 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Adaptive Multi-Objective Learning
Feb 16, 2026We consider the general problem of learning a predictor that satisfies multiple objectives of interest simultaneously, a broad framework that captures a range of specific learning goals including calibration, regret, and multiaccuracy. We work in an online setting where the data distribution can change arbitrarily over time. Existing approaches to this problem aim to minimize the set of objectives over the entire time horizon in a worst-case sense, and in practice they do not necessarily adapt to distribution shifts. Earlier work has aimed to alleviate this problem by incorporating additional objectives that target local guarantees over contiguous subintervals. Empirical evaluation of these proposals is, however, scarce. In this article, we consider an alternative procedure that achieves local adaptivity by replacing one part of the multi-objective learning method with an adaptive online algorithm. Empirical evaluations on datasets from energy forecasting and algorithmic fairness show that our proposed method improves upon existing approaches and achieves unbiased predictions over subgroups, while remaining robust under distribution shift.
Calibrated Multi-Level Quantile Forecasting
Dec 29, 2025We present an online method for guaranteeing calibration of quantile forecasts at multiple quantile levels simultaneously. A sequence of $α$-level quantile forecasts is calibrated if the forecasts are larger than the target value at an $α$-fraction of time steps. We introduce a lightweight method called Multi-Level Quantile Tracker (MultiQT) that wraps around any existing point or quantile forecaster to produce corrected forecasts guaranteed to achieve calibration, even against adversarial distribution shifts, while ensuring that the forecasts are ordered -- e.g., the 0.5-level quantile forecast is never larger than the 0.6-level forecast. Furthermore, the method comes with a no-regret guarantee that implies it will not worsen the performance of an existing forecaster, asymptotically, with respect to the quantile loss. In experiments, we find that MultiQT significantly improves the calibration of real forecasters in epidemic and energy forecasting problems.
Sample-Efficient Omniprediction for Proper Losses
Oct 14, 2025We consider the problem of constructing probabilistic predictions that lead to accurate decisions when employed by downstream users to inform actions. For a single decision maker, designing an optimal predictor is equivalent to minimizing a proper loss function corresponding to the negative utility of that individual. For multiple decision makers, our problem can be viewed as a variant of omniprediction in which the goal is to design a single predictor that simultaneously minimizes multiple losses. Existing algorithms for achieving omniprediction broadly fall into two categories: 1) boosting methods that optimize other auxiliary targets such as multicalibration and obtain omniprediction as a corollary, and 2) adversarial two-player game based approaches that estimate and respond to the ``worst-case" loss in an online fashion. We give lower bounds demonstrating that multicalibration is a strictly more difficult problem than omniprediction and thus the former approach must incur suboptimal sample complexity. For the latter approach, we discuss how these ideas can be used to obtain a sample-efficient algorithm through an online-to-batch conversion. This conversion has the downside of returning a complex, randomized predictor. We improve on this method by designing a more direct, unrandomized algorithm that exploits structural elements of the set of proper losses.
Large language model validity via enhanced conformal prediction methods
Jun 14, 2024We develop new conformal inference methods for obtaining validity guarantees on the output of large language models (LLMs). Prior work in conformal language modeling identifies a subset of the text that satisfies a high-probability guarantee of correctness. These methods work by filtering claims from the LLM's original response if a scoring function evaluated on the claim fails to exceed a threshold calibrated via split conformal prediction. Existing methods in this area suffer from two deficiencies. First, the guarantee stated is not conditionally valid. The trustworthiness of the filtering step may vary based on the topic of the response. Second, because the scoring function is imperfect, the filtering step can remove many valuable and accurate claims. We address both of these challenges via two new conformal methods. First, we generalize the conditional conformal procedure of Gibbs et al. (2023) in order to adaptively issue weaker guarantees when they are required to preserve the utility of the output. Second, we show how to systematically improve the quality of the scoring function via a novel algorithm for differentiating through the conditional conformal procedure. We demonstrate the efficacy of our approach on both synthetic and real-world datasets.
Conformal Inference for Online Prediction with Arbitrary Distribution Shifts
Aug 17, 2022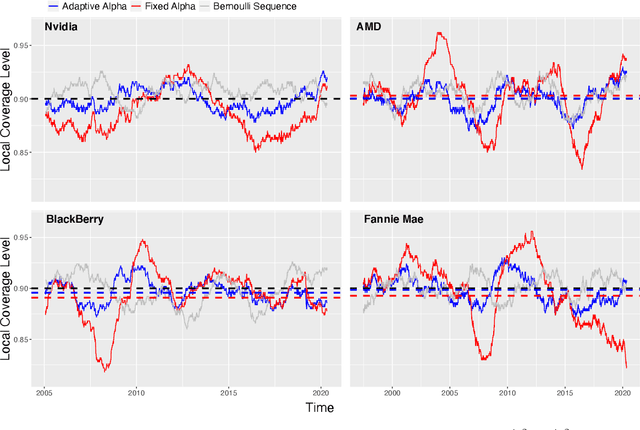

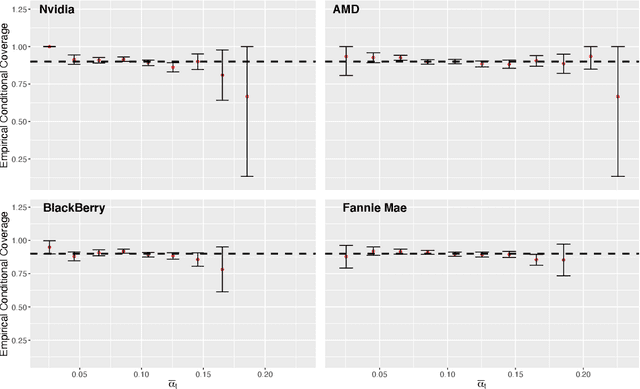
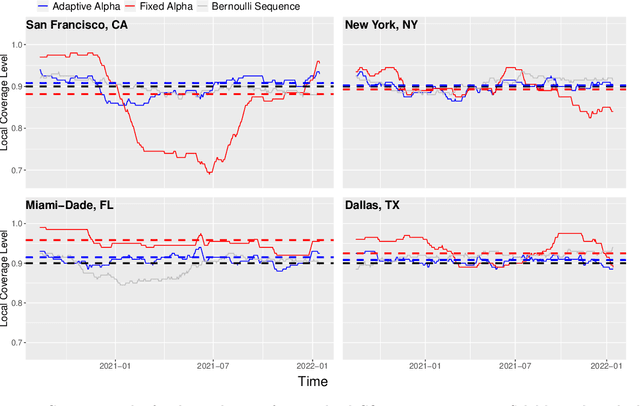
Conformal inference is a flexible methodology for transforming the predictions made by any black-box model (e.g. neural nets, random forests) into valid prediction sets. The only necessary assumption is that the training and test data be exchangeable (e.g. i.i.d.). Unfortunately, this assumption is usually unrealistic in online environments in which the processing generating the data may vary in time and consecutive data-points are often temporally correlated. In this article, we develop an online algorithm for producing prediction intervals that are robust to these deviations. Our methods build upon conformal inference and thus can be combined with any black-box predictor. We show that the coverage error of our algorithm is controlled by the size of the underlying change in the environment and thus directly connect the size of the distribution shift with the difficulty of the prediction problem. Finally, we apply our procedure in two real-world settings and find that our method produces robust prediction intervals under real-world dynamics.