 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample what you cant compress
Sep 04, 2024



For learned image representations, basic autoencoders often produce blurry results. Reconstruction quality can be improved by incorporating additional penalties such as adversarial (GAN) and perceptual losses. Arguably, these approaches lack a principled interpretation. Concurrently, in generative settings diffusion has demonstrated a remarkable ability to create crisp, high quality results and has solid theoretical underpinnings (from variational inference to direct study as the Fisher Divergence). Our work combines autoencoder representation learning with diffusion and is, to our knowledge, the first to demonstrate the efficacy of jointly learning a continuous encoder and decoder under a diffusion-based loss. We demonstrate that this approach yields better reconstruction quality as compared to GAN-based autoencoders while being easier to tune. We also show that the resulting representation is easier to model with a latent diffusion model as compared to the representation obtained from a state-of-the-art GAN-based loss. Since our decoder is stochastic, it can generate details not encoded in the otherwise deterministic latent representation; we therefore name our approach "Sample what you can't compress", or SWYCC for short.
Weighted Ensemble Self-Supervised Learning
Nov 18, 2022


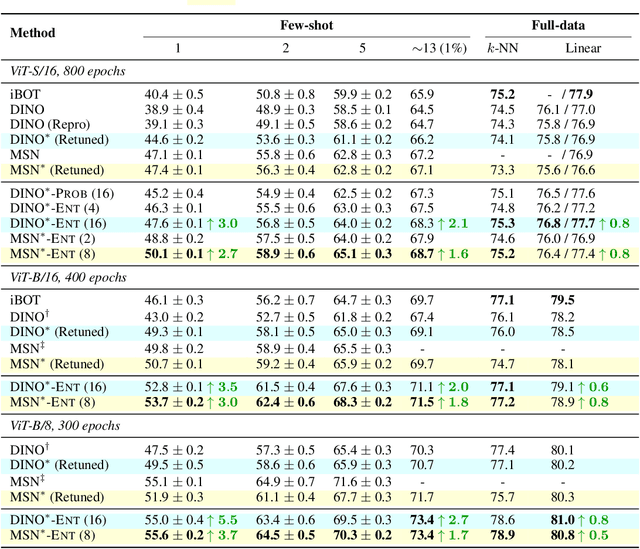
Ensembling has proven to be a powerful technique for boosting model performance, uncertainty estimation, and robustness in supervised learning. Advances in self-supervised learning (SSL) enable leveraging large unlabeled corpora for state-of-the-art few-shot and supervised learning performance. In this paper, we explore how ensemble methods can improve recent SSL techniques by developing a framework that permits data-dependent weighted cross-entropy losses. We refrain from ensembling the representation backbone; this choice yields an efficient ensemble method that incurs a small training cost and requires no architectural changes or computational overhead to downstream evaluation. The effectiveness of our method is demonstrated with two state-of-the-art SSL methods, DINO (Caron et al., 2021) and MSN (Assran et al., 2022). Our method outperforms both in multiple evaluation metrics on ImageNet-1K, particularly in the few-shot setting. We explore several weighting schemes and find that those which increase the diversity of ensemble heads lead to better downstream evaluation results. Thorough experiments yield improved prior art baselines which our method still surpasses; e.g., our overall improvement with MSN ViT-B/16 is 3.9 p.p. for 1-shot learning.
Towards a Semantic Perceptual Image Metric
Aug 01, 2018
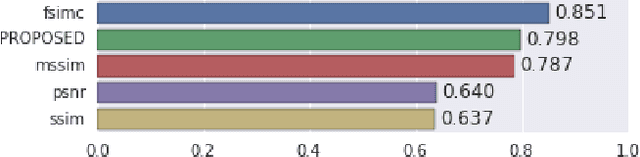
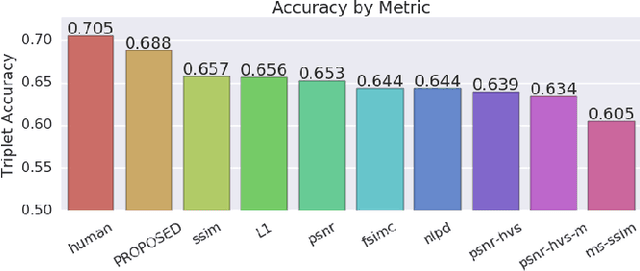

We present a full reference, perceptual image metric based on VGG-16, an artificial neural network trained on object classification. We fit the metric to a new database based on 140k unique images annotated with ground truth by human raters who received minimal instruction. The resulting metric shows competitive performance on TID 2013, a database widely used to assess image quality assessments methods. More interestingly, it shows strong responses to objects potentially carrying semantic relevance such as faces and text, which we demonstrate using a visualization technique and ablation experiments. In effect, the metric appears to model a higher influence of semantic context on judgments, which we observe particularly in untrained raters. As the vast majority of users of image processing systems are unfamiliar with Image Quality Assessment (IQA) tasks, these findings may have significant impact on real-world applications of perceptual metrics.
No Fuss Distance Metric Learning using Proxies
Aug 01, 2017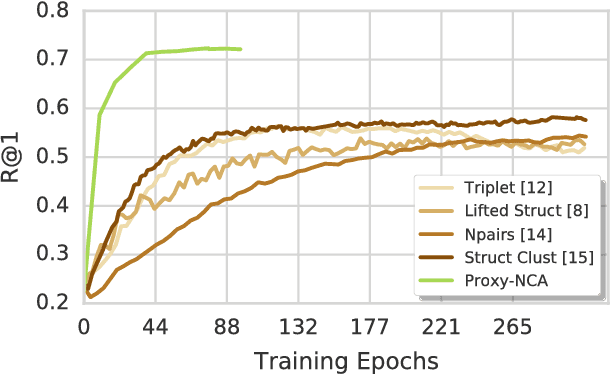
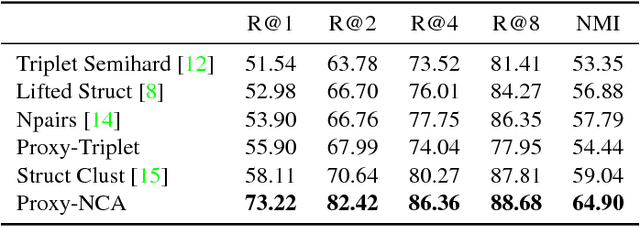
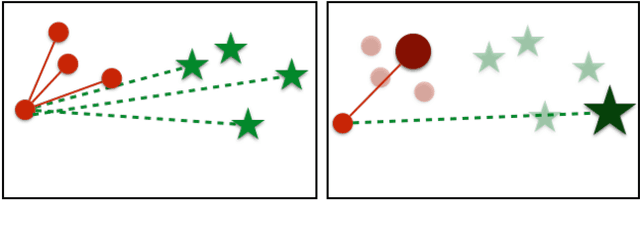
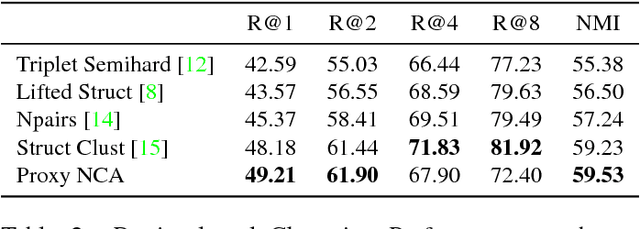
We address the problem of distance metric learning (DML), defined as learning a distance consistent with a notion of semantic similarity. Traditionally, for this problem supervision is expressed in the form of sets of points that follow an ordinal relationship -- an anchor point $x$ is similar to a set of positive points $Y$, and dissimilar to a set of negative points $Z$, and a loss defined over these distances is minimized. While the specifics of the optimization differ, in this work we collectively call this type of supervision Triplets and all methods that follow this pattern Triplet-Based methods. These methods are challenging to optimize. A main issue is the need for finding informative triplets, which is usually achieved by a variety of tricks such as increasing the batch size, hard or semi-hard triplet mining, etc. Even with these tricks, the convergence rate of such methods is slow. In this paper we propose to optimize the triplet loss on a different space of triplets, consisting of an anchor data point and similar and dissimilar proxy points which are learned as well. These proxies approximate the original data points, so that a triplet loss over the proxies is a tight upper bound of the original loss. This proxy-based loss is empirically better behaved. As a result, the proxy-loss improves on state-of-art results for three standard zero-shot learning datasets, by up to 15% points, while converging three times as fast as other triplet-based losses.
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Aug 23, 2016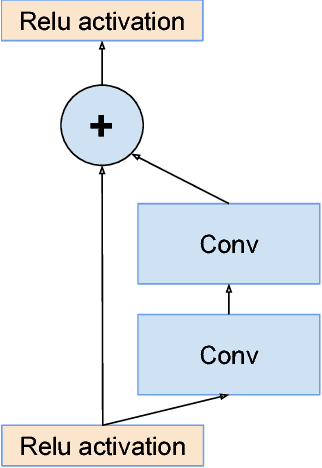
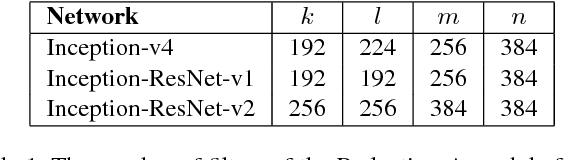
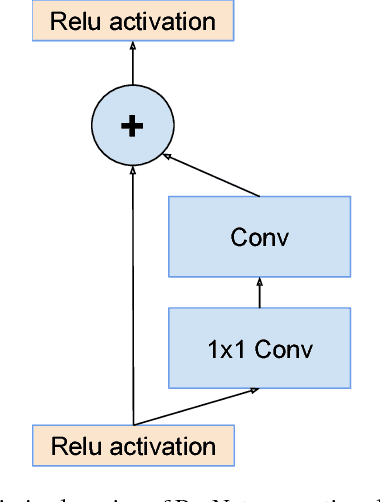

Very deep convolutional networks have been central to the largest advances in image recognition performance in recent years. One example is the Inception architecture that has been shown to achieve very good performance at relatively low computational cost. Recently, the introduction of residual connections in conjunction with a more traditional architecture has yielded state-of-the-art performance in the 2015 ILSVRC challenge; its performance was similar to the latest generation Inception-v3 network. This raises the question of whether there are any benefit in combining the Inception architecture with residual connections. Here we give clear empirical evidence that training with residual connections accelerates the training of Inception networks significantly. There is also some evidence of residual Inception networks outperforming similarly expensive Inception networks without residual connections by a thin margin. We also present several new streamlined architectures for both residual and non-residual Inception networks. These variations improve the single-frame recognition performance on the ILSVRC 2012 classification task significantly. We further demonstrate how proper activation scaling stabilizes the training of very wide residual Inception networks. With an ensemble of three residual and one Inception-v4, we achieve 3.08 percent top-5 error on the test set of the ImageNet classification (CLS) challenge
Rethinking the Inception Architecture for Computer Vision
Dec 11, 2015
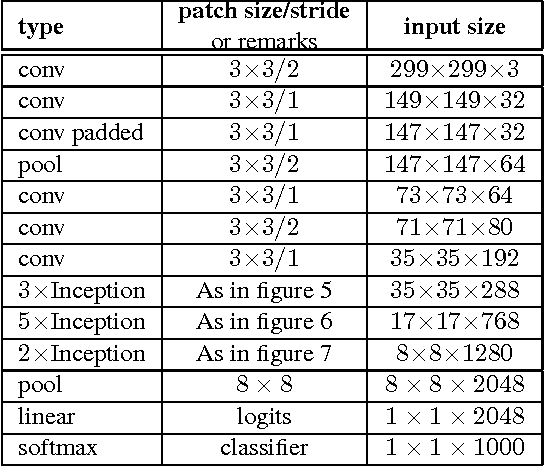
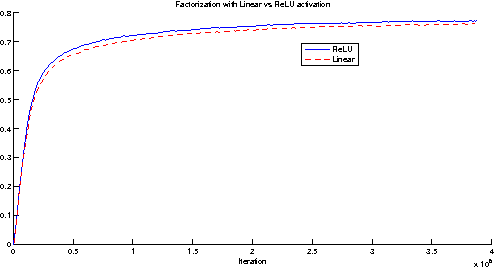
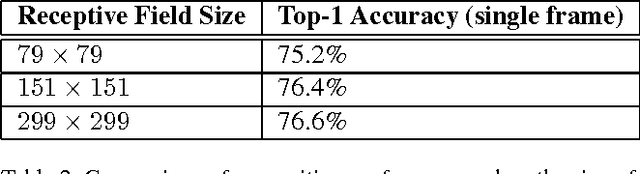
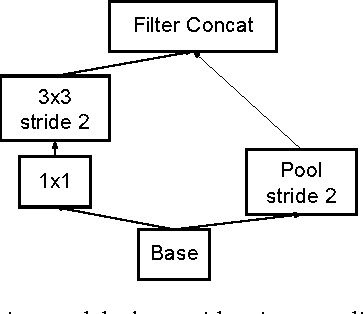
Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks. Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks. Although increased model size and computational cost tend to translate to immediate quality gains for most tasks (as long as enough labeled data is provided for training), computational efficiency and low parameter count are still enabling factors for various use cases such as mobile vision and big-data scenarios. Here we explore ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error on the validation set (3.6% error on the test set) and 17.3% top-1 error on the validation set.
Scalable, High-Quality Object Detection
Dec 09, 2015
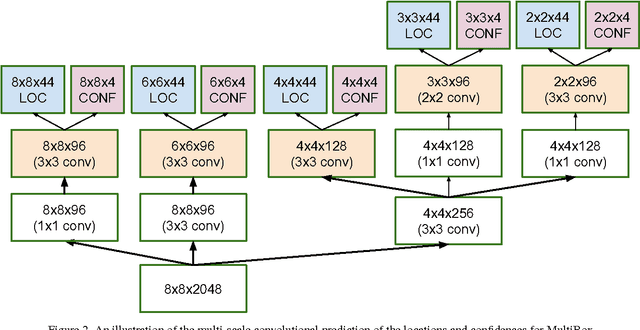

Current high-quality object detection approaches use the scheme of salience-based object proposal methods followed by post-classification using deep convolutional features. This spurred recent research in improving object proposal methods. However, domain agnostic proposal generation has the principal drawback that the proposals come unranked or with very weak ranking, making it hard to trade-off quality for running time. This raises the more fundamental question of whether high-quality proposal generation requires careful engineering or can be derived just from data alone. We demonstrate that learning-based proposal methods can effectively match the performance of hand-engineered methods while allowing for very efficient runtime-quality trade-offs. Using the multi-scale convolutional MultiBox (MSC-MultiBox) approach, we substantially advance the state-of-the-art on the ILSVRC 2014 detection challenge data set, with $0.5$ mAP for a single model and $0.52$ mAP for an ensemble of two models. MSC-Multibox significantly improves the proposal quality over its predecessor MultiBox~method: AP increases from $0.42$ to $0.53$ for the ILSVRC detection challenge. Finally, we demonstrate improved bounding-box recall compared to Multiscale Combinatorial Grouping with less proposals on the Microsoft-COCO data set.
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Mar 02, 2015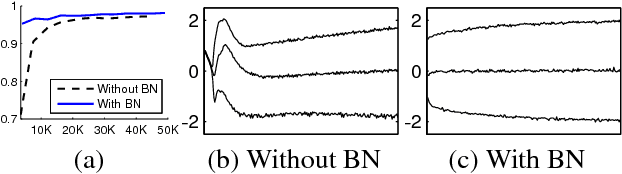
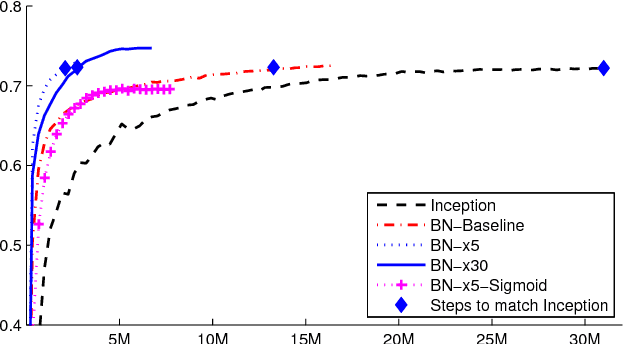


Training Deep Neural Networks is complicated by the fact that the distribution of each layer's inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities. We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs. Our method draws its strength from making normalization a part of the model architecture and performing the normalization for each training mini-batch. Batch Normalization allows us to use much higher learning rates and be less careful about initialization. It also acts as a regularizer, in some cases eliminating the need for Dropout. Applied to a state-of-the-art image classification model, Batch Normalization achieves the same accuracy with 14 times fewer training steps, and beats the original model by a significant margin. Using an ensemble of batch-normalized networks, we improve upon the best published result on ImageNet classification: reaching 4.9% top-5 validation error (and 4.8% test error), exceeding the accuracy of human raters.
Deep Convolutional Ranking for Multilabel Image Annotation
Apr 14, 2014


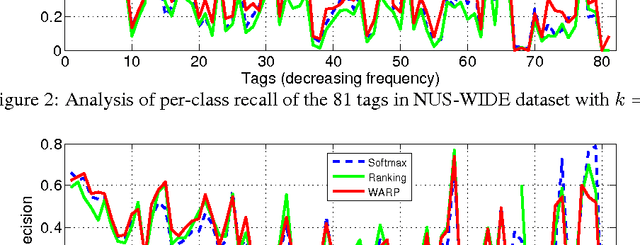
Multilabel image annotation is one of the most important challenges in computer vision with many real-world applications. While existing work usually use conventional visual features for multilabel annotation, features based on Deep Neural Networks have shown potential to significantly boost performance. In this work, we propose to leverage the advantage of such features and analyze key components that lead to better performances. Specifically, we show that a significant performance gain could be obtained by combining convolutional architectures with approximate top-$k$ ranking objectives, as thye naturally fit the multilabel tagging problem. Our experiments on the NUS-WIDE dataset outperforms the conventional visual features by about 10%, obtaining the best reported performance in the literature.