 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Execution-Grounded Automated AI Research
Jan 20, 2026Automated AI research holds great potential to accelerate scientific discovery. However, current LLMs often generate plausible-looking but ineffective ideas. Execution grounding may help, but it is unclear whether automated execution is feasible and whether LLMs can learn from the execution feedback. To investigate these, we first build an automated executor to implement ideas and launch large-scale parallel GPU experiments to verify their effectiveness. We then convert two realistic research problems - LLM pre-training and post-training - into execution environments and demonstrate that our automated executor can implement a large fraction of the ideas sampled from frontier LLMs. We analyze two methods to learn from the execution feedback: evolutionary search and reinforcement learning. Execution-guided evolutionary search is sample-efficient: it finds a method that significantly outperforms the GRPO baseline (69.4% vs 48.0%) on post-training, and finds a pre-training recipe that outperforms the nanoGPT baseline (19.7 minutes vs 35.9 minutes) on pre-training, all within just ten search epochs. Frontier LLMs often generate meaningful algorithmic ideas during search, but they tend to saturate early and only occasionally exhibit scaling trends. Reinforcement learning from execution reward, on the other hand, suffers from mode collapse. It successfully improves the average reward of the ideator model but not the upper-bound, due to models converging on simple ideas. We thoroughly analyze the executed ideas and training dynamics to facilitate future efforts towards execution-grounded automated AI research.
Robust Sampling for Active Statistical Inference
Nov 12, 2025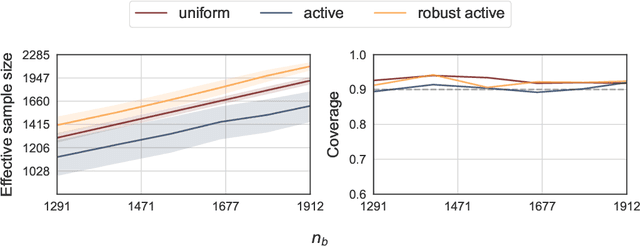
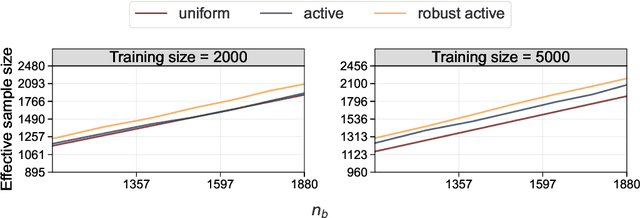
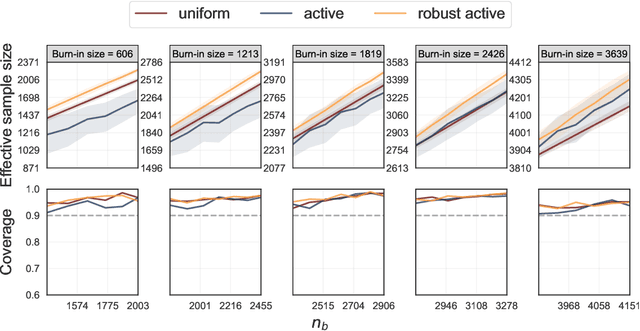
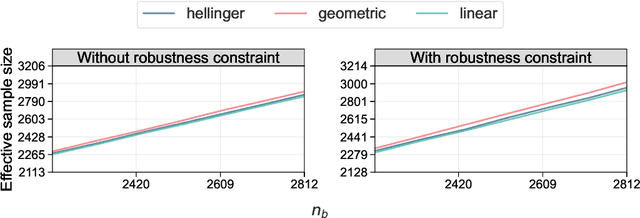
Active statistical inference is a new method for inference with AI-assisted data collection. Given a budget on the number of labeled data points that can be collected and assuming access to an AI predictive model, the basic idea is to improve estimation accuracy by prioritizing the collection of labels where the model is most uncertain. The drawback, however, is that inaccurate uncertainty estimates can make active sampling produce highly noisy results, potentially worse than those from naive uniform sampling. In this work, we present robust sampling strategies for active statistical inference. Robust sampling ensures that the resulting estimator is never worse than the estimator using uniform sampling. Furthermore, with reliable uncertainty estimates, the estimator usually outperforms standard active inference. This is achieved by optimally interpolating between uniform and active sampling, depending on the quality of the uncertainty scores, and by using ideas from robust optimization. We demonstrate the utility of the method on a series of real datasets from computational social science and survey research.
Synthetic bootstrapped pretraining
Sep 17, 2025We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers a significant fraction of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases -- SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents.
s1: Simple test-time scaling
Jan 31, 2025



Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts. We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end. This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised finetuning the Qwen2.5-32B-Instruct language model on s1K and equipping it with budget forcing, our model s1 exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24). Further, scaling s1 with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24. Our model, data, and code are open-source at https://github.com/simplescaling/s1.
Synthetic continued pretraining
Sep 11, 2024



Pretraining on large-scale, unstructured internet text has enabled language models to acquire a significant amount of world knowledge. However, this knowledge acquisition is data-inefficient -- to learn a given fact, models must be trained on hundreds to thousands of diverse representations of it. This poses a challenge when adapting a pretrained model to a small corpus of domain-specific documents, where each fact may appear rarely or only once. We propose to bridge this gap with synthetic continued pretraining: using the small domain-specific corpus to synthesize a large corpus more amenable to learning, and then performing continued pretraining on the synthesized corpus. We instantiate this proposal with EntiGraph, a synthetic data augmentation algorithm that extracts salient entities from the source documents and then generates diverse text by drawing connections between the sampled entities. Synthetic continued pretraining using EntiGraph enables a language model to answer questions and follow generic instructions related to the source documents without access to them. If instead, the source documents are available at inference time, we show that the knowledge acquired through our approach compounds with retrieval-augmented generation. To better understand these results, we build a simple mathematical model of EntiGraph, and show how synthetic data augmentation can "rearrange" knowledge to enable more data-efficient learning.
A Library of Mirrors: Deep Neural Nets in Low Dimensions are Convex Lasso Models with Reflection Features
Mar 02, 2024



We prove that training neural networks on 1-D data is equivalent to solving a convex Lasso problem with a fixed, explicitly defined dictionary matrix of features. The specific dictionary depends on the activation and depth. We consider 2-layer networks with piecewise linear activations, deep narrow ReLU networks with up to 4 layers, and rectangular and tree networks with sign activation and arbitrary depth. Interestingly in ReLU networks, a fourth layer creates features that represent reflections of training data about themselves. The Lasso representation sheds insight to globally optimal networks and the solution landscape.
Bellman Conformal Inference: Calibrating Prediction Intervals For Time Series
Feb 09, 2024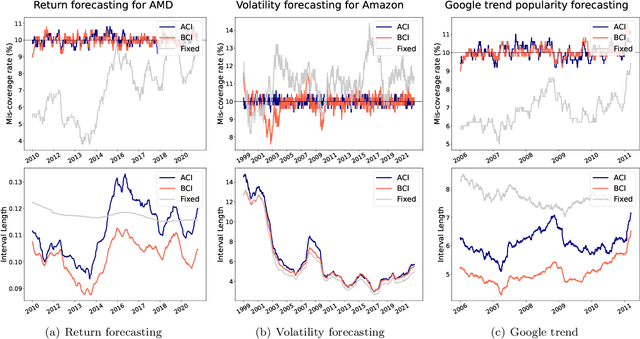
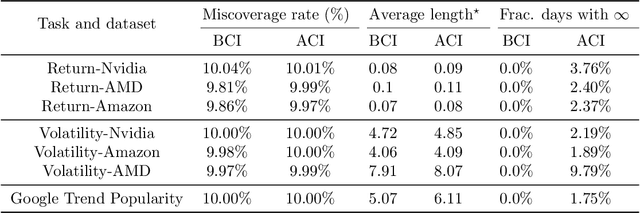
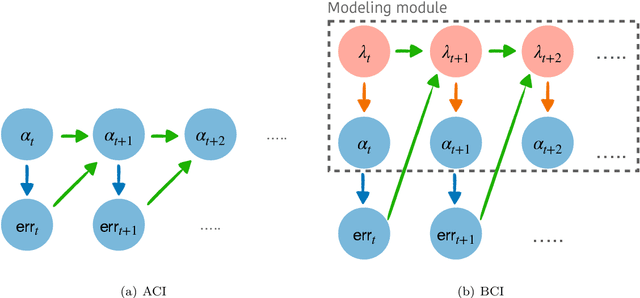
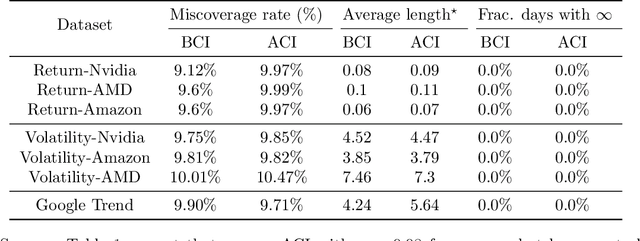
We introduce Bellman Conformal Inference (BCI), a framework that wraps around any time series forecasting models and provides approximately calibrated prediction intervals. Unlike existing methods, BCI is able to leverage multi-step ahead forecasts and explicitly optimize the average interval lengths by solving a one-dimensional stochastic control problem (SCP) at each time step. In particular, we use the dynamic programming algorithm to find the optimal policy for the SCP. We prove that BCI achieves long-term coverage under arbitrary distribution shifts and temporal dependence, even with poor multi-step ahead forecasts. We find empirically that BCI avoids uninformative intervals that have infinite lengths and generates substantially shorter prediction intervals in multiple applications when compared with existing methods.
Conformal Inference for Online Prediction with Arbitrary Distribution Shifts
Aug 17, 2022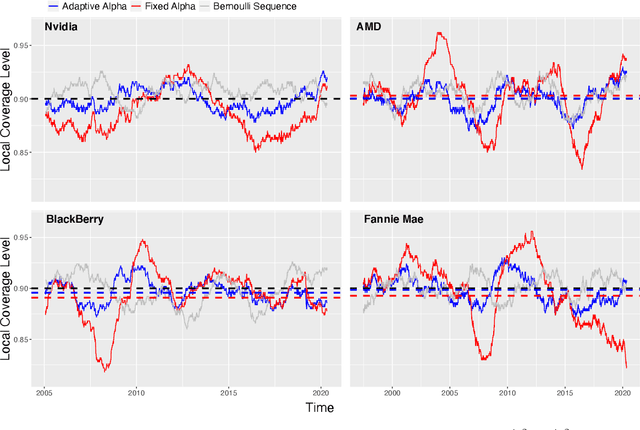

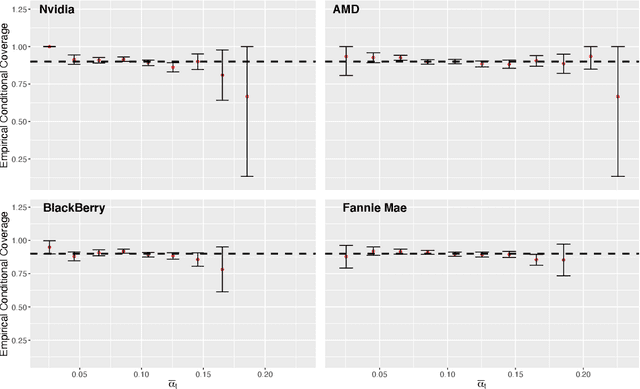
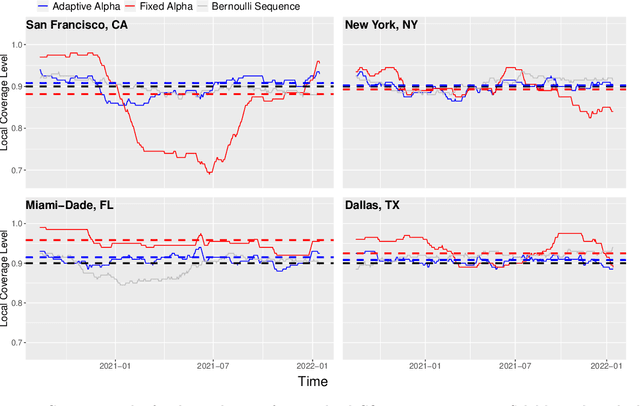
Conformal inference is a flexible methodology for transforming the predictions made by any black-box model (e.g. neural nets, random forests) into valid prediction sets. The only necessary assumption is that the training and test data be exchangeable (e.g. i.i.d.). Unfortunately, this assumption is usually unrealistic in online environments in which the processing generating the data may vary in time and consecutive data-points are often temporally correlated. In this article, we develop an online algorithm for producing prediction intervals that are robust to these deviations. Our methods build upon conformal inference and thus can be combined with any black-box predictor. We show that the coverage error of our algorithm is controlled by the size of the underlying change in the environment and thus directly connect the size of the distribution shift with the difficulty of the prediction problem. Finally, we apply our procedure in two real-world settings and find that our method produces robust prediction intervals under real-world dynamics.
Testing for Outliers with Conformal p-values
Apr 19, 2021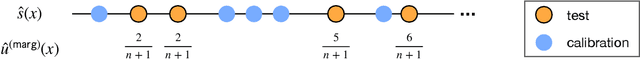

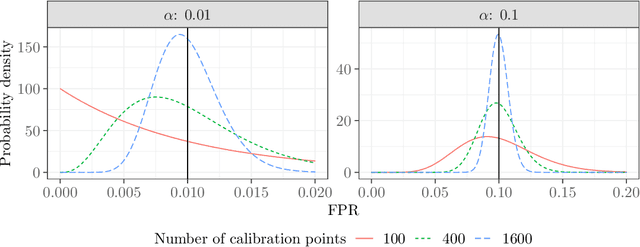
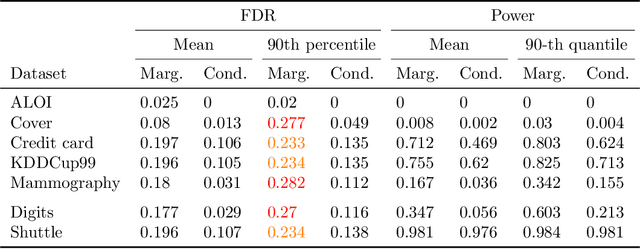
This paper studies the construction of p-values for nonparametric outlier detection, taking a multiple-testing perspective. The goal is to test whether new independent samples belong to the same distribution as a reference data set or are outliers. We propose a solution based on conformal inference, a broadly applicable framework which yields p-values that are marginally valid but mutually dependent for different test points. We prove these p-values are positively dependent and enable exact false discovery rate control, although in a relatively weak marginal sense. We then introduce a new method to compute p-values that are both valid conditionally on the training data and independent of each other for different test points; this paves the way to stronger type-I error guarantees. Our results depart from classical conformal inference as we leverage concentration inequalities rather than combinatorial arguments to establish our finite-sample guarantees. Furthermore, our techniques also yield a uniform confidence bound for the false positive rate of any outlier detection algorithm, as a function of the threshold applied to its raw statistics. Finally, the relevance of our results is demonstrated by numerical experiments on real and simulated data.