 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Binary Embedding using Circulant Matrices
Dec 05, 2015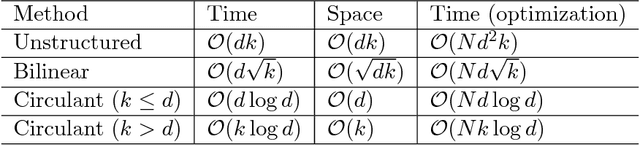
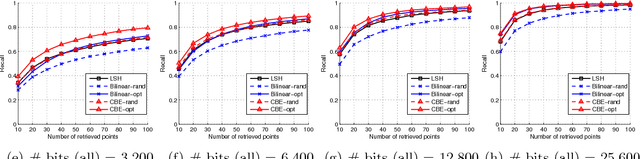
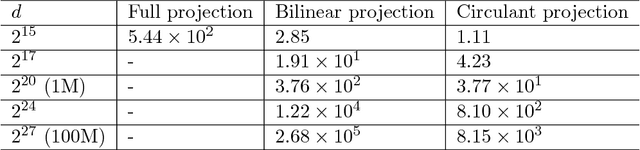
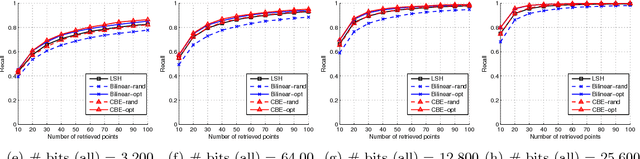
Binary embeddings provide efficient and powerful ways to perform operations on large scale data. However binary embedding typically requires long codes in order to preserve the discriminative power of the input space. Thus binary coding methods traditionally suffer from high computation and storage costs in such a scenario. To address this problem, we propose Circulant Binary Embedding (CBE) which generates binary codes by projecting the data with a circulant matrix. The circulant structure allows us to use Fast Fourier Transform algorithms to speed up the computation. For obtaining $k$-bit binary codes from $d$-dimensional data, this improves the time complexity from $O(dk)$ to $O(d\log{d})$, and the space complexity from $O(dk)$ to $O(d)$. We study two settings, which differ in the way we choose the parameters of the circulant matrix. In the first, the parameters are chosen randomly and in the second, the parameters are learned using the data. For randomized CBE, we give a theoretical analysis comparing it with binary embedding using an unstructured random projection matrix. The challenge here is to show that the dependencies in the entries of the circulant matrix do not lead to a loss in performance. In the second setting, we design a novel time-frequency alternating optimization to learn data-dependent circulant projections, which alternatively minimizes the objective in original and Fourier domains. In both the settings, we show by extensive experiments that the CBE approach gives much better performance than the state-of-the-art approaches if we fix a running time, and provides much faster computation with negligible performance degradation if we fix the number of bits in the embedding.
Compressing Deep Convolutional Networks using Vector Quantization
Dec 18, 2014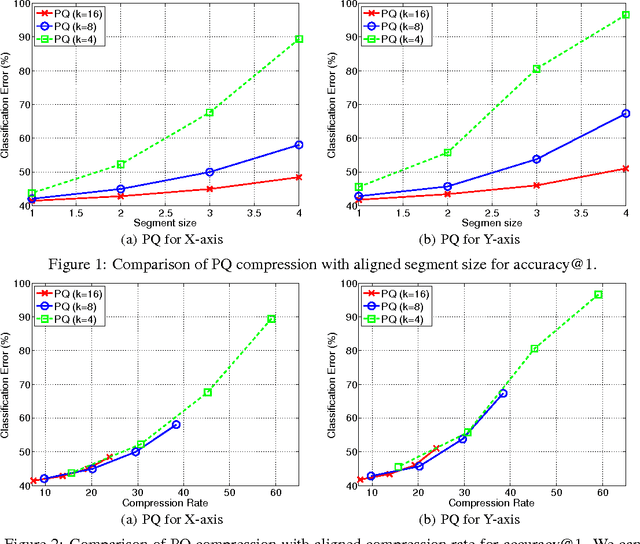
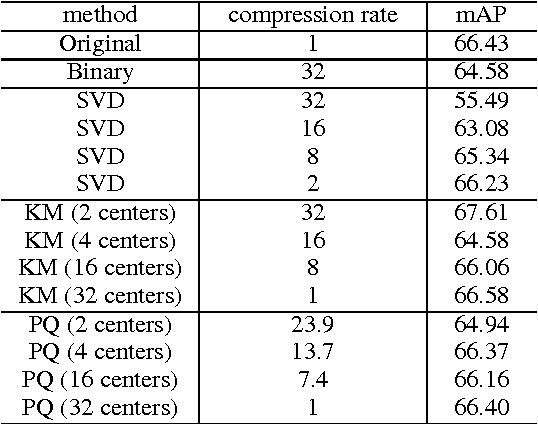
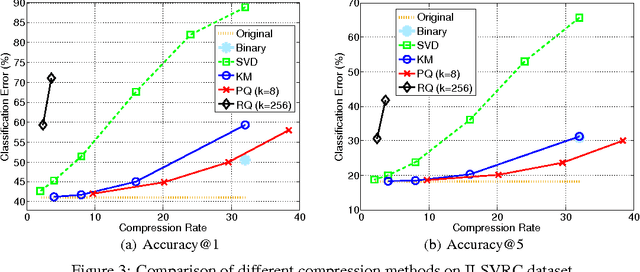
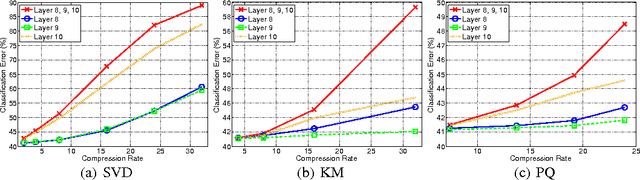
Deep convolutional neural networks (CNN) has become the most promising method for object recognition, repeatedly demonstrating record breaking results for image classification and object detection in recent years. However, a very deep CNN generally involves many layers with millions of parameters, making the storage of the network model to be extremely large. This prohibits the usage of deep CNNs on resource limited hardware, especially cell phones or other embedded devices. In this paper, we tackle this model storage issue by investigating information theoretical vector quantization methods for compressing the parameters of CNNs. In particular, we have found in terms of compressing the most storage demanding dense connected layers, vector quantization methods have a clear gain over existing matrix factorization methods. Simply applying k-means clustering to the weights or conducting product quantization can lead to a very good balance between model size and recognition accuracy. For the 1000-category classification task in the ImageNet challenge, we are able to achieve 16-24 times compression of the network with only 1% loss of classification accuracy using the state-of-the-art CNN.
Multi-scale Orderless Pooling of Deep Convolutional Activation Features
Sep 08, 2014



Deep convolutional neural networks (CNN) have shown their promise as a universal representation for recognition. However, global CNN activations lack geometric invariance, which limits their robustness for classification and matching of highly variable scenes. To improve the invariance of CNN activations without degrading their discriminative power, this paper presents a simple but effective scheme called multi-scale orderless pooling (MOP-CNN). This scheme extracts CNN activations for local patches at multiple scale levels, performs orderless VLAD pooling of these activations at each level separately, and concatenates the result. The resulting MOP-CNN representation can be used as a generic feature for either supervised or unsupervised recognition tasks, from image classification to instance-level retrieval; it consistently outperforms global CNN activations without requiring any joint training of prediction layers for a particular target dataset. In absolute terms, it achieves state-of-the-art results on the challenging SUN397 and MIT Indoor Scenes classification datasets, and competitive results on ILSVRC2012/2013 classification and INRIA Holidays retrieval datasets.
Circulant Binary Embedding
May 13, 2014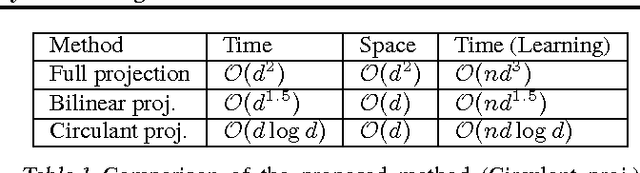
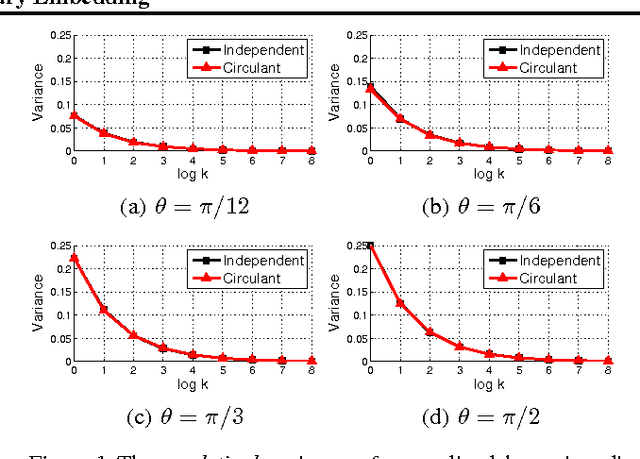
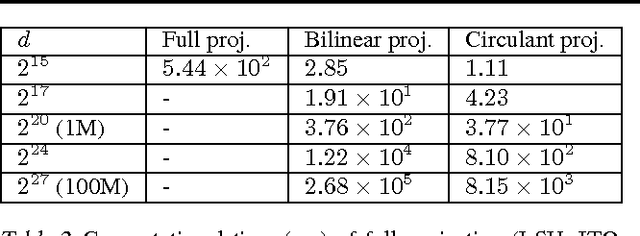
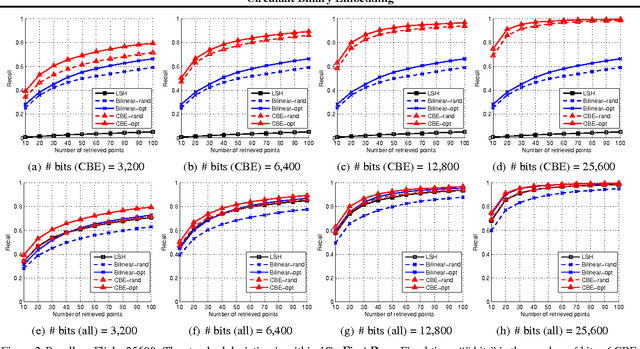
Binary embedding of high-dimensional data requires long codes to preserve the discriminative power of the input space. Traditional binary coding methods often suffer from very high computation and storage costs in such a scenario. To address this problem, we propose Circulant Binary Embedding (CBE) which generates binary codes by projecting the data with a circulant matrix. The circulant structure enables the use of Fast Fourier Transformation to speed up the computation. Compared to methods that use unstructured matrices, the proposed method improves the time complexity from $\mathcal{O}(d^2)$ to $\mathcal{O}(d\log{d})$, and the space complexity from $\mathcal{O}(d^2)$ to $\mathcal{O}(d)$ where $d$ is the input dimensionality. We also propose a novel time-frequency alternating optimization to learn data-dependent circulant projections, which alternatively minimizes the objective in original and Fourier domains. We show by extensive experiments that the proposed approach gives much better performance than the state-of-the-art approaches for fixed time, and provides much faster computation with no performance degradation for fixed number of bits.
Deep Convolutional Ranking for Multilabel Image Annotation
Apr 14, 2014


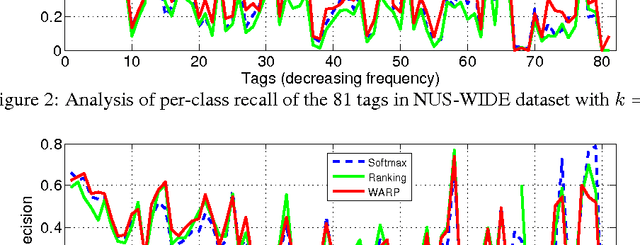
Multilabel image annotation is one of the most important challenges in computer vision with many real-world applications. While existing work usually use conventional visual features for multilabel annotation, features based on Deep Neural Networks have shown potential to significantly boost performance. In this work, we propose to leverage the advantage of such features and analyze key components that lead to better performances. Specifically, we show that a significant performance gain could be obtained by combining convolutional architectures with approximate top-$k$ ranking objectives, as thye naturally fit the multilabel tagging problem. Our experiments on the NUS-WIDE dataset outperforms the conventional visual features by about 10%, obtaining the best reported performance in the literature.
A Multi-View Embedding Space for Modeling Internet Images, Tags, and their Semantics
Sep 02, 2013


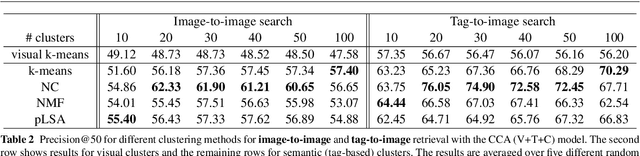
This paper investigates the problem of modeling Internet images and associated text or tags for tasks such as image-to-image search, tag-to-image search, and image-to-tag search (image annotation). We start with canonical correlation analysis (CCA), a popular and successful approach for mapping visual and textual features to the same latent space, and incorporate a third view capturing high-level image semantics, represented either by a single category or multiple non-mutually-exclusive concepts. We present two ways to train the three-view embedding: supervised, with the third view coming from ground-truth labels or search keywords; and unsupervised, with semantic themes automatically obtained by clustering the tags. To ensure high accuracy for retrieval tasks while keeping the learning process scalable, we combine multiple strong visual features and use explicit nonlinear kernel mappings to efficiently approximate kernel CCA. To perform retrieval, we use a specially designed similarity function in the embedded space, which substantially outperforms the Euclidean distance. The resulting system produces compelling qualitative results and outperforms a number of two-view baselines on retrieval tasks on three large-scale Internet image datasets.