 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Deep Convolutional Networks using Vector Quantization
Paper and Code
Dec 18, 2014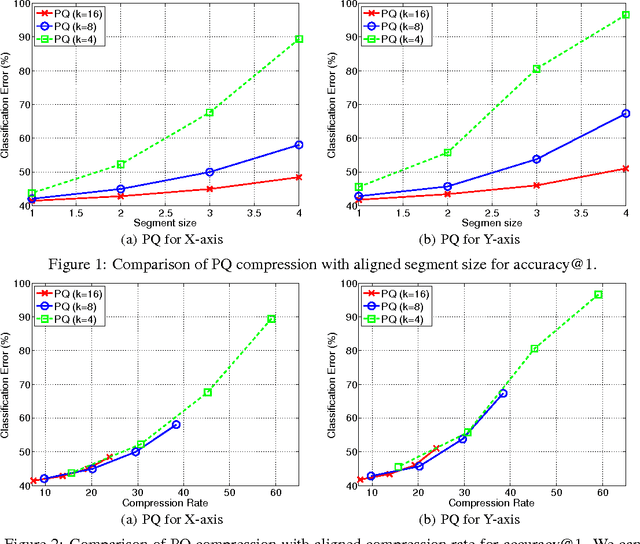
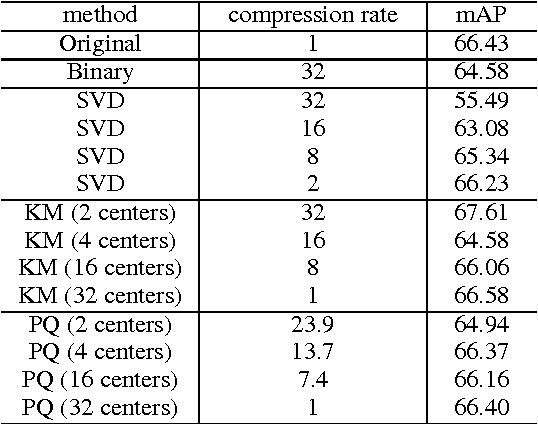
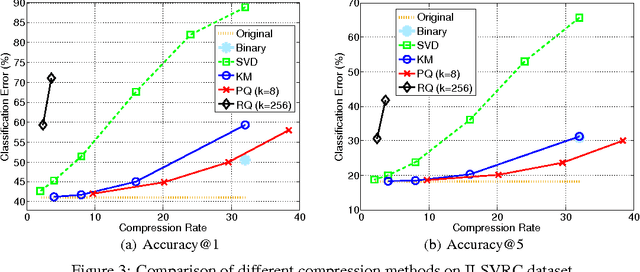
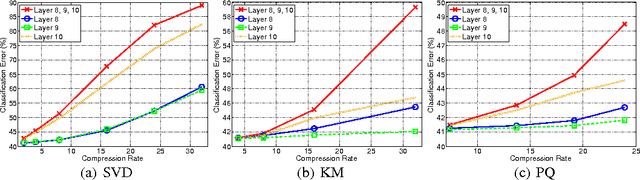
Deep convolutional neural networks (CNN) has become the most promising method for object recognition, repeatedly demonstrating record breaking results for image classification and object detection in recent years. However, a very deep CNN generally involves many layers with millions of parameters, making the storage of the network model to be extremely large. This prohibits the usage of deep CNNs on resource limited hardware, especially cell phones or other embedded devices. In this paper, we tackle this model storage issue by investigating information theoretical vector quantization methods for compressing the parameters of CNNs. In particular, we have found in terms of compressing the most storage demanding dense connected layers, vector quantization methods have a clear gain over existing matrix factorization methods. Simply applying k-means clustering to the weights or conducting product quantization can lead to a very good balance between model size and recognition accuracy. For the 1000-category classification task in the ImageNet challenge, we are able to achieve 16-24 times compression of the network with only 1% loss of classification accuracy using the state-of-the-art CNN.