 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum-Guided Layer Scaling for Language Model Pretraining
Jun 13, 2025As the cost of pretraining large language models grows, there is continued interest in strategies to improve learning efficiency during this core training stage. Motivated by cognitive development, where humans gradually build knowledge as their brains mature, we propose Curriculum-Guided Layer Scaling (CGLS), a framework for compute-efficient pretraining that synchronizes increasing data difficulty with model growth through progressive layer stacking (i.e. gradually adding layers during training). At the 100M parameter scale, using a curriculum transitioning from synthetic short stories to general web data, CGLS outperforms baseline methods on the question-answering benchmarks PIQA and ARC. Pretraining at the 1.2B scale, we stratify the DataComp-LM corpus with a DistilBERT-based classifier and progress from general text to highly technical or specialized content. Our results show that progressively increasing model depth alongside sample difficulty leads to better generalization and zero-shot performance on various downstream benchmarks. Altogether, our findings demonstrate that CGLS unlocks the potential of progressive stacking, offering a simple yet effective strategy for improving generalization on knowledge-intensive and reasoning tasks.
Reasoning to Learn from Latent Thoughts
Mar 24, 2025Compute scaling for language model (LM) pretraining has outpaced the growth of human-written texts, leading to concerns that data will become the bottleneck to LM scaling. To continue scaling pretraining in this data-constrained regime, we propose that explicitly modeling and inferring the latent thoughts that underlie the text generation process can significantly improve pretraining data efficiency. Intuitively, our approach views web text as the compressed final outcome of a verbose human thought process and that the latent thoughts contain important contextual knowledge and reasoning steps that are critical to data-efficient learning. We empirically demonstrate the effectiveness of our approach through data-constrained continued pretraining for math. We first show that synthetic data approaches to inferring latent thoughts significantly improve data efficiency, outperforming training on the same amount of raw data (5.7\% $\rightarrow$ 25.4\% on MATH). Furthermore, we demonstrate latent thought inference without a strong teacher, where an LM bootstraps its own performance by using an EM algorithm to iteratively improve the capability of the trained LM and the quality of thought-augmented pretraining data. We show that a 1B LM can bootstrap its performance across at least three iterations and significantly outperform baselines trained on raw data, with increasing gains from additional inference compute when performing the E-step. The gains from inference scaling and EM iterations suggest new opportunities for scaling data-constrained pretraining.
Synthetic continued pretraining
Sep 11, 2024



Pretraining on large-scale, unstructured internet text has enabled language models to acquire a significant amount of world knowledge. However, this knowledge acquisition is data-inefficient -- to learn a given fact, models must be trained on hundreds to thousands of diverse representations of it. This poses a challenge when adapting a pretrained model to a small corpus of domain-specific documents, where each fact may appear rarely or only once. We propose to bridge this gap with synthetic continued pretraining: using the small domain-specific corpus to synthesize a large corpus more amenable to learning, and then performing continued pretraining on the synthesized corpus. We instantiate this proposal with EntiGraph, a synthetic data augmentation algorithm that extracts salient entities from the source documents and then generates diverse text by drawing connections between the sampled entities. Synthetic continued pretraining using EntiGraph enables a language model to answer questions and follow generic instructions related to the source documents without access to them. If instead, the source documents are available at inference time, we show that the knowledge acquired through our approach compounds with retrieval-augmented generation. To better understand these results, we build a simple mathematical model of EntiGraph, and show how synthetic data augmentation can "rearrange" knowledge to enable more data-efficient learning.
Linguistic Calibration of Language Models
Mar 30, 2024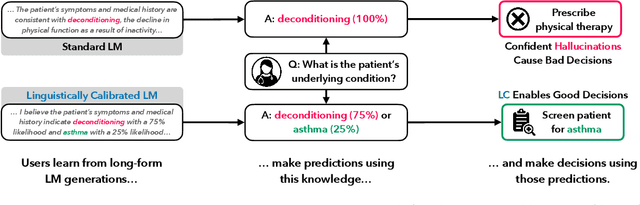

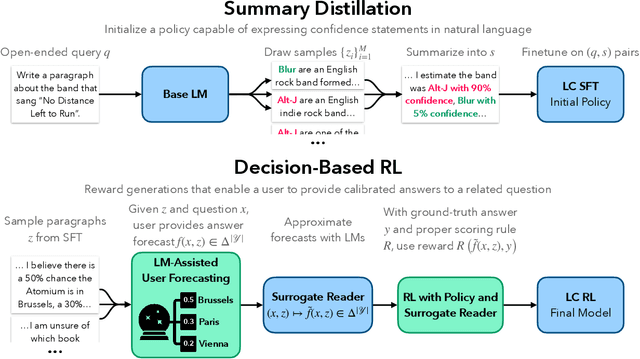
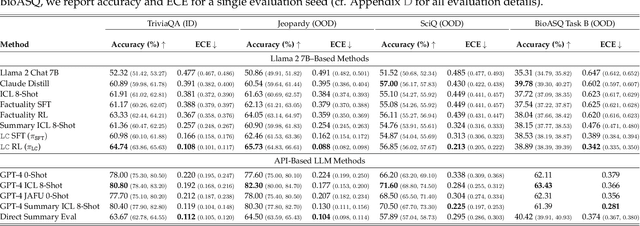
Language models (LMs) may lead their users to make suboptimal downstream decisions when they confidently hallucinate. This issue can be mitigated by having the LM verbally convey the probability that its claims are correct, but existing models cannot produce text with calibrated confidence statements. Through the lens of decision-making, we formalize linguistic calibration for long-form generations: an LM is linguistically calibrated if its generations enable its users to make calibrated probabilistic predictions. This definition enables a training framework where a supervised finetuning step bootstraps an LM to emit long-form generations with confidence statements such as "I estimate a 30% chance of..." or "I am certain that...", followed by a reinforcement learning step which rewards generations that enable a user to provide calibrated answers to related questions. We linguistically calibrate Llama 2 7B and find in automated and human evaluations of long-form generations that it is significantly more calibrated than strong finetuned factuality baselines with comparable accuracy. These findings generalize under distribution shift on question-answering and under a significant task shift to person biography generation. Our results demonstrate that long-form generations may be calibrated end-to-end by constructing an objective in the space of the predictions that users make in downstream decision-making.
Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Nov 23, 2022Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose the RETINA Benchmark, a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these tasks to benchmark well-established and state-of-the-art Bayesian deep learning methods on task-specific evaluation metrics. We provide an easy-to-use codebase for fast and easy benchmarking following reproducibility and software design principles. We provide implementations of all methods included in the benchmark as well as results computed over 100 TPU days, 20 GPU days, 400 hyperparameter configurations, and evaluation on at least 6 random seeds each.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022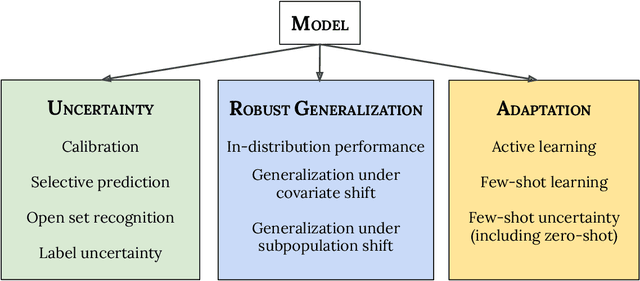

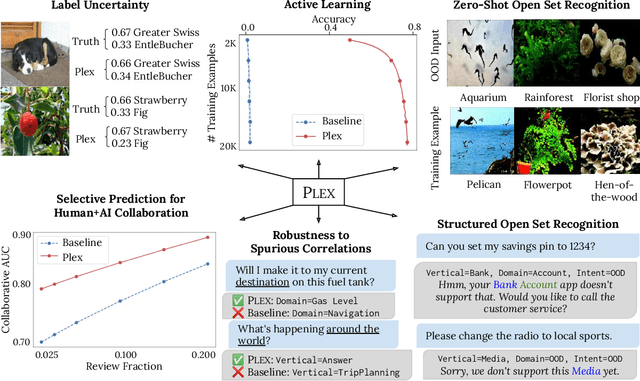

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021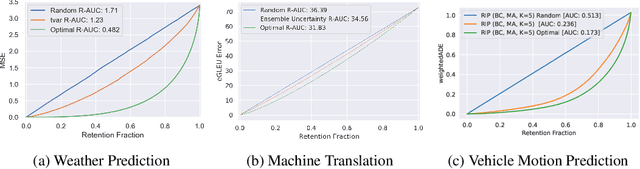
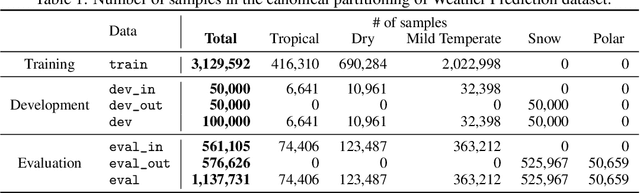
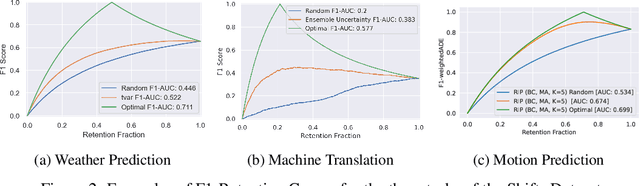
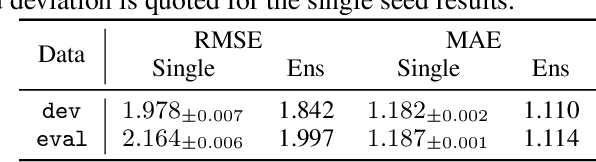
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021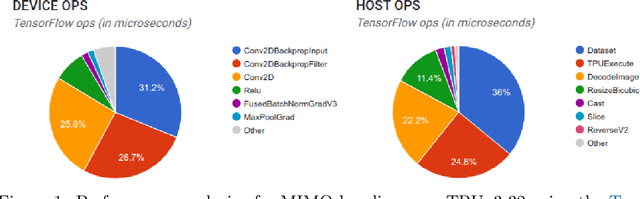
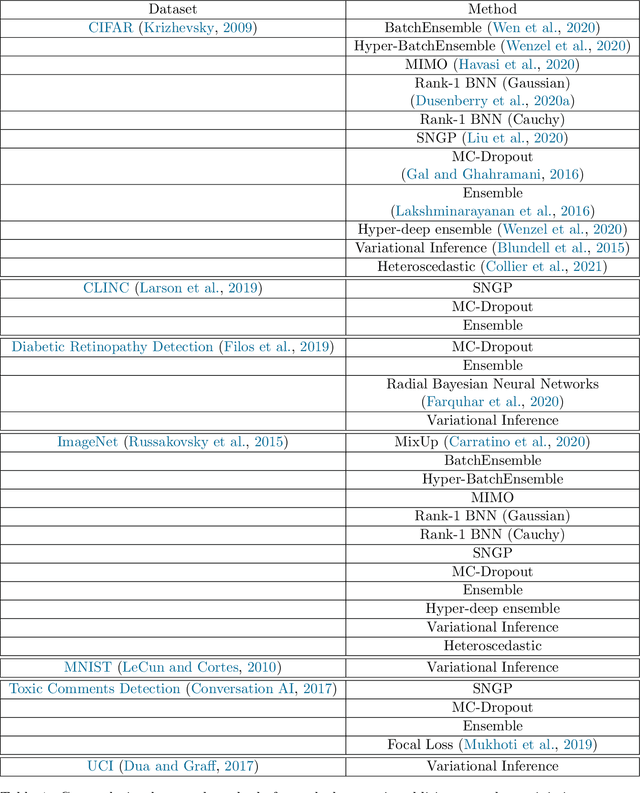
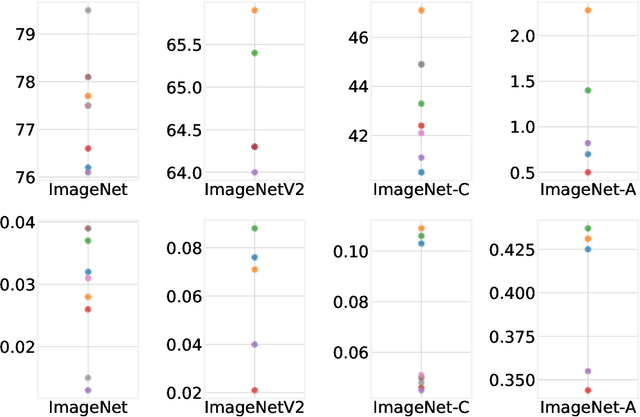
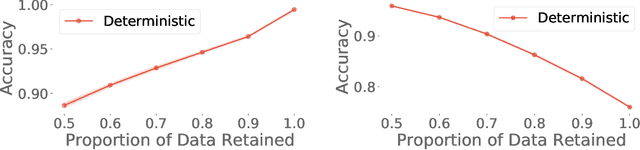
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
Jun 04, 2021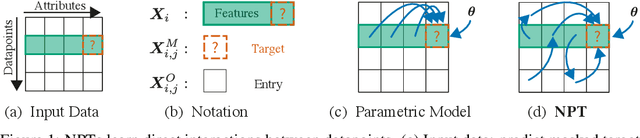
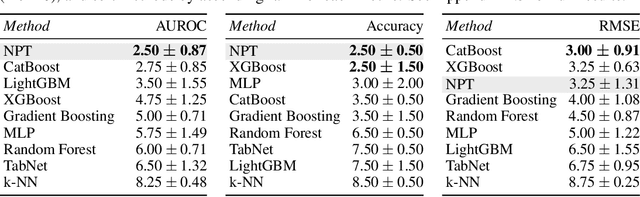
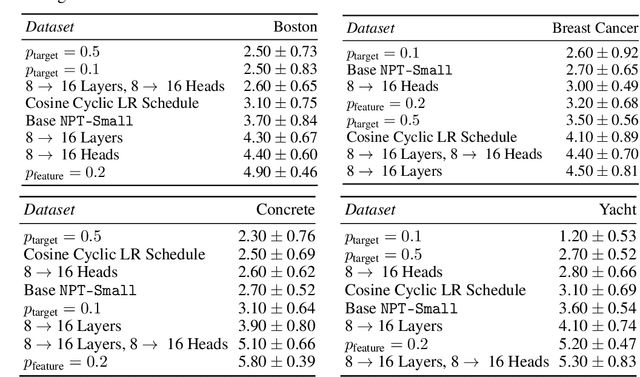

We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.