 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Calibration of Language Models
Paper and Code
Mar 30, 2024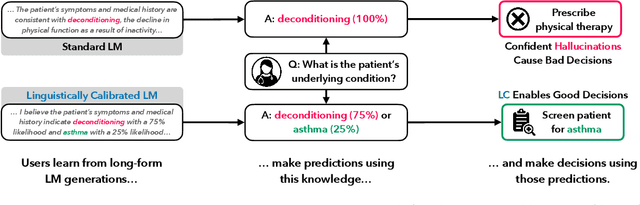

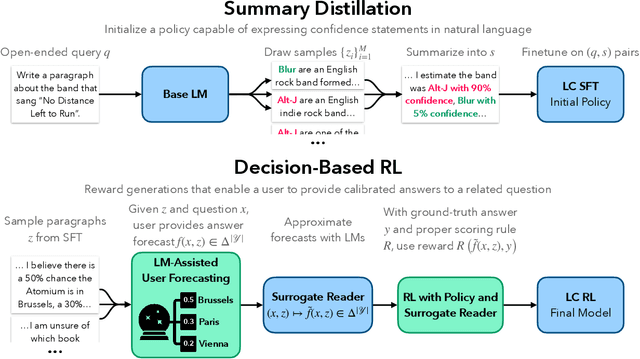
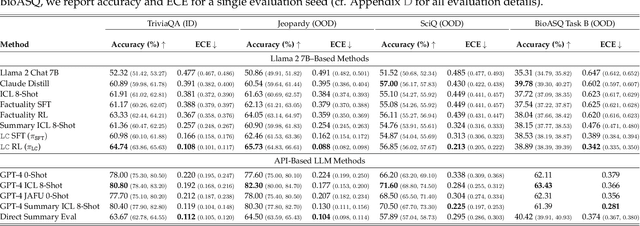
Language models (LMs) may lead their users to make suboptimal downstream decisions when they confidently hallucinate. This issue can be mitigated by having the LM verbally convey the probability that its claims are correct, but existing models cannot produce text with calibrated confidence statements. Through the lens of decision-making, we formalize linguistic calibration for long-form generations: an LM is linguistically calibrated if its generations enable its users to make calibrated probabilistic predictions. This definition enables a training framework where a supervised finetuning step bootstraps an LM to emit long-form generations with confidence statements such as "I estimate a 30% chance of..." or "I am certain that...", followed by a reinforcement learning step which rewards generations that enable a user to provide calibrated answers to related questions. We linguistically calibrate Llama 2 7B and find in automated and human evaluations of long-form generations that it is significantly more calibrated than strong finetuned factuality baselines with comparable accuracy. These findings generalize under distribution shift on question-answering and under a significant task shift to person biography generation. Our results demonstrate that long-form generations may be calibrated end-to-end by constructing an objective in the space of the predictions that users make in downstream decision-making.