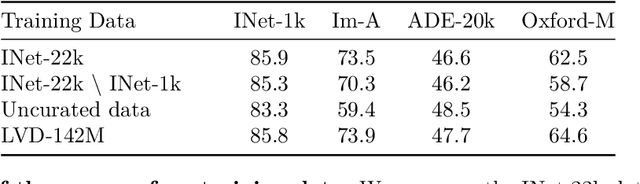
The recent breakthroughs in natural language processing for model pretraining on large quantities of data have opened the way for similar foundation models in computer vision. These models could greatly simplify the use of images in any system by producing all-purpose visual features, i.e., features that work across image distributions and tasks without finetuning. This work shows that existing pretraining methods, especially self-supervised methods, can produce such features if trained on enough curated data from diverse sources. We revisit existing approaches and combine different techniques to scale our pretraining in terms of data and model size. Most of the technical contributions aim at accelerating and stabilizing the training at scale. In terms of data, we propose an automatic pipeline to build a dedicated, diverse, and curated image dataset instead of uncurated data, as typically done in the self-supervised literature. In terms of models, we train a ViT model (Dosovitskiy et al., 2020) with 1B parameters and distill it into a series of smaller models that surpass the best available all-purpose features, OpenCLIP (Ilharco et al., 2021) on most of the benchmarks at image and pixel levels.