 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting Self-Supervised Token Embedding on the Tables
Paper and Code
Oct 25, 2017

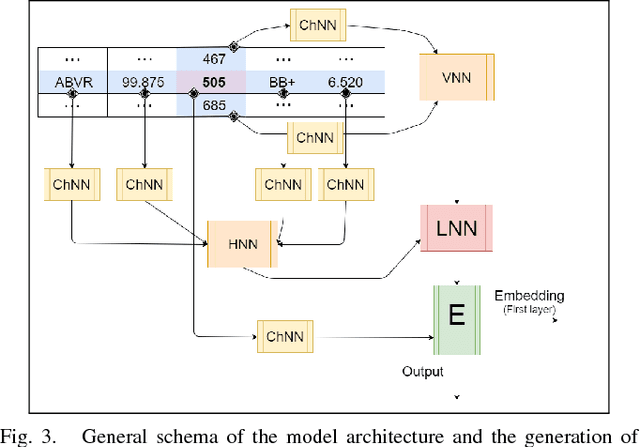
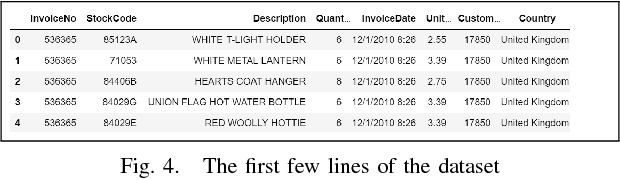
Information distribution by electronic messages is a privileged means of transmission for many businesses and individuals, often under the form of plain-text tables. As their number grows, it becomes necessary to use an algorithm to extract text and numbers instead of a human. Usual methods are focused on regular expressions or on a strict structure in the data, but are not efficient when we have many variations, fuzzy structure or implicit labels. In this paper we introduce SC2T, a totally self-supervised model for constructing vector representations of tokens in semi-structured messages by using characters and context levels that address these issues. It can then be used for an unsupervised labeling of tokens, or be the basis for a semi-supervised information extraction system.