 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOBF: A Deobfuscation Pre-Training Objective for Programming Languages
Paper and Code
Feb 16, 2021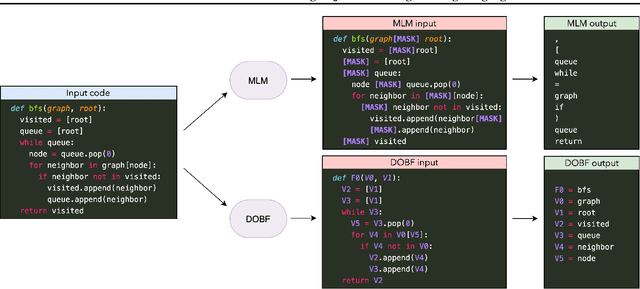


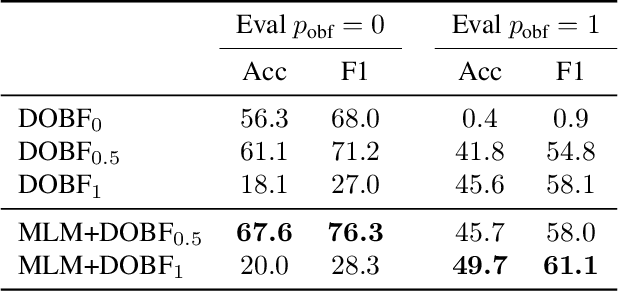
Recent advances in self-supervised learning have dramatically improved the state of the art on a wide variety of tasks. However, research in language model pre-training has mostly focused on natural languages, and it is unclear whether models like BERT and its variants provide the best pre-training when applied to other modalities, such as source code. In this paper, we introduce a new pre-training objective, DOBF, that leverages the structural aspect of programming languages and pre-trains a model to recover the original version of obfuscated source code. We show that models pre-trained with DOBF significantly outperform existing approaches on multiple downstream tasks, providing relative improvements of up to 13% in unsupervised code translation, and 24% in natural language code search. Incidentally, we found that our pre-trained model is able to de-obfuscate fully obfuscated source files, and to suggest descriptive variable names.