 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021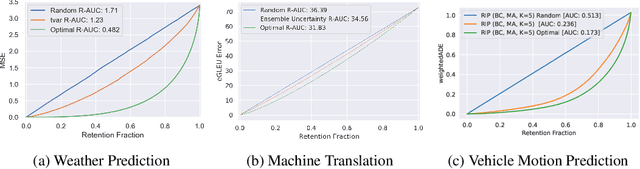
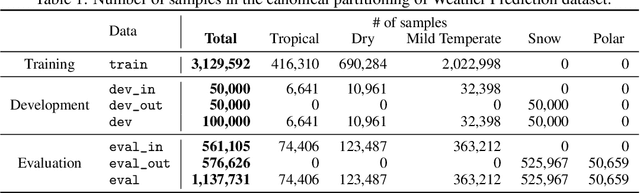
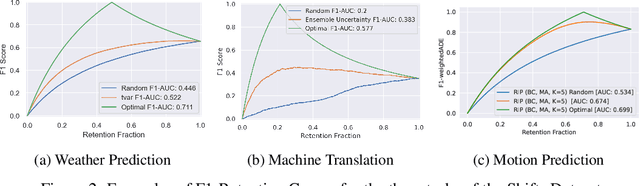
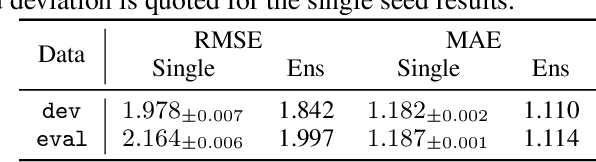
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
Strategic Attentive Writer for Learning Macro-Actions
Jun 15, 2016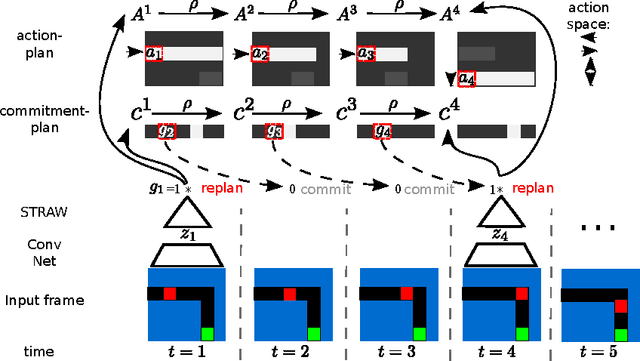


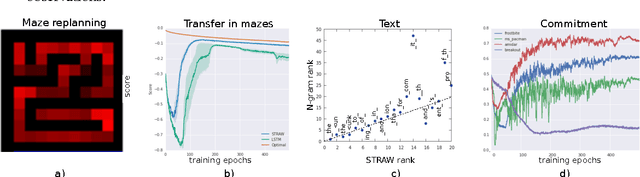
We present a novel deep recurrent neural network architecture that learns to build implicit plans in an end-to-end manner by purely interacting with an environment in reinforcement learning setting. The network builds an internal plan, which is continuously updated upon observation of the next input from the environment. It can also partition this internal representation into contiguous sub- sequences by learning for how long the plan can be committed to - i.e. followed without re-planing. Combining these properties, the proposed model, dubbed STRategic Attentive Writer (STRAW) can learn high-level, temporally abstracted macro- actions of varying lengths that are solely learnt from data without any prior information. These macro-actions enable both structured exploration and economic computation. We experimentally demonstrate that STRAW delivers strong improvements on several ATARI games by employing temporally extended planning strategies (e.g. Ms. Pacman and Frostbite). It is at the same time a general algorithm that can be applied on any sequence data. To that end, we also show that when trained on text prediction task, STRAW naturally predicts frequent n-grams (instead of macro-actions), demonstrating the generality of the approach.