 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting It All into Context: Simplifying Agents with LCLMs
May 12, 2025Recent advances in language model (LM) agents have demonstrated significant potential for automating complex real-world tasks. To make progress on these difficult tasks, LM agent architectures have become increasingly complex, often incorporating multi-step retrieval tools, multiple agents, and scaffolding adapted to the underlying LM. In this work, we investigate whether all of this complexity is necessary, or if parts of these scaffolds can be removed on challenging tasks like SWE-bench. We show that in the case of SWE-bench, simply putting the entire environment into the context of a long context language model (LCLM) and properly prompting the model makes it competitive with carefully tuned, complex agent scaffolds. We show that a Gemini-1.5-Pro model without any scaffolding or tools achieves 38% on SWE-Bench-Verified, comparable with approaches using carefully tuned agent scaffolds (32%). While the unscaffolded approach with Gemini-1.5-Pro falls short of the strongest agentic architectures, we demonstrate that the more capable Gemini-2.5-Pro using the same unscaffolded approach directly attains a 50.8% solve rate. Additionally, a two-stage approach combining Gemini-1.5-Pro with Claude-3.7 achieves a competitive 48.6% solve rate.
Reasoning to Learn from Latent Thoughts
Mar 24, 2025Compute scaling for language model (LM) pretraining has outpaced the growth of human-written texts, leading to concerns that data will become the bottleneck to LM scaling. To continue scaling pretraining in this data-constrained regime, we propose that explicitly modeling and inferring the latent thoughts that underlie the text generation process can significantly improve pretraining data efficiency. Intuitively, our approach views web text as the compressed final outcome of a verbose human thought process and that the latent thoughts contain important contextual knowledge and reasoning steps that are critical to data-efficient learning. We empirically demonstrate the effectiveness of our approach through data-constrained continued pretraining for math. We first show that synthetic data approaches to inferring latent thoughts significantly improve data efficiency, outperforming training on the same amount of raw data (5.7\% $\rightarrow$ 25.4\% on MATH). Furthermore, we demonstrate latent thought inference without a strong teacher, where an LM bootstraps its own performance by using an EM algorithm to iteratively improve the capability of the trained LM and the quality of thought-augmented pretraining data. We show that a 1B LM can bootstrap its performance across at least three iterations and significantly outperform baselines trained on raw data, with increasing gains from additional inference compute when performing the E-step. The gains from inference scaling and EM iterations suggest new opportunities for scaling data-constrained pretraining.
Graph-based Uncertainty Metrics for Long-form Language Model Outputs
Oct 28, 2024



Recent advancements in Large Language Models (LLMs) have significantly improved text generation capabilities, but these systems are still known to hallucinate, and granular uncertainty estimation for long-form LLM generations remains challenging. In this work, we propose Graph Uncertainty -- which represents the relationship between LLM generations and claims within them as a bipartite graph and estimates the claim-level uncertainty with a family of graph centrality metrics. Under this view, existing uncertainty estimation methods based on the concept of self-consistency can be viewed as using degree centrality as an uncertainty measure, and we show that more sophisticated alternatives such as closeness centrality provide consistent gains at claim-level uncertainty estimation. Moreover, we present uncertainty-aware decoding techniques that leverage both the graph structure and uncertainty estimates to improve the factuality of LLM generations by preserving only the most reliable claims. Compared to existing methods, our graph-based uncertainty metrics lead to an average of 6.8% relative gains on AUPRC across various long-form generation settings, and our end-to-end system provides consistent 2-4% gains in factuality over existing decoding techniques while significantly improving the informativeness of generated responses.
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
Jun 19, 2024Large Language Models (LLMs) have become increasingly capable of handling diverse tasks with the aid of well-crafted prompts and integration of external tools, but as task complexity rises, the workflow involving LLMs can be complicated and thus challenging to implement and maintain. To address this challenge, we propose APPL, A Prompt Programming Language that acts as a bridge between computer programs and LLMs, allowing seamless embedding of prompts into Python functions, and vice versa. APPL provides an intuitive and Python-native syntax, an efficient parallelized runtime with asynchronous semantics, and a tracing module supporting effective failure diagnosis and replaying without extra costs. We demonstrate that APPL programs are intuitive, concise, and efficient through three representative scenarios: Chain-of-Thought with self-consistency (CoT-SC), ReAct tool use agent, and multi-agent chat. Experiments on three parallelizable workflows further show that APPL can effectively parallelize independent LLM calls, with a significant speedup ratio that almost matches the estimation.
Observational Scaling Laws and the Predictability of Language Model Performance
May 17, 2024

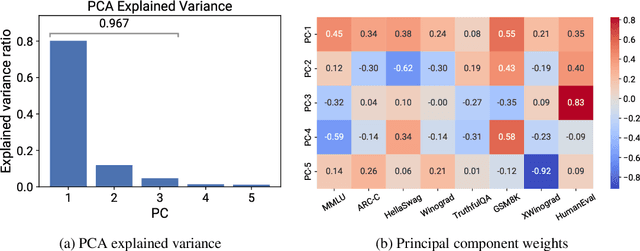

Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Sep 25, 2023



Recent advances in Language Model (LM) agents and tool use, exemplified by applications like ChatGPT Plugins, enable a rich set of capabilities but also amplify potential risks - such as leaking private data or causing financial losses. Identifying these risks is labor-intensive, necessitating implementing the tools, manually setting up the environment for each test scenario, and finding risky cases. As tools and agents become more complex, the high cost of testing these agents will make it increasingly difficult to find high-stakes, long-tailed risks. To address these challenges, we introduce ToolEmu: a framework that uses an LM to emulate tool execution and enables the testing of LM agents against a diverse range of tools and scenarios, without manual instantiation. Alongside the emulator, we develop an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks. We test both the tool emulator and evaluator through human evaluation and find that 68.8% of failures identified with ToolEmu would be valid real-world agent failures. Using our curated initial benchmark consisting of 36 high-stakes tools and 144 test cases, we provide a quantitative risk analysis of current LM agents and identify numerous failures with potentially severe outcomes. Notably, even the safest LM agent exhibits such failures 23.9% of the time according to our evaluator, underscoring the need to develop safer LM agents for real-world deployment.
Weighted Ensemble Self-Supervised Learning
Nov 18, 2022


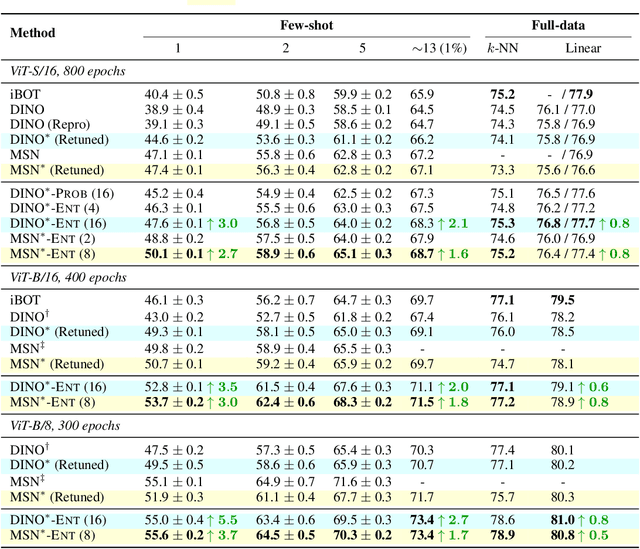
Ensembling has proven to be a powerful technique for boosting model performance, uncertainty estimation, and robustness in supervised learning. Advances in self-supervised learning (SSL) enable leveraging large unlabeled corpora for state-of-the-art few-shot and supervised learning performance. In this paper, we explore how ensemble methods can improve recent SSL techniques by developing a framework that permits data-dependent weighted cross-entropy losses. We refrain from ensembling the representation backbone; this choice yields an efficient ensemble method that incurs a small training cost and requires no architectural changes or computational overhead to downstream evaluation. The effectiveness of our method is demonstrated with two state-of-the-art SSL methods, DINO (Caron et al., 2021) and MSN (Assran et al., 2022). Our method outperforms both in multiple evaluation metrics on ImageNet-1K, particularly in the few-shot setting. We explore several weighting schemes and find that those which increase the diversity of ensemble heads lead to better downstream evaluation results. Thorough experiments yield improved prior art baselines which our method still surpasses; e.g., our overall improvement with MSN ViT-B/16 is 3.9 p.p. for 1-shot learning.
Augment with Care: Contrastive Learning for the Boolean Satisfiability Problem
Feb 17, 2022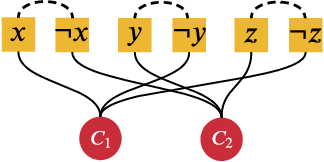
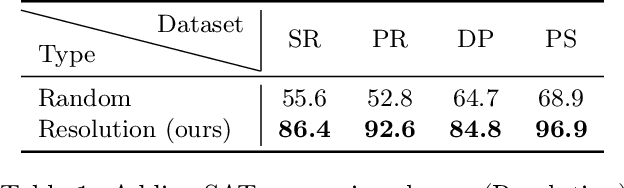
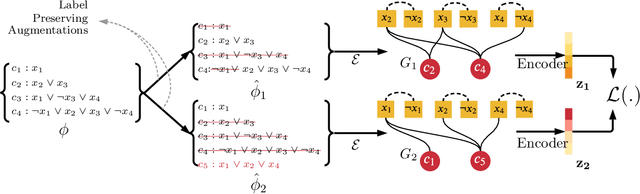
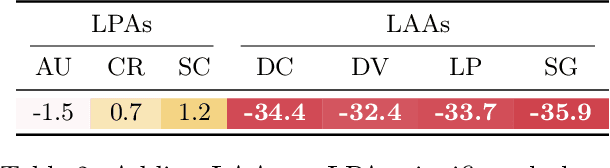
Supervised learning can improve the design of state-of-the-art solvers for combinatorial problems, but labelling large numbers of combinatorial instances is often impractical due to exponential worst-case complexity. Inspired by the recent success of contrastive pre-training for images, we conduct a scientific study of the effect of augmentation design on contrastive pre-training for the Boolean satisfiability problem. While typical graph contrastive pre-training uses label-agnostic augmentations, our key insight is that many combinatorial problems have well-studied invariances, which allow for the design of label-preserving augmentations. We find that label-preserving augmentations are critical for the success of contrastive pre-training. We show that our representations are able to achieve comparable test accuracy to fully-supervised learning while using only 1% of the labels. We also demonstrate that our representations are more transferable to larger problems from unseen domains.
Optimal Representations for Covariate Shift
Dec 31, 2021

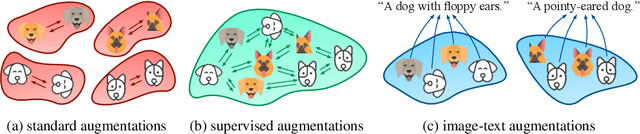

Machine learning systems often experience a distribution shift between training and testing. In this paper, we introduce a simple variational objective whose optima are exactly the set of all representations on which risk minimizers are guaranteed to be robust to any distribution shift that preserves the Bayes predictor, e.g., covariate shifts. Our objective has two components. First, a representation must remain discriminative for the task, i.e., some predictor must be able to simultaneously minimize the source and target risk. Second, the representation's marginal support needs to be the same across source and target. We make this practical by designing self-supervised learning methods that only use unlabelled data and augmentations to train robust representations. Our objectives achieve state-of-the-art results on DomainBed, and give insights into the robustness of recent methods, such as CLIP.
Improving Lossless Compression Rates via Monte Carlo Bits-Back Coding
Feb 22, 2021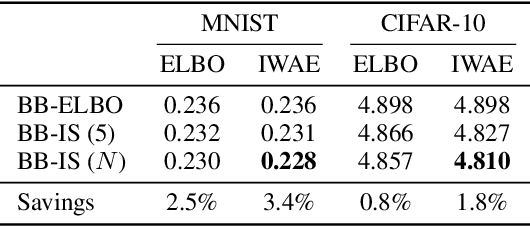
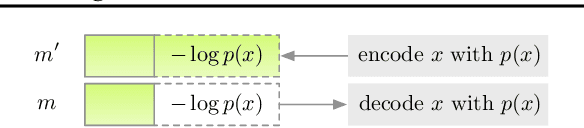
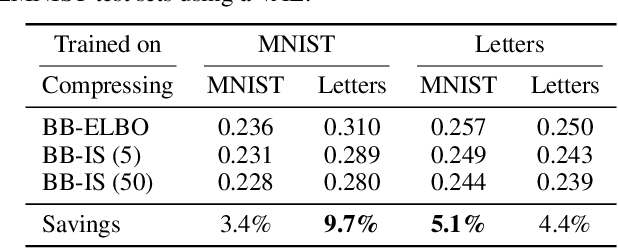
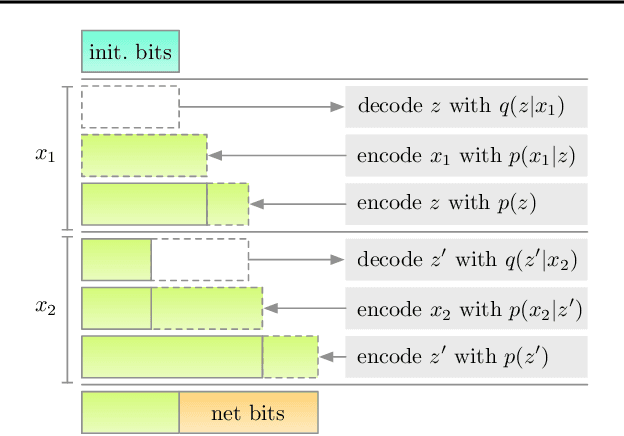
Latent variable models have been successfully applied in lossless compression with the bits-back coding algorithm. However, bits-back suffers from an increase in the bitrate equal to the KL divergence between the approximate posterior and the true posterior. In this paper, we show how to remove this gap asymptotically by deriving bits-back coding algorithms from tighter variational bounds. The key idea is to exploit extended space representations of Monte Carlo estimators of the marginal likelihood. Naively applied, our schemes would require more initial bits than the standard bits-back coder, but we show how to drastically reduce this additional cost with couplings in the latent space. When parallel architectures can be exploited, our coders can achieve better rates than bits-back with little additional cost. We demonstrate improved lossless compression rates in a variety of settings, including entropy coding for lossy compression.