 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInkorrect: Online Handwriting Spelling Correction
Feb 28, 2022
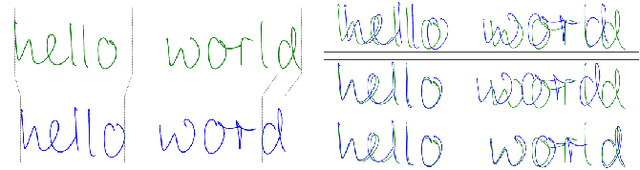

We introduce Inkorrect, a data- and label-efficient approach for online handwriting (Digital Ink) spelling correction - DISC. Unlike previous work, the proposed method does not require multiple samples from the same writer, or access to character level segmentation. We show that existing automatic evaluation metrics do not fully capture and are not correlated with the human perception of the quality of the spelling correction, and propose new ones that correlate with human perception. We additionally surface an interesting phenomenon: a trade-off between the similarity and recognizability of the spell-corrected inks. We further create a family of models corresponding to different points on the Pareto frontier between those two axes. We show that Inkorrect's Pareto frontier dominates the points that correspond to prior work.
Compact Nonlinear Maps and Circulant Extensions
Mar 12, 2015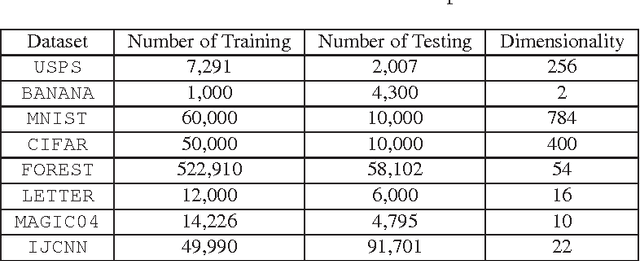
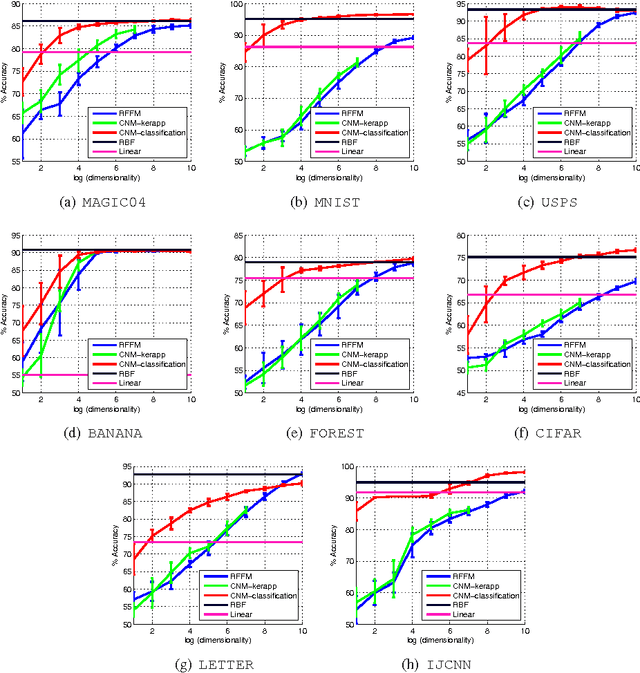
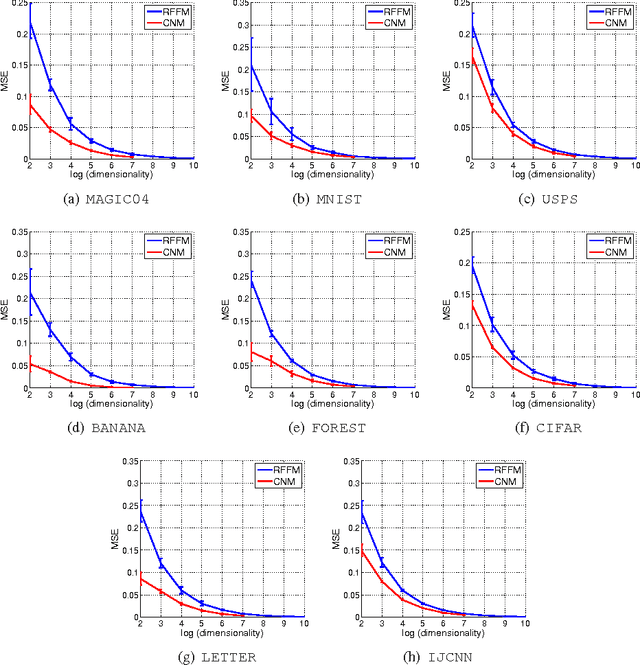

Kernel approximation via nonlinear random feature maps is widely used in speeding up kernel machines. There are two main challenges for the conventional kernel approximation methods. First, before performing kernel approximation, a good kernel has to be chosen. Picking a good kernel is a very challenging problem in itself. Second, high-dimensional maps are often required in order to achieve good performance. This leads to high computational cost in both generating the nonlinear maps, and in the subsequent learning and prediction process. In this work, we propose to optimize the nonlinear maps directly with respect to the classification objective in a data-dependent fashion. The proposed approach achieves kernel approximation and kernel learning in a joint framework. This leads to much more compact maps without hurting the performance. As a by-product, the same framework can also be used to achieve more compact kernel maps to approximate a known kernel. We also introduce Circulant Nonlinear Maps, which uses a circulant-structured projection matrix to speed up the nonlinear maps for high-dimensional data.